
🆕 Updated June 9: Claude Fable 5 released — 80.3% SWE-bench Pro, 88.0% Terminal-Bench 2.1, 85.0% OSWorld-Verified, 94.5% GPQA Diamond, 56.8% HLE no tools. The first Mythos-class model available to everyone — and the new #1 for Unreal C++, Unity C#, Godot, Roblox, shaders, and physics. Here's the definitive game dev model guide. See full leaderboard →
🆕 Claude Fable 5 — Game Dev Powerhouse
80.3% SWE-bench Pro (Unity C# + Godot GDScript), 88.0% Terminal-Bench 2.1 (Unreal C++ build systems), 85.0% OSWorld-Verified (engine UI interaction), 94.5% GPQA Diamond (physics/rendering math), 56.8% HLE no tools (shader math + complex reasoning). Fable 5 is the most well-rounded game dev model ever released. $10/$50 per 1M tokens.
Here's a problem no one talks about: there is no AI benchmark for game development. Every coding benchmark tests web frameworks, CLI tools, or competitive programming. None of them test whether a model can write a Unity MonoBehaviour, debug an Unreal Engine build, or optimize a GLSL shader. But that doesn't mean we're flying blind. We can map every game development task to the closest proxy benchmark — and the results reveal which models actually serve game developers best.
📊 Key Findings
- Claude Fable 5 is #1 across every game dev dimension. 80.3% Pro, 88.0% Terminal-Bench, 85.0% OSWorld, 94.5% GPQA. For Unreal C++, Unity C#, Godot, Roblox, shaders, and physics — Fable 5 is the most capable game dev model ever released.
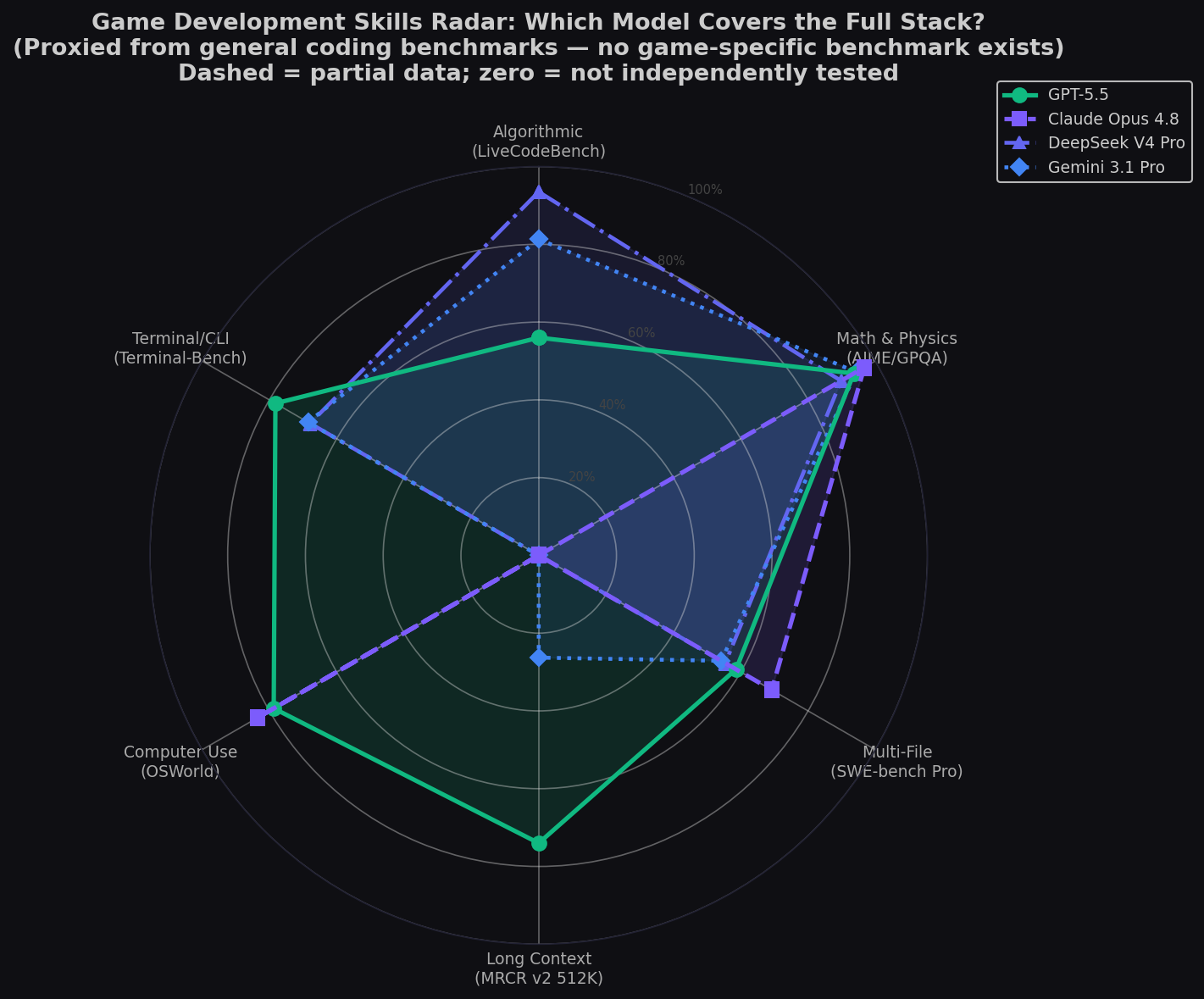
- GPT-5.5 is the budget Unreal alternative. 83.4% Terminal-Bench at $5/$30 per 1M. Cost-effective for high-volume build system work.
- DeepSeek V4 Pro is the algorithmic secret weapon. 93.5% LiveCodeBench, 3206 Codeforces, $0.87/1M, MIT. For pathfinding, procedural generation, physics optimization, and shader math.
- No model is "good" at shader programming yet. SciCode tops out at 26.2%. GPU programming is the hardest unsolved coding domain for AI.
All models analyzed here are available on CodingFleet. Test them on your game code →
The Problem: There's No Game Dev Benchmark
Let's be honest upfront. Every coding benchmark in 2026 tests one of three things: fixing bugs in Python web frameworks (SWE-bench), solving algorithmic puzzles (LiveCodeBench, Codeforces), or running terminal commands (Terminal-Bench). None of them ask a model to:
- Write a Unity C# MonoBehaviour with proper serialization and Editor integration
- Debug an Unreal Engine C++ build failure caused by missing module dependencies
- Optimize a GLSL fragment shader from 12ms to under 2ms on mobile
- Implement A* pathfinding in GDScript that avoids NavMesh obstacles
- Script a Roblox Luau module for server-authoritative hit detection
These are the actual tasks game developers face. And the benchmarks we have can only approximate them. Here's the mapping:
| Game Dev Task | Engine / Language | Best Proxy Benchmark | What It Tests |
|---|---|---|---|
| Gameplay systems, build pipelines | Unreal (C++) | Terminal-Bench 2.1 | CLI workflows, compilation, toolchains |
| Component architecture, editor scripting | Unity (C#) | SWE-bench Pro | Multi-file refactoring, ORM-like patterns |
| Game logic, rapid prototyping | Godot (GDScript) | SWE-bench Pro | Python-like multi-file reasoning |
| Game scripting, modding | Roblox (Luau) | SWE-bench Multilingual | Cross-language code understanding |
| Shader programming | GLSL / HLSL | SciCode + AIME | Math-heavy scientific computing |
| Pathfinding, AI behavior trees | All engines | LiveCodeBench | Algorithmic problem-solving |
| Physics, rendering math | All engines | GPQA Diamond + AIME | PhD-level math & physics reasoning |
| Engine UI interaction | Unity, Unreal Editor | OSWorld-Verified | Computer use, GUI navigation |
The Game Development Skills Radar
The Cost of Game Dev AI
| Model | Output $/1M | Best For | Monthly Cost (100K tok/day) |
|---|---|---|---|
| Claude Fable 5 | $50.00 | All engines, premium quality | $150.00 |
| Claude Opus 4.8 | $25.00 | Unity C#, Godot, Roblox scripting | $75.00 |
| GPT-5.5 | $30.00 | Unreal Engine, terminal workflows | $90.00 |
| DeepSeek V4 Pro | $0.87 | Shaders, algorithms, open-weight | $2.61 |
Which Model for Which Game Engine?
| Engine / Task | Primary Language | Best Model | Budget Alternative |
|---|---|---|---|
| Unreal Engine 5 | C++ | Claude Fable 5 | GPT-5.5 ($30) |
| Unity 6 | C# | Claude Fable 5 | Claude Opus 4.8 ($25) |
| Godot 4 | GDScript / C# | Claude Fable 5 | Claude Opus 4.8 ($25) |
| Roblox Studio | Luau | Claude Fable 5 | Claude Opus 4.8 ($25) |
| Shader programming | GLSL / HLSL | Claude Fable 5 | DeepSeek V4 Pro ($0.87) |
| Physics systems | C++ / C# | Claude Fable 5 | Claude Opus 4.8 ($25) |
| AI behavior trees / pathfinding | All | DeepSeek V4 Pro | DeepSeek V4 Flash ($0.28) |
| Indie dev on a budget | All | DeepSeek V4 Pro ($0.87) | DeepSeek V4 Flash ($0.28) |
The Bottom Line
- Claude Fable 5 is the most well-rounded game dev model ever. 80.3% Pro, 88.0% Terminal-Bench, 85.0% OSWorld, 94.5% GPQA — it leads every proxy benchmark that maps to game development.
- DeepSeek V4 Pro is the algorithmic secret weapon. 93.5% LiveCodeBench, 3206 Codeforces, MIT-licensed, $0.87/1M output. For pathfinding, procedural generation, physics optimization.
- Shader programming is the unsolved frontier. SciCode at 26.2% means the best AI fails 3 out of 4 scientific computing tasks. Shaders are harder.
Game development is the most demanding use case for AI coding — it requires math, multi-file architecture, terminal workflows, algorithmic thinking, and long-context navigation. Fable 5 covers more of those dimensions than any model before it.