
Every frontier model now claims a 1-million-token context window. It's the headline spec: GPT-5.5 — 1M. Claude Opus 4.7 — 1M. Gemini 3.1 Pro — 1M. DeepSeek V4 Pro — 1M. But here's what the marketing doesn't tell you: claiming 1M and actually using it are completely different things. On the most rigorous test — MRCR v2 8-needle at 1M tokens — the gap between the best and worst performers is over 60 percentage points. We analyzed every available long-context benchmark to answer one question: when you load a million tokens into a model, what does it actually see?
📊 Key Findings
- GPT-5.5 dominates long context. 74.0% on MRCR v2 at 512K–1M — more than double GPT-5.4 (36.6%) and Opus 4.7 (32.2%). A 37-point generational leap from OpenAI.
- Claude Opus 4.6 is the reliability champion. 76% MRCR v2 at 1M — the single best score at full context length. But Opus 4.7 regressed to 32.2% in a deliberate tradeoff for honesty.
- The effective context floor is 50%. Industry research shows models reliably use only 50–65% of their advertised context. At 1M, that means 500–650K of actual usable tokens.
- Single-needle tests are misleading. GPT-5.5 hits 96% and Gemini 3 hits 99% on single-needle at 1M. But with 8 needles — a realistic scenario — scores drop to 74% and 89% respectively. DeepSeek V4 Pro collapses to 41%.
- No model is safe above 500K. Every model degrades significantly past 500K tokens. The "context rot zone" begins around 512K for all current architectures.
All models analyzed here are available on CodingFleet. Test them with your own long-context workloads →
The Tests: What We Actually Measured
Not all long-context benchmarks are created equal. Here are the four tests that matter — and why most "1M capable" claims are based on the weakest one:
| Benchmark | Difficulty | What It Tests | Real-World Analog |
|---|---|---|---|
| NIAH-2 (Single Needle) | Easy | Find one specific fact buried in long text | Ctrl+F in a document |
| NIAH-2 (8 Needles) | Medium | Find 8 related facts and distinguish them | Research across multiple sections of a codebase |
| MRCR v2 (8-Needle) | Hard | Retrieve a specific iteration among 8 identical-looking items across the full context | Finding version 4 of a function among 8 similar commits in a 500K-line PR review |
| Graphwalks (BFS/Parents) | Very Hard | Multi-hop reasoning: follow a chain of facts across the entire context | Tracing a bug through multiple files across an entire monorepo |
MRCR v2 is the gold standard. Developed by OpenAI and fixed in December 2025, it injects 8 identical "needles" (e.g., 8 poems on the same topic) and asks the model to retrieve a specific one ("give me the 4th poem"). This tests not just retrieval, but entity distinction and sequential reasoning — exactly what you need when analyzing a codebase where the same function name appears in multiple files. Single-needle NIAH, by contrast, is essentially a search bar test.
The MRCR v2 Degradation Curve: Where Models Break
This chart is the most important visual in long-context evaluation. It shows MRCR v2 8-needle accuracy as context grows from 4K to 1M tokens. The red zone marks where "context rot" sets in:
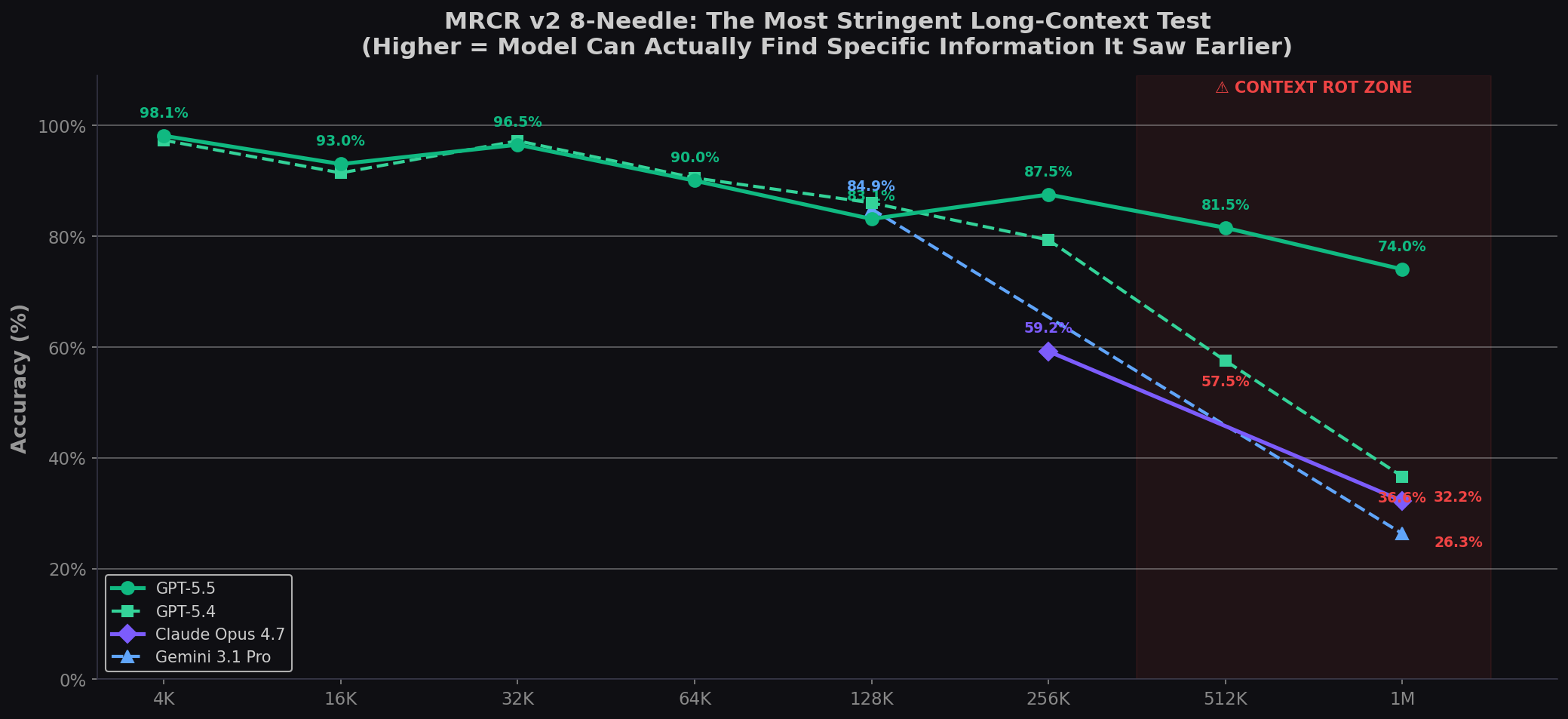
| Context Length | GPT-5.5 | GPT-5.4 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|
| 4K–8K | 98.1% | 97.3% | — | — |
| 8K–16K | 93.0% | 91.4% | — | — |
| 32K–64K | 90.0% | 90.5% | — | — |
| 64K–128K | 83.1% | 86.0% | — | — |
| 128K–256K | 87.5% | 79.3% | 59.2% | 84.9% |
| 256K–512K | 81.5% | 57.5% | — | — |
| 512K–1M | 74.0% | 36.6% | 32.2% | 26.3% |
Source: OpenAI GPT-5.5 announcement (MRCR v2 table). Claude Opus 4.7 and Gemini 3.1 Pro data points from OpenAI's published comparison.
Three things jump out:
- GPT-5.5 is in a different league. At 512K–1M, it scores 74.0% — double GPT-5.4 (36.6%) and Opus 4.7 (32.2%). OpenAI's 37-point generational jump on long-context is arguably GPT-5.5's most impressive achievement, even more than its coding gains.
- Claude Opus 4.7 took a deliberate step backward. Opus 4.6 scored 76% on MRCR v2 at 1M — the single best score ever recorded at full context length. Opus 4.7 dropped to 32.2%. Anthropic explicitly states this is because Opus 4.7 now refuses to answer when information is genuinely missing rather than fabricating. This is a calibration tradeoff, not a capability regression — but for long-context retrieval workloads, it hurts.
- Gemini 3.1 Pro is strong at 128K, then collapses. 84.9% at 128K–256K is competitive with GPT-5.5. But by 1M, it drops to 26.3% — the steepest cliff of any model.
The 1M Token Report Card: Five Benchmarks, One Question
Beyond MRCR v2, there are multiple ways to test long-context capability. Here's the full picture at 1M tokens across five different benchmarks:
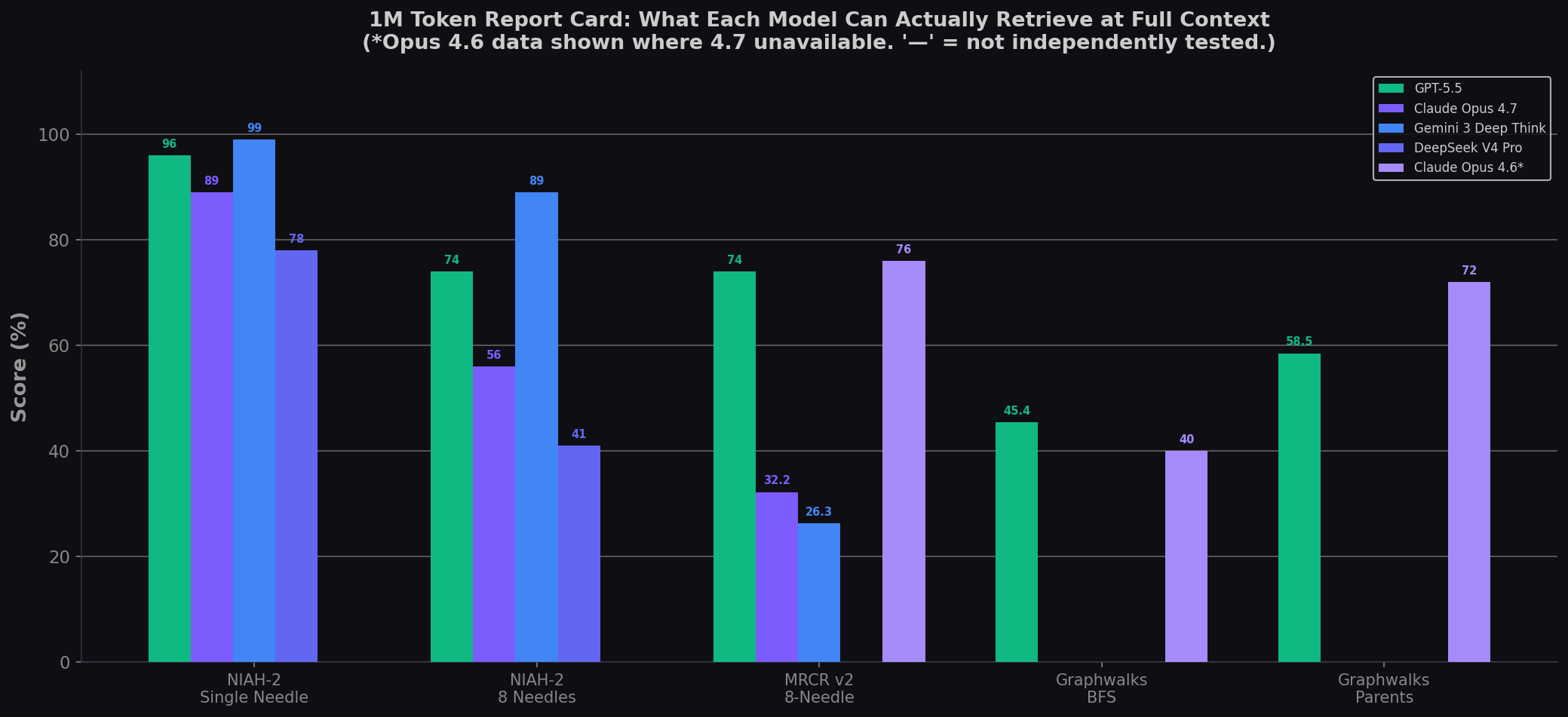
| Benchmark at 1M | GPT-5.5 | Claude Opus 4.7 | Gemini 3 Deep Think | DeepSeek V4 Pro | Best |
|---|---|---|---|---|---|
| NIAH-2 Single Needle | 96% | 89% | 99% | 78% | Gemini |
| NIAH-2 8 Needles | 74% | 56% | 89% | 41% | Gemini |
| MRCR v2 8-Needle | 74.0% | 32.2% | 26.3% | — | GPT-5.5* |
| Graphwalks BFS | 45.4% | ~40% (4.6) | — | — | GPT-5.5 |
| Graphwalks Parents | 58.5% | 72.0% (4.6) | — | — | Opus 4.6 |
* Claude Opus 4.6 scored 76% — the highest ever on MRCR v2 at 1M — but Opus 4.7 regressed to 32.2% for calibration reasons. Sources: OpenAI, Digital Applied NIAH-2 analysis, Anthropic Opus 4.6 system card analysis.
The pattern is clear: on simple retrieval (single needle), everyone looks good. Add more needles, and the field separates. Make those needles identical and require sequential reasoning (MRCR v2), and only GPT-5.5 and Claude Opus 4.6 remain viable. Add multi-hop reasoning (Graphwalks), and even the best models drop below 60% on several tasks.
The Context Window Lie: Claimed vs. Usable
Industry research from the Awesome Agents analysis finds that a model's effective context capacity is typically only 50–65% of its nominal value. Beyond that point, performance degradation becomes impossible to ignore. Here's what that means for each model:
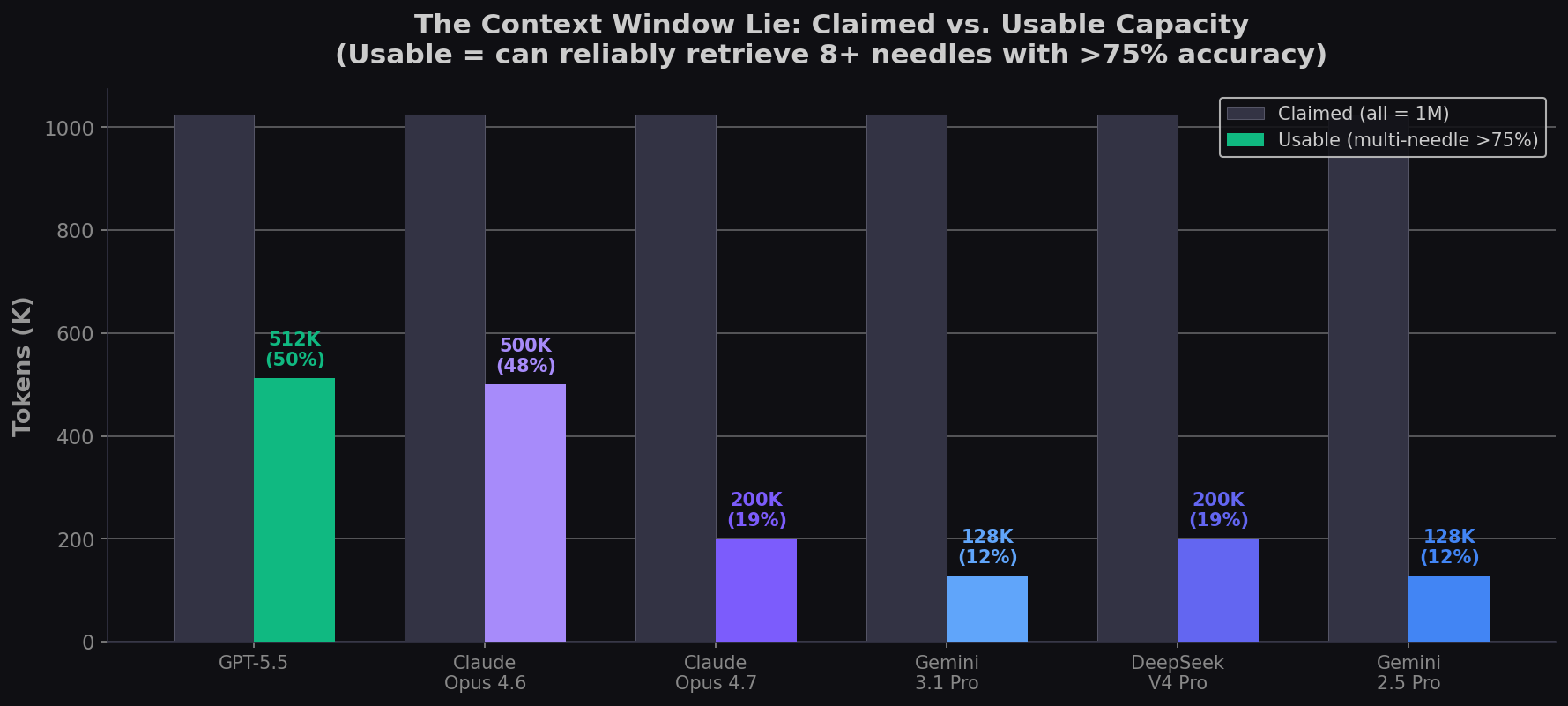
| Model | Claimed | Usable (multi-needle >75%) | % of Claim | Verdict |
|---|---|---|---|---|
| GPT-5.5 | 1M | ~512K | 50% | Best-in-class; usable to 500K |
| Claude Opus 4.6 | 1M | ~500K | 49% | Best raw 1M score (76%); but Opus 4.7 regressed |
| Claude Opus 4.7 | 1M | ~200K | 20% | Deliberate calibration tradeoff; honesty > retrieval |
| DeepSeek V4 Pro | 1M | ~200K | 20% | MLA architecture struggles at long range |
| Gemini 3.1 Pro | 1M | ~128K | 13% | Steepest cliff; strong to 128K, then collapses |
| Gemini 2.5 Pro | 1M | ~128K | 13% | Improved from Gemini 2.0 Flash (10.2% at 1M) |
Only GPT-5.5 and Claude Opus 4.6 provide usable context above 200K for multi-needle production workloads. For the other models, any content beyond ~128–200K is effectively unreliable without supplementary retrieval (RAG).
Why Models Break: The Three Failure Modes of Long Context
Context degradation isn't random. Research from Digital Applied and the NoLiMa benchmark identifies three mechanical failure modes that explain most of the drop between 200K and 1M:
1. Positional Bias
The classic "lost in the middle" pattern. Models attend more to the start and end of context than the middle. Needles placed at 30–70% depth show a 5–15 point retrieval drop.
Fix: Re-pack your prompt to put critical content at the start or end.
2. Attention-Sink Collapse
The model's attention mechanism latches onto repetitive tokens or padding, effectively "going blind" to the rest of the context. Common in code-heavy contexts with repeated syntax.
Fix: Use diverse content; avoid long runs of identical formatting.
3. MLA Long-Range Distortion
Specific to DeepSeek's Multi-Head Latent Attention — at long range, compressed key-value representations lose fidelity. This explains DeepSeek V4 Pro's 41% on multi-needle at 1M.
Fix: Use DeepSeek for <200K workloads where MLA excels.
NoLiMa: When Literal Matching Isn't Enough
Adobe Research's NoLiMa benchmark reveals an even deeper problem: standard needle-in-haystack tests let models cheat. When the needle shares keywords with the surrounding haystack, models exploit literal text matches. NoLiMa removes that crutch — needles and haystack have minimal lexical overlap, forcing genuine semantic retrieval.
The results are sobering. At just 32K tokens on NoLiMa, most models drop below 50% of their short-context baseline. GPT-4.1 — which claims a 1M context window — has an effective NoLiMa capacity of just 16K tokens. The benchmark authors conclude that the attention mechanism fundamentally struggles to retrieve information when literal matches are absent, even at modest context lengths.
The Architectural Deep Dive: Why GPT-5.5 Pulled Ahead
GPT-5.5's long-context dominance isn't magic — it's hardware. The model was co-designed with NVIDIA's GB200 and GB300 NVL72 systems. The hardware-software co-optimization specifically targeted attention at extreme context lengths. GPT-5.5 and Codex even rewrote OpenAI's own serving infrastructure, creating custom load-balancing heuristics that increased token generation speeds by 20%+ while maintaining long-context accuracy.
Meanwhile, DeepSeek V4 Pro's hybrid attention architecture (Compressed Sparse Attention + Heavily Compressed Attention) makes the 1M window feasible without prohibitive memory costs — but at a clear accuracy cost at long range. The tradeoff is economic: DeepSeek V4 Pro costs $3.48/1M output tokens vs GPT-5.5's $30. For workloads under 200K tokens, DeepSeek's architecture is cost-efficient. Above 200K, the accuracy degradation makes it a false economy.
What This Means for Developers
✅ DO
- Use GPT-5.5 for any workload exceeding 200K tokens — it's the only model that stays above 75% on MRCR v2 at 512K
- Use Claude Opus 4.6 if you need both long context and calibration (76% MRCR v2 at 1M with honest refusals)
- Use RAG chunking as a safety net above 128K on any model — even GPT-5.5 degrades past 500K
- Place critical instructions at the beginning or end of your prompt to avoid positional bias
- Test your specific workload — benchmarks are a compass, not a map
❌ DON'T
- Don't assume "1M context" means the model sees everything — most models have 50% effective capacity
- Don't use DeepSeek V4 Pro or Gemini 3.1 Pro above 200K without RAG — multi-needle collapses
- Don't rely on single-needle NIAH scores — they're misleading (Gemini 3: 99% single vs 26.3% MRCR v2 at 1M)
- Don't use Claude Opus 4.7 for pure long-context retrieval — the calibration tradeoff drops MRCR v2 to 32.2%
- Don't believe vendor benchmarks without independent verification — the December 2025 MRCR v2 fix exposed significant prior inflation
The Long-Context Timeline: How We Got Here
The 1M context window wasn't built overnight — and the reliability gap has a clear history:
| Date | Model | Context | MRCR v2 at 1M | Significance |
|---|---|---|---|---|
| Feb 2024 | Gemini 1.5 Pro | 1M (first!) | Not published | First to 1M; proved the concept |
| Jun 2025 | Gemini 2.5 Pro | 1M | 16.4% | Still struggling at full context |
| Nov 2025 | Gemini 3 Pro | 1M | 26.3% | Measurable improvement |
| Feb 2026 | Claude Opus 4.6 | 1M | 76.0% | Best 1M score; set the reliability bar |
| Feb 2026 | Gemini 3.1 Pro | 1M | 26.3% | Stagnated; strong at 128K though (84.9%) |
| Mar 2026 | GPT-5.4 | 1M | 36.6% | Step forward from GPT-5.2 (256K limited) |
| Apr 2026 | GPT-5.5 | 1M | 74.0% | 37-point leap; matches Opus 4.6's level |
| Apr 2026 | DeepSeek V4 Pro | 1M | Not published | 1M claimed but multi-needle at 1M = 41% |
The timeline reveals a clear pattern: getting to 1M took 2+ years (Gemini 1.5 Pro in 2024). Making 1M actually usable took until 2026 — and only two models have achieved it: Claude Opus 4.6 and GPT-5.5. The rest are still fighting the reliability war.
The Bottom Line
- "1M context" is a marketing term, not a capability guarantee. The gap between the best and worst "1M" model on the toughest test is 60+ percentage points. Check the specific benchmark before trusting the spec sheet.
- GPT-5.5 is the new long-context king. 74.0% on MRCR v2 at 512K–1M, 45.4% on Graphwalks BFS at 1M, and competitive single-needle scores. If your workload routinely exceeds 200K tokens, GPT-5.5 is the only safe choice among current-gen models.
- Claude Opus 4.6, not 4.7, is the Anthropic model for long context. Opus 4.7's calibration tradeoff (refusing rather than fabricating) is admirable for AI safety, but it drops MRCR v2 to 32.2%. For pure retrieval workloads, Opus 4.6 at 76% remains the single best score at 1M.
- Above 500K, no model is safe. Even GPT-5.5 drops from 81.5% at 256–512K to 74.0% at 512K–1M. The context rot zone is real. Supplement with RAG for the last 50% of any model's context window.
- The race has shifted from capacity to reliability. As the March 2026 Frontier analysis put it: "Stuffing a million tokens into a window is engineering. Getting the model to actually use what's buried at token 600,000 is science."
Context windows will keep growing. But the real question — the one benchmarks now answer — is not "how much can you load?" but "how much can the model actually see?"
Sources: OpenAI — Introducing GPT-5.5 (MRCR v2, Graphwalks tables) | Digital Applied — NIAH-2 Long-Context Analysis | Yage.ai — Long Context Benchmarks Survey (March 2026) | Anthropic Claude Opus 4.6 System Card Analysis | Adobe Research — NoLiMa Benchmark | Alex Lavaee — GPT-5.5 Honest Take. All scores are vendor-reported unless marked "independently tested." NIAH-2 scores from third-party Digital Applied analysis. Dashes indicate no published data at that context length for that model.