
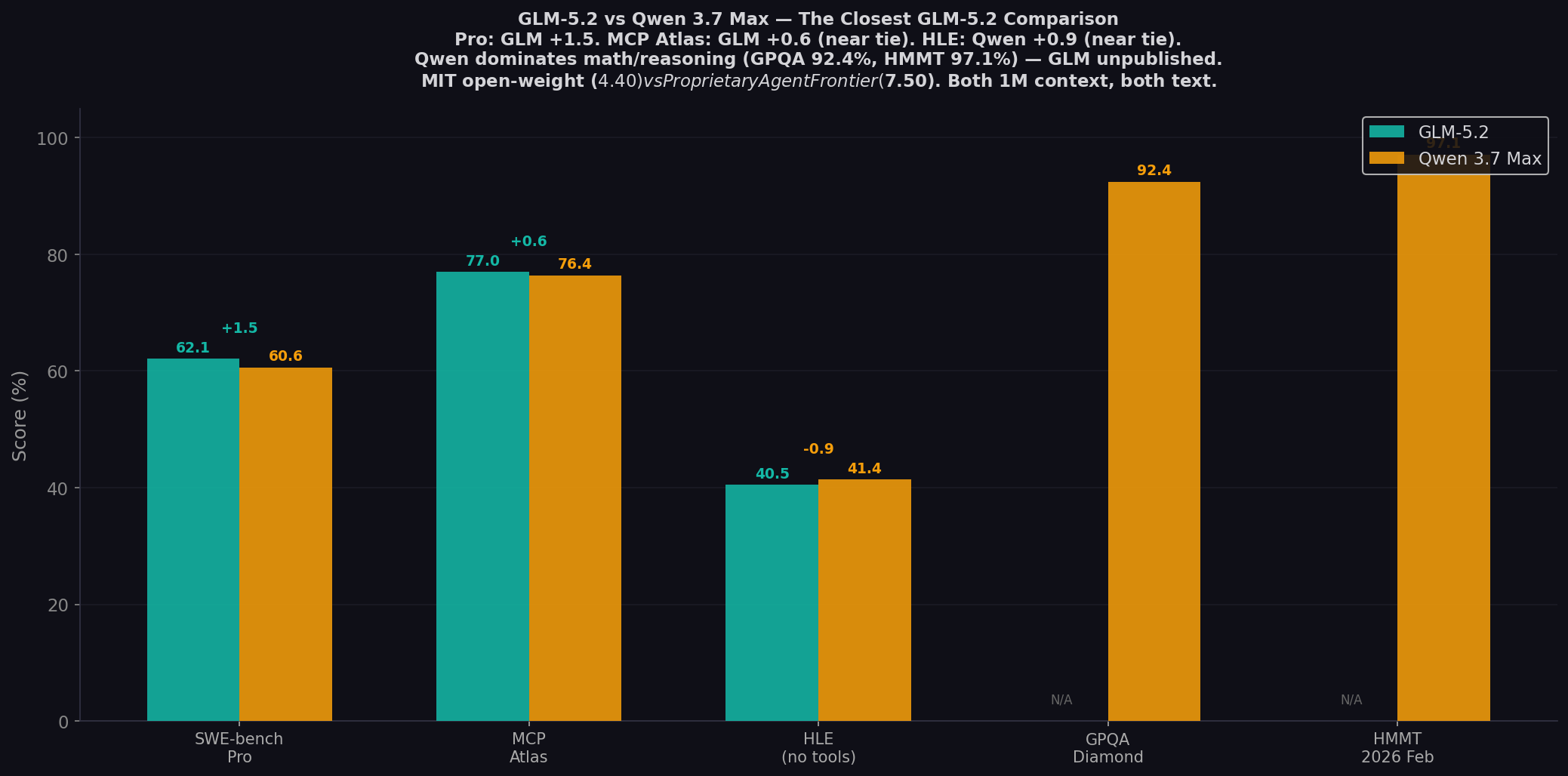
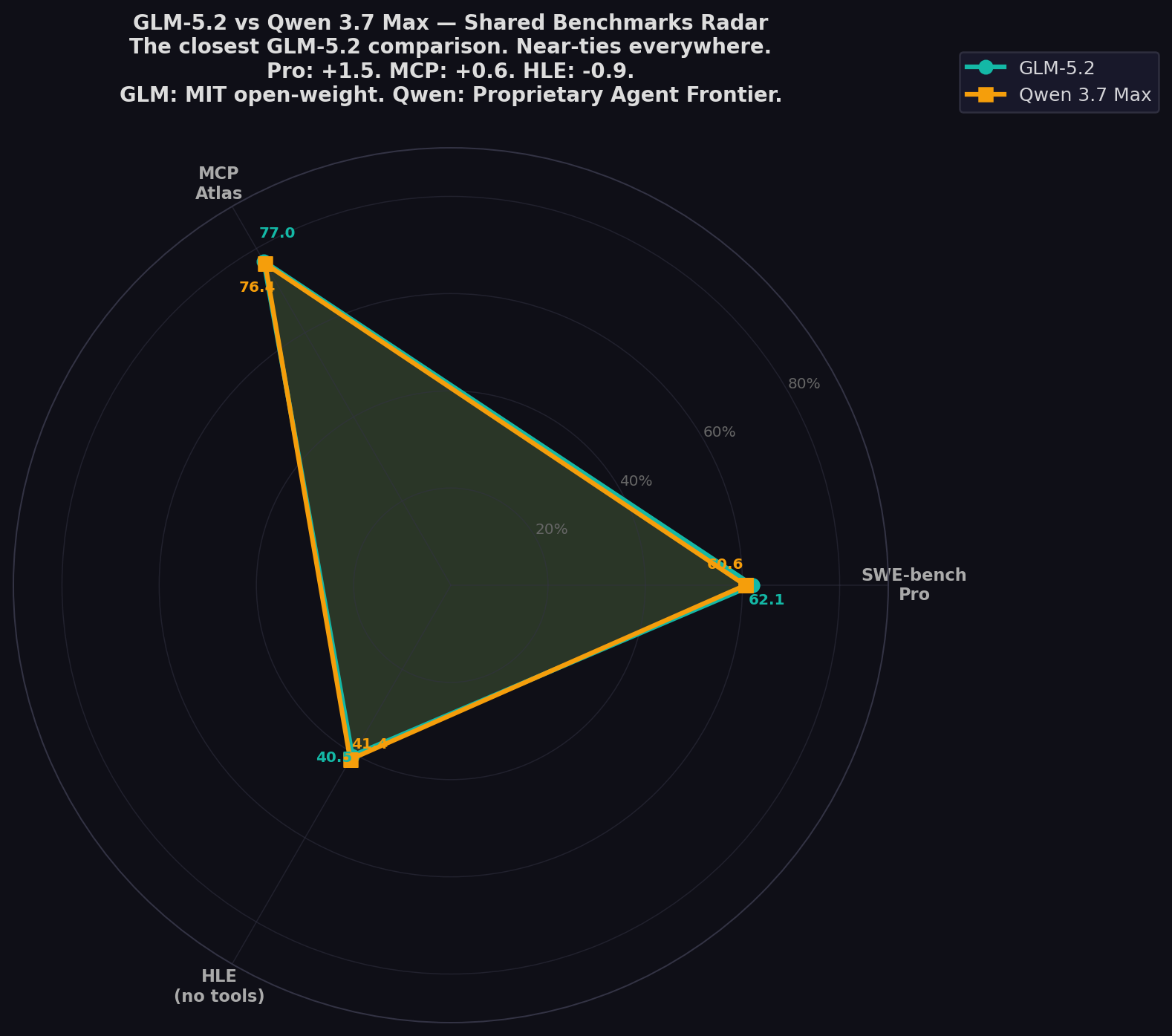
This is the closest GLM-5.2 comparison. On the three directly comparable benchmarks, the margins are +1.5, +0.6, and -0.9. These models are functionally tied on real-world coding performance. GLM-5.2 is Z.ai's MIT-licensed open-weight champion — 62.1% SWE-bench Pro, 77.0% MCP Atlas, Anthropic API native. Qwen 3.7 Max is Alibaba's proprietary "Agent Frontier" — 60.6% Pro, 76.4% MCP Atlas, 35-hour autonomous operation, 96% Kernel Bench win rate. GLM is cheaper (1.7×), open-weight, Claude Code native. Qwen is the proven agentic workhorse with stronger math and reasoning. Full comparison from Z.AI, Qwen blog, and Amit Ray analysis. Test both on CodingFleet.
TL;DR — Key Findings
- Near-ties everywhere: Pro: GLM +1.5. MCP Atlas: GLM +0.6. HLE: Qwen +0.9. Functionally identical on coding.
- Qwen dominates math/reasoning: GPQA 92.4%, HMMT 97.1%, Apex 44.5, LiveCodeBench 91.6%. GLM unpublished.
- Qwen is the Agent Frontier: 35-hour autonomous runs. 1,000+ tool calls. 96% Kernel Bench win rate.
- GLM is MIT open-weight: Download, self-host, fine-tune. Qwen 3.7 Max is proprietary API-only.
- GLM is cheaper: $4.40/1M vs Qwen $7.50. GLM Coding Plan from $3/mo.
Benchmark Comparison
| Benchmark | GLM-5.2 | Qwen 3.7 Max | Winner |
|---|---|---|---|
| SWE-bench Pro ★ | 62.1% | 60.6% | GLM (+1.5 — near tie) |
| MCP Atlas | 77.0% | 76.4% | GLM (+0.6 — near tie) |
| HLE (no tools) | 40.5% | 41.4% | Qwen (+0.9 — near tie) |
| HLE (with tools) | 54.7% | — | GLM |
| DeepSWE | 46.2% | — | GLM |
| GPQA Diamond | — | 92.4% | Qwen |
| HMMT 2026 Feb | — | 97.1% | Qwen |
| LiveCodeBench | — | 91.6% | Qwen |
| Kernel Bench L3 | — | 96% WR | Qwen |
| Output Price /1M tok | $4.40 | $7.50 | GLM (1.7×) |
Sources: GLM-5.2 from Z.AI via VentureBeat | Qwen from Qwen Blog, Amit Ray. All vendor-reported.
SWE-bench Pro: 1.5 Points — Statistical Noise
GLM at 62.1% vs Qwen at 60.6%. Within harness variation. Both beat GPT-5.5 (58.6%). For real GitHub issues, identical reliability. Dr. Amit Ray: "A 60.6% resolved rate places Qwen among the strongest AI coding agents." GLM at 62.1% does the same — 1.5 points more often.
Qwen's Agent Frontier: 35 Hours Autonomous
Qwen's headline: 35-hour unattended operation, 1,000+ sequential tool calls, 96% Kernel Bench win rate with 1.98× GPU speedup. Alibaba's blog documents this as "cross-harness generalization — working across diverse agent frameworks without framework-specific tuning." GLM-5.2 inherited GLM-5.1's ~8-hour autonomous runs — but hasn't published its own sustained-run numbers.
Qwen's Math Dominance
GPQA Diamond 92.4%, HMMT 97.1%, Apex 44.5, LiveCodeBench 91.6%. GLM-5.2 hasn't published competitive math/programming scores. For math-heavy coding tasks — algorithmic generation, formal verification, scientific computing — Qwen has a proven capability GLM can't claim.
Architecture
| Feature | GLM-5.2 | Qwen 3.7 Max |
|---|---|---|
| License | MIT (open weights) | Proprietary API-only |
| Context | 1M | 1M |
| API Compat | Anthropic (Claude Code native) | Anthropic + OpenAI |
| Autonomous | ~8h (GLM-5.1 baseline) | 35 hours |
| Kernel Bench | — | 96% WR |
| Price | $4.40/1M | $7.50/1M |
Which to Use?
| Use Case | Winner |
|---|---|
| GitHub issues | GLM (+1.5) |
| Math/reasoning | Qwen (92.4% GPQA) |
| Tool orchestration | ⚖️ Tie (+0.6 GLM) |
| Unattended agents | Qwen (35hr) |
| Self-hosting | GLM (MIT) |
| Budget | GLM (1.7× cheaper) |
Conclusion: Benchmark Twins, Different Philosophies
On coding benchmarks, these models are twins — the gaps are statistically invisible. Choose GLM-5.2 for MIT open-weight freedom, Claude Code integration, and lower cost. Choose Qwen 3.7 Max for proven 35-hour autonomy, world-class math, and kernel optimization. They're complementary — run GLM as your Claude Code agent, Qwen as your math/reasoning specialist.
Mission: Find Your Model
#1 and #2 on SWE-bench Pro. Test both side-by-side on CodingFleet. Sandbox runs 24/7.
⚡ Head-to-Head Test →