
The Open-Weight Heavyweight Championship
April 2026 saw two Chinese AI labs drop open-weight models that rival the proprietary frontier: DeepSeek's V4 Pro Max (April 24) and Moonshot AI's Kimi K2.6 (April 20). Both are MIT-licensed, both score above 80% on SWE-bench Verified, and both cost a fraction of GPT-5.5 or Opus 4.7. Here's the definitive comparison.
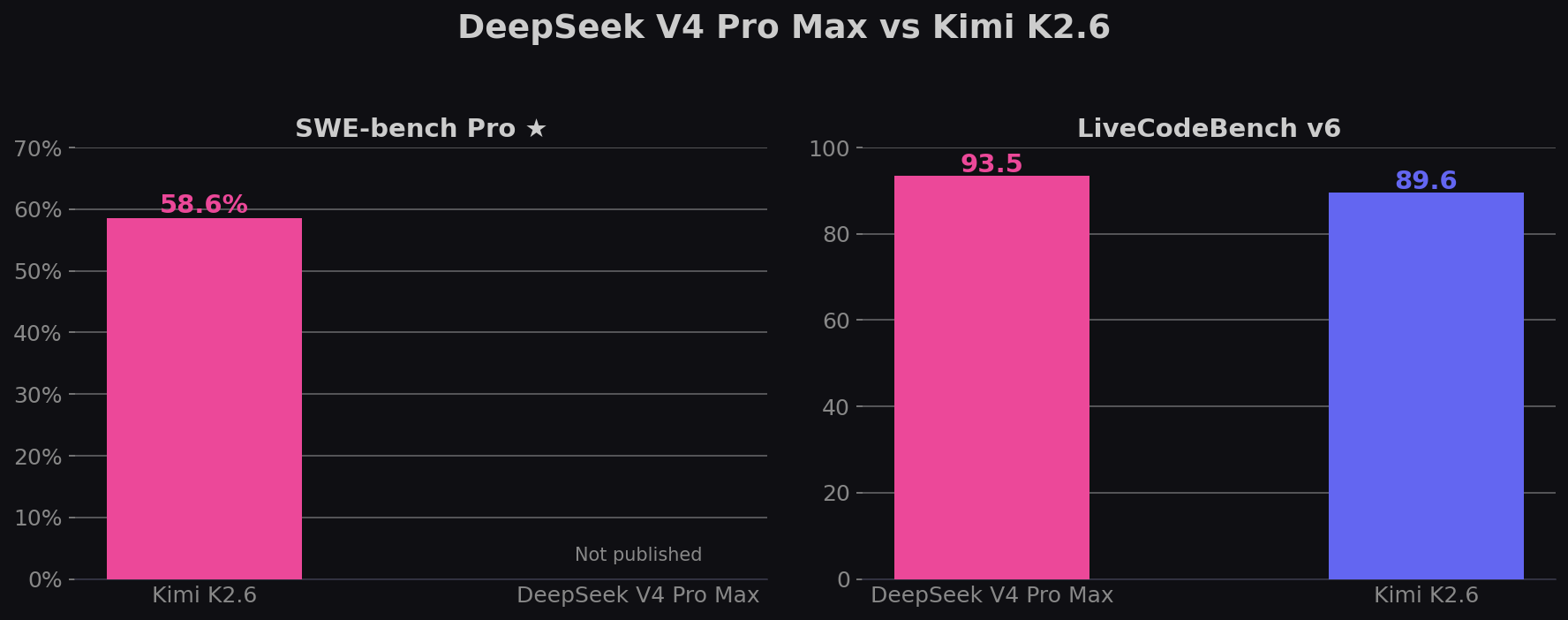
TL;DR: DeepSeek V4 Pro Max leads on LiveCodeBench (93.5%), Terminal-Bench (67.9% vs 66.7%), and context window (1M vs 256K). Kimi K2.6 leads on SWE-bench Pro (58.6%), GPQA Diamond (90.5% vs 90.1%), and HLE (54.0%). Kimi is ~37% cheaper on output. Both are MIT-licensed open weights.
🔥 CodingFleet Unlimited Plan: Use DeepSeek V4 Pro without limits — no weekly, daily, or hourly quotas. Unlimited coding, unlimited chats, unlimited agentic tasks. Try it now →
Benchmark Comparison
Note: SWE-bench Verified is considered contaminated by OpenAI (February 2026). SWE-bench Pro is the recommended alternative for meaningful comparisons. Verified scores shown for historical context only.
| Benchmark | DeepSeek V4 Pro Max | Kimi K2.6 | Winner |
|---|---|---|---|
| SWE-bench Pro ★ | — | 58.6% | Kimi K2.6 |
| SWE-bench Verified ⚠️ | 80.6% | 80.2% | DeepSeek (contaminated) |
| Terminal-Bench 2.0 | 67.9% | 66.7% | DeepSeek V4 (+1.2) |
| GPQA Diamond | 90.1% | 90.5% | Kimi K2.6 |
| LiveCodeBench v6 | 93.5% | 89.6% | DeepSeek V4 |
| HLE (with tools) | — | 54.0% | Kimi K2.6 |
| Codeforces Rating | 3206 | — | DeepSeek V4 |
| AIME 2026 | — | 96.4% | Kimi K2.6 |
Pricing & Architecture
| Spec | DeepSeek V4 Pro Max | Kimi K2.6 |
|---|---|---|
| Input (per 1M tokens) | $1.74 | $0.55 |
| Output (per 1M tokens) | $3.48 | $2.19 |
| Context window | 1M tokens | 256K tokens |
| Architecture | 1.6T MoE (49B active) | 1T MoE (32B active) |
| Image Input | No | Yes |
| License | MIT | Modified MIT |
| Max Output | 393K tokens | — |
Which One Should You Use?
| Use Case | Better Model |
|---|---|
| Full-codebase analysis (100K+ context) | DeepSeek V4 Pro Max — 1M context window, 393K max output |
| SWE-bench Pro agentic coding | Kimi K2.6 — 58.6%, ahead of GPT-5.4 (57.7%) |
| Competitive programming / algorithmic coding | DeepSeek V4 Pro Max — 3206 Codeforces, 93.5% LiveCodeBench |
| Cost-sensitive production at scale | Kimi K2.6 — 37% cheaper output, 68% cheaper input |
| Vision + code workflows | Kimi K2.6 — native image input support |
| Academic reasoning (HLE, AIME) | Kimi K2.6 — 54.0% HLE, 96.4% AIME 2026 |
Conclusion
DeepSeek V4 Pro Max is the stronger pure coder — higher LiveCodeBench and Codeforces scores, plus a massive 1M context window. Kimi K2.6 is the agentic champion — leading on SWE-bench Pro (the uncontaminated benchmark that matters), HLE, and GPQA Diamond, all at significantly lower cost. For large-context codebase work, DeepSeek wins. For real-world agentic coding tasks, Kimi K2.6 delivers more capability per dollar.