
Open Weights vs Proprietary: The Ultimate Value Question
Can an open-weight MIT-licensed model beat a proprietary flagship from OpenAI? DeepSeek V4 Pro Max (April 2026) makes the case that it can — and at a fraction of the price. Pitted against GPT-5.4 (March 2026), OpenAI's previous-generation workhorse, the comparison reveals how much the open-weight landscape has shifted.
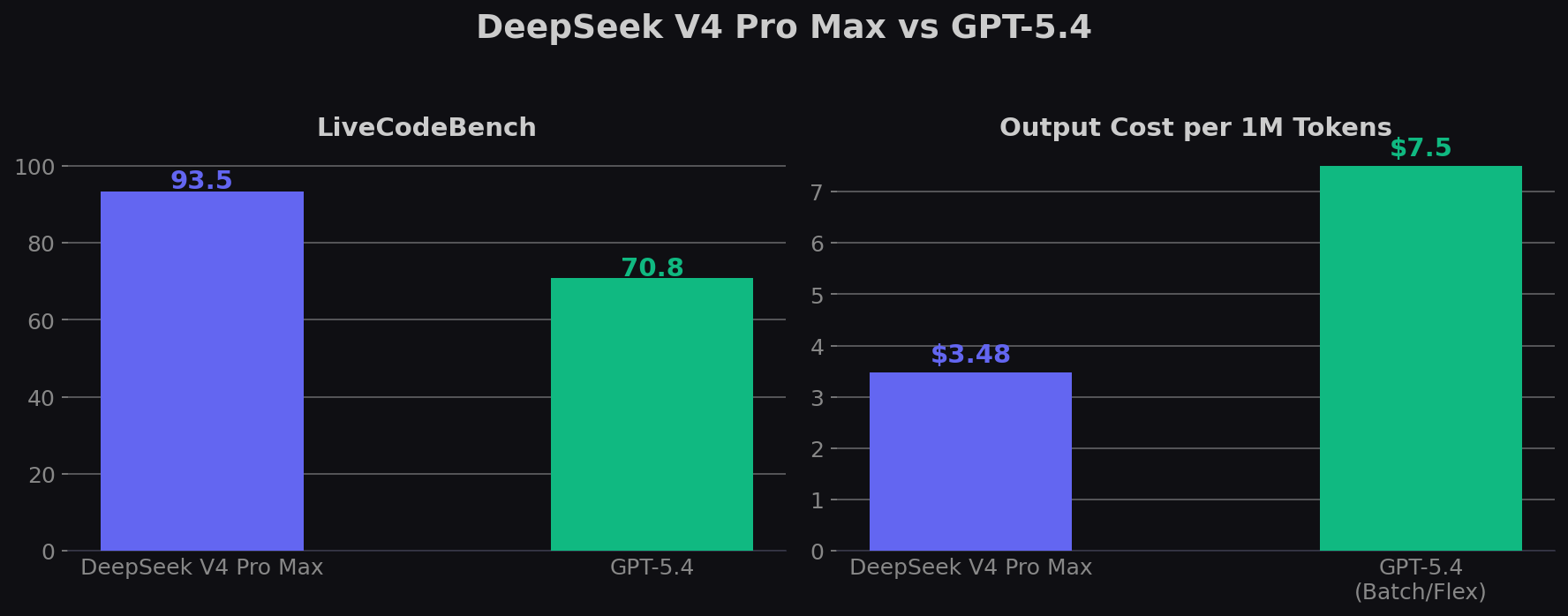
TL;DR: DeepSeek V4 Pro Max beats GPT-5.4 on LiveCodeBench (93.5% vs ~71%) and Codeforces (3206). GPT-5.4 wins on SWE-bench Pro (57.7% — the uncontaminated benchmark), Terminal-Bench (75.1% vs 67.9%), OSWorld computer use (75% vs none), and GPQA Diamond (92.8% vs 90.1%). DeepSeek is 4.3× cheaper on output ($3.48 vs $15) and MIT-licensed.
🔥 CodingFleet Unlimited Plan: Use DeepSeek V4 Pro without limits — no weekly, daily, or hourly quotas. Unlimited coding, unlimited chats, unlimited agentic tasks. Try it now →
Benchmark Comparison
Note: SWE-bench Verified is considered contaminated by OpenAI (February 2026). SWE-bench Pro ★ is the recommended benchmark. Verified scores shown only for historical context.
| Benchmark | DeepSeek V4 Pro Max | GPT-5.4 | Winner |
|---|---|---|---|
| SWE-bench Pro ★ | — | 57.7% | GPT-5.4 |
| SWE-bench Verified ⚠️ | 80.6% | 78.2% | DeepSeek (contaminated) |
| Terminal-Bench 2.0 | 67.9% | 75.1% | GPT-5.4 (+7.2) |
| OSWorld-Verified | — | 75.0% | GPT-5.4 |
| GPQA Diamond | 90.1% | 92.8% | GPT-5.4 |
| LiveCodeBench | 93.5% | ~70.8% | DeepSeek V4 |
| Codeforces Rating | 3206 | — | DeepSeek V4 |
| MCP Atlas | — | 70.6% | GPT-5.4 |
| HLE (academic reasoning) | — | 52.1% | GPT-5.4 |
Pricing & Architecture
| Spec | DeepSeek V4 Pro Max | GPT-5.4 |
|---|---|---|
| Input (per 1M tokens) | $1.74 | $2.50 |
| Output (per 1M tokens) | $3.48 | $15.00 |
| Batch/Flex output | $3.48 | $7.50 |
| Context window | 1M tokens | 1M+ tokens |
| Architecture | 1.6T MoE (49B active) | Proprietary |
| Computer Use | No | Native (OSWorld 75%) |
| License | MIT (open weights) | Proprietary |
| Max Output | 393K tokens | 128K tokens |
Which One Should You Use?
| Use Case | Better Model |
|---|---|
| SWE-bench Pro real-world bug fixing | GPT-5.4 — 57.7% on the uncontaminated benchmark |
| Terminal/CLI automation / DevOps | GPT-5.4 — 75.1% Terminal-Bench is a 7.2-point lead |
| Computer-use / browser agents | GPT-5.4 — native OSWorld at 75% |
| Competitive programming / algorithmic tasks | DeepSeek V4 Pro Max — 3206 Codeforces, 93.5% LiveCodeBench |
| Self-hosted / air-gapped deployment | DeepSeek V4 Pro Max — MIT-licensed, open weights |
| Cost-sensitive high-volume coding | DeepSeek V4 Pro Max — 4.3× cheaper output, better code-gen scores |
Conclusion
This comparison tells a nuanced story. On the uncontaminated SWE-bench Pro — the benchmark that actually matters — GPT-5.4 leads at 57.7%. It also dominates on terminal automation, computer use, and MCP tool orchestration. But DeepSeek V4 Pro Max counters with superior algorithmic coding (LiveCodeBench, Codeforces), a 4.3× price advantage, and MIT-licensed open weights you can self-host. The choice depends on your workflow: if you're building agentic pipelines with tool orchestration and computer use, GPT-5.4 is the pragmatic pick. If you need raw algorithmic coding power at minimal cost with the freedom to self-host, DeepSeek V4 Pro Max is transformative.