
A $4.40/1M MIT-licensed open-weight model just beat OpenAI's $30/1M flagship on the hardest coding benchmark. GLM-5.2 — Z.ai's new 753B-parameter model released June 13 — scores 62.1% on SWE-bench Pro vs GPT-5.5's 58.6%. That's a 3.5-point lead at roughly 1/7 the cost. It also leads HLE with tools (+2.5), FrontierSWE (+1.8), MCP Atlas (+1.7), and PostTrainBench (+9.3). GPT-5.5 fights back with DeepSWE (+23.8), Terminal-Bench 2.1 (+3.0), and a massive ecosystem advantage (Codex CLI, 4M weekly devs, Amazon Bedrock). Here's the complete comparison backed by Z.ai's cross-model benchmark table published via VentureBeat. Try both on CodingFleet.
TL;DR — Key Findings
- GLM-5.2 beats GPT-5.5 on Pro (+3.5): 62.1% vs 58.6%. Open-weight MIT license. 1/7 the cost.
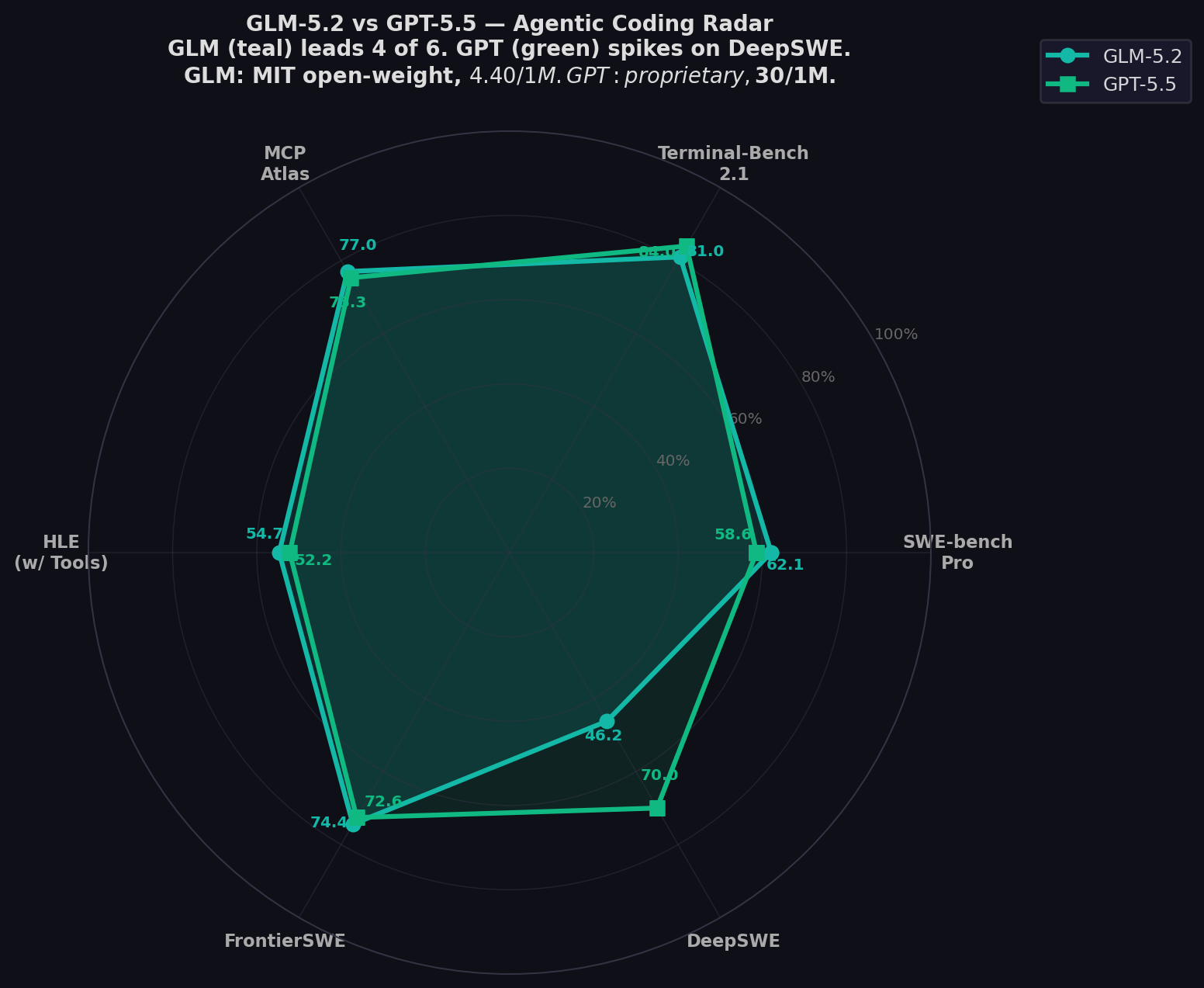
- GLM leads 7 of 12 shared benchmarks: Pro, HLE w/tools, FrontierSWE, MCP Atlas, PostTrainBench, SWE-Marathon, NL2Repo (tied).
- GPT-5.5 leads 5 of 12: Terminal-Bench 2.1, DeepSWE (+23.8), ProgramBench, Tool-Decathlon, HLE no tools.
- 6.8× price gap: GLM $1.40/$4.40 vs GPT $5/$30 per 1M tokens. At 100M output: GLM $440 vs GPT $3,000.
- GLM is MIT open-weight: Weights on HuggingFace. Anthropic API compatible. Drops into Claude Code. GPT-5.5 is proprietary.
- GPT-5.5 ecosystem is unmatched: Codex CLI, 4M weekly devs, Amazon Bedrock, 6 IDE extensions, cloud sandbox.
Try both models on CodingFleet
Full Benchmark Comparison
| Benchmark | GLM-5.2 | GPT-5.5 | Winner |
|---|---|---|---|
| SWE-bench Pro ★ | 62.1% | 58.6% | GLM (+3.5) |
| Terminal-Bench 2.1 | 81.0% | 84.0% | GPT (+3.0) |
| MCP-Atlas | 77.0% | 75.3% | GLM (+1.7) |
| HLE (with tools) | 54.7% | 52.2% | GLM (+2.5) |
| HLE (no tools) | 40.5% | 41.4% | GPT (+0.9 — near tie) |
| FrontierSWE | 74.4% | 72.6% | GLM (+1.8) |
| DeepSWE | 46.2% | 70.0% | GPT (+23.8) |
| ProgramBench | 63.7% | 70.8% | GPT (+7.1) |
| Tool-Decathlon | 48.2% | 55.6% | GPT (+7.4) |
| NL2Repo | 48.9% | 50.7% | GPT (+1.8 — near tie) |
| PostTrainBench | 34.3% | 25.0% | GLM (+9.3) |
| SWE-Marathon | 13.0% | 12.0% | GLM (+1.0 — near tie) |
| Output Price /1M tok | $4.40 | $30.00 | GLM (6.8× cheaper) |
| Input Price /1M tok | $1.40 | $5.00 | GLM (3.6× cheaper) |
Sources: All GLM-5.2 scores from Z.AI cross-model comparison table published via VentureBeat | GPT-5.5 scores from Vellum, Vals.ai, OpenAI announcements. Pricing from Z.AI API and OpenAI API. All scores vendor-reported from Z.AI's published table.
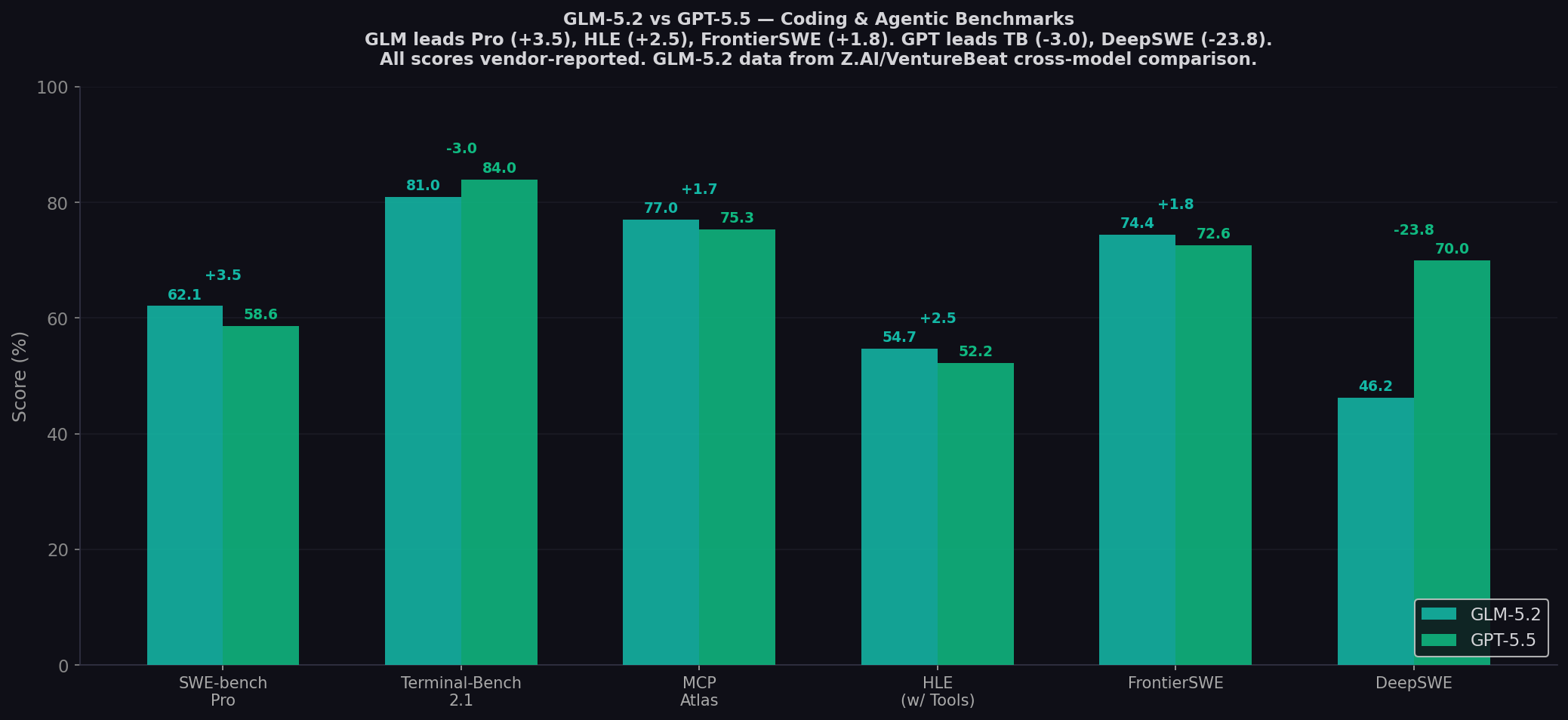
SWE-bench Pro: The 3.5-Point Upset
The defining number. GLM-5.2 at 62.1% vs GPT-5.5 at 58.6%. A 3.5-point gap on the hardest real-world coding benchmark — at 1/7 the cost. VentureBeat's analysis captures the significance: "Z.ai's open-weights GLM-5.2 beats GPT-5.5 on multiple long-horizon coding benchmarks for 1/6th the cost." The MIT license means enterprises can download the weights from HuggingFace, fine-tune on proprietary codebases, and deploy air-gapped — with no vendor lock-in, no API dependency, and no usage-based billing surprises.
DeepSWE: GPT-5.5's 23.8-Point Fortress
The widest gap on any shared benchmark — and it favors GPT-5.5 decisively. DeepSWE at 70.0% vs GLM-5.2 at 46.2%. This benchmark tests the hardest software engineering tasks: deep multi-file refactors, complex dependency resolution, architectural changes across large codebases. GPT-5.5's Codex CLI infrastructure — with cloud sandbox execution, 24+ hour unattended runs, and kernel-level sandboxing — was built specifically for these workloads. GLM-5.2's 1M context window and long-horizon capabilities are architecturally relevant here, but the benchmark gap suggests the Codex harness provides a structural advantage that raw model capability alone can't close.
FrontierSWE: GLM's Near-Opus Territory
GLM-5.2 at 74.4% on FrontierSWE — just 0.7 points behind Claude Opus 4.8 (75.1%). GPT-5.5 at 72.6%. This benchmark tests long-horizon software engineering across frontier-level tasks, and DataCamp reports Z.ai claims GLM-5.2 "ranks #1 open-source and #3 overall on FrontierSWE, nearing Claude Opus 4.8." For an MIT-licensed model at $4.40/1M output, approaching Opus 4.8 ($25/1M) on any benchmark is remarkable.
Architecture & Ecosystem
| Feature | GLM-5.2 | GPT-5.5 |
|---|---|---|
| Release Date | June 13, 2026 | April 23, 2026 |
| Developer | Z.ai (formerly Zhipu AI, Beijing) | OpenAI |
| Parameters | 753B (MoE architecture) | Not disclosed |
| Context Window | 1,000,000 tokens | 1,000,000 tokens (922K via AA) |
| Max Output Tokens | 131,072 | 128K |
| Thinking Modes | High, Max | Adaptive, xHigh |
| License | MIT (open weights) | Proprietary |
| API Compatibility | Anthropic API (Claude Code native) | OpenAI SDK, Azure, Amazon Bedrock |
| Coding Plan | $3-$80/mo subscription tiers | ChatGPT Plus $20, Pro $100, Pro 20× $200 |
| Agent Ecosystem | Claude Code, Cline, OpenClaw, Kilo Code | Codex CLI, IDE extensions (6), cloud agents |
| Self-Hosting | Yes — MIT, HuggingFace, vLLM/SGLang | No |
| Multimodal Input | Text | Text, Image, Audio, Video |
Why GLM-5.2 Wins: The Open-Weight Disruption
GLM-5.2 is Z.ai's third MIT-licensed flagship in six months — GLM-5 (February), GLM-5.1 (April), GLM-5.2 (June). The entire lineage was trained on Huawei Ascend chips, proving frontier-scale models don't require NVIDIA hardware. The 1M context window (5× GLM-5.1's 200K) handles entire codebases in a single session. Setup is trivial: set ANTHROPIC_DEFAULT_SONNET_MODEL=glm-5.2[1m] in Claude Code and you're running. Two thinking modes (High for speed, Max for depth). The VentureBeat analysis highlights the geopolitical dimension: "An MIT license guarantees no regional limits and allows technical access without borders — increasingly appealing following the Trump Administration's export control directive." AICodeKing (129K YouTube subscribers) tested GLM-5.2 and reported "scores around 81.43 on my benchmark, only about 6% below Opus 4.8 and Fable."
Why GPT-5.5 Wins: The Ecosystem Moat
GPT-5.5's Codex ecosystem is the most mature agentic coding platform in existence. 4 million weekly active developers. Codex CLI: install with npm, run from any project root, structured agent loops with /plan /exec /review. Cloud sandbox: 24+ hour unattended runs, kernel-level isolation. 6 IDE extensions: VS Code, JetBrains, Visual Studio, Neovim, Xcode, Eclipse. Amazon Bedrock integration for enterprise AWS deployments. Omnimodal input: text, image, audio, video — GLM-5.2 is text-only. The DeepSWE 23.8-point gap isn't about model intelligence — it's about infrastructure. For teams building production coding agents where harness maturity, enterprise compliance, and multimodal input matter more than raw Pro scores, GPT-5.5 is the safer bet. Nipralo's review notes: "For agentic coding tasks like multi-file refactors and long debug sessions, GPT-5.5 wins consistently."
Pricing: 6.8× Economics
At 100M output tokens/month:
- GLM-5.2 (API): $440 output + $140 input = $580/month
- GPT-5.5 (API): $3,000 output + $500 input = $3,500/month
- GLM-5.2 (Coding Plan Pro): ~$15-19/month flat — unlimited prompts per 5-hour cycle
The $2,920 monthly difference funds an entire additional development team's AI tooling — or a self-hosted GLM-5.2 deployment on your own GPUs with zero API costs. Lushbinary's pricing guide notes GLM Coding Plan tiers start at $3/month (Lite) and scale to $80/month (Max) for heavy agentic work.
Which Model Should You Use?
| Use Case | Winner | Why |
|---|---|---|
| Real GitHub issue fixing | GLM ✅ | +3.5 Pro. Better multi-file bug resolution at 1/7 cost |
| Deep multi-file refactors | GPT ✅ | +23.8 DeepSWE. Codex CLI infrastructure wins |
| Terminal / CLI agents | GPT ✅ | +3.0 TB 2.1. Codex CLI is the best terminal harness |
| Agentic coding w/ tools | GLM ✅ | +2.5 HLE w/tools. +1.7 MCP Atlas |
| Long-horizon engineering | GLM ✅ | +1.8 FrontierSWE. +9.3 PostTrainBench |
| Self-hosting / air-gapped | GLM ✅ | MIT license. HuggingFace. Huawei Ascend compatible |
| Budget / high-volume | GLM ✅ | 6.8× cheaper API. $15/mo flat via Coding Plan |
| Enterprise ecosystem | GPT ✅ | 6 IDEs, Amazon Bedrock, Azure, SOC 2, SSO |
Conclusion: The Open-Weight Model Beats the Proprietary Flagship on Pro
GLM-5.2 leads GPT-5.5 on 7 of 12 shared benchmarks — including SWE-bench Pro, the one that matters most for real-world coding. At 1/7 the cost, with an MIT license and Anthropic API compatibility, it represents the direction the AI coding market is heading: open-weight models that match or beat proprietary flagships on core benchmarks while offering deployment freedom that closed models can't match.
GPT-5.5 retains decisive advantages in DeepSWE, Terminal-Bench, the Codex ecosystem, and omnimodal input. For teams building production coding agents where infrastructure maturity and enterprise compliance justify the premium, GPT-5.5 remains the safer choice. But the gap is shrinking — and at 6.8× the cost, the premium is getting harder to justify.
20+ LLMs available. Test GLM-5.2 and GPT-5.5 side-by-side in the sandbox — your code runs even when your PC is off.
Sources & Links
- VentureBeat — Z.ai's GLM-5.2 beats GPT-5.5 on long-horizon benchmarks
- MarkTechPost — GLM-5.2 launch details
- DataCamp — GLM-5.2 features, setup, and model switching guide
- Lushbinary — GLM-5.2 API pricing and GLM Coding Plan guide
- Digital Applied — GLM-5.2 lands on Z.ai's coding plan
- Reddit r/chutesAI — GLM-5.2 community discussion
- AICodeKing (129K) — GLM-5.2 fully tested
- Vellum — GPT-5.5 benchmarks
- Vals.ai — SWE-bench Verified leaderboard
- Nipralo — GPT-5.5 review 2026
- Tosea — Codex complete guide 2026
Read This Next
- SWE-bench Pro Leaderboard — every model ranked
- Terminal-Bench 2.1 Leaderboard
- AI Model Pricing Calculator