
The Battle for Best Value in AI Coding
Two models dominate the "best bang for buck" conversation in mid-2026: Anthropic's Claude Sonnet 4.6 (February 2026) and Google's Gemini 3.5 Flash (May 2026). Sonnet delivers near-Opus coding performance at 1/5 the price. Gemini 3.5 Flash brings frontier-level agentic benchmarks at Flash-tier pricing. Which one should you build on?
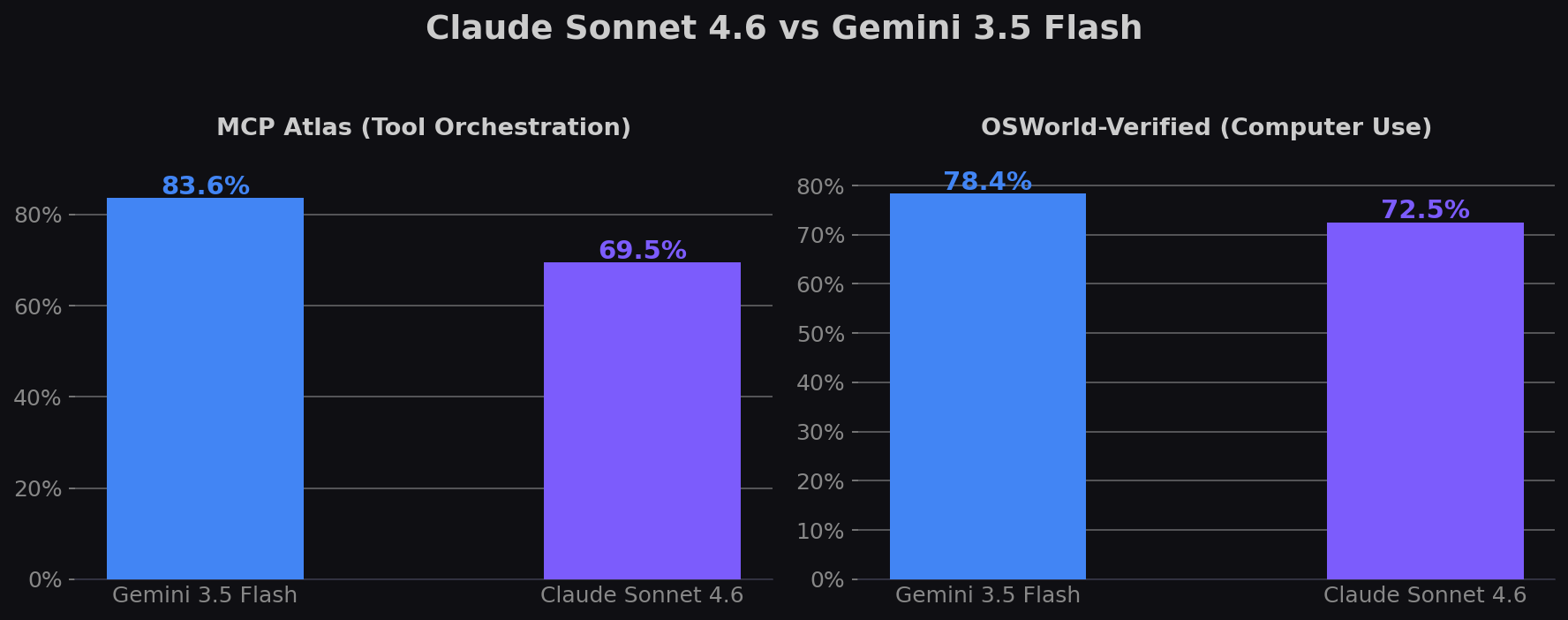
TL;DR: Sonnet 4.6 leads on GDPval-AA knowledge work (1676 vs 1656 Elo). Gemini 3.5 Flash leads on Terminal-Bench (76.2% vs 59.1%), MCP Atlas (83.6% vs 69.5%), and OSWorld (78.4% vs 72.5%). Gemini is 40% cheaper on output ($9 vs $15). On SWE-bench Pro — the recommended benchmark now that Verified is contaminated — neither has published scores, but Gemini 3.5 Flash scores 55.1% which is competitive with GPT-5.4 (57.7%).
Try both models on CodingFleet: Start a new chat → and pick your model.
Benchmark Comparison
Note: SWE-bench Verified is considered contaminated by OpenAI (February 2026) — all frontier models showed memorization. SWE-bench Pro is the recommended alternative.
| Benchmark | Claude Sonnet 4.6 | Gemini 3.5 Flash | Winner |
|---|---|---|---|
| SWE-bench Pro ★ | — | 55.1% | Gemini 3.5 Flash |
| SWE-bench Verified ⚠️ | 77.4% | 78.8% | Gemini (contaminated) |
| Terminal-Bench 2.1 | 59.1% | 76.2% | Gemini 3.5 Flash |
| OSWorld-Verified | 72.5% | 78.4% | Gemini 3.5 Flash |
| MCP Atlas (tool orchestration) | 69.5% | 83.6% | Gemini 3.5 Flash |
| GDPval-AA (Elo) | 1676 | 1656 | Sonnet 4.6 |
| MMMU-Pro (multimodal) | 74.5% | 83.6% | Gemini 3.5 Flash |
| HumanEval | 92.1% | — | Sonnet 4.6 |
Pricing & Specs
| Spec | Claude Sonnet 4.6 | Gemini 3.5 Flash |
|---|---|---|
| Input (per 1M tokens) | $3.00 | $1.50 |
| Output (per 1M tokens) | $15.00 | $9.00 |
| Context window | 1M (optional) | 1M |
| Multimodal | Text + vision | Text + vision + audio + video |
| Computer Use | Native (OSWorld 72.5%) | Native (OSWorld 78.4%) |
| Ecosystem | Claude Code, MCP native | Gemini API, Vertex AI |
Which One Should You Use?
| Use Case | Better Model |
|---|---|
| Agentic coding in Claude Code ecosystem | Sonnet 4.6 — near-Opus knowledge work, proven ecosystem |
| Terminal/CLI agentic coding | Gemini 3.5 Flash — 76.2% Terminal-Bench vs 59.1% |
| Multi-tool MCP orchestration | Gemini 3.5 Flash — 83.6% MCP Atlas vs 69.5% |
| Computer-use / browser automation | Gemini 3.5 Flash — 78.4% OSWorld vs 72.5% |
| Cost-sensitive production at scale | Gemini 3.5 Flash — 40% cheaper output, 50% cheaper input |
| Long-context work + knowledge tasks | Sonnet 4.6 — 1676 GDPval-AA, 1M context |
Conclusion
Claude Sonnet 4.6 excels at knowledge work — GDPval-AA and HumanEval show its strength in reasoning and code generation. Gemini 3.5 Flash is the agentic powerhouse — leading on every agentic benchmark (Terminal-Bench, MCP Atlas, OSWorld) at 40% lower cost. For Claude Code loyalists doing knowledge-heavy work, Sonnet remains the default. For teams building agentic pipelines that need tool orchestration and computer use, Gemini 3.5 Flash delivers more capability per dollar.