
Speed vs Versatility: The Mid-Tier Showdown
In the race for cost-effective frontier performance, two models stand out: OpenAI's GPT-5.4 (March 2026) and Google's Gemini 3.5 Flash (May 2026). One is a proven workhorse for agentic coding at scale. The other is Google's latest Flash-class model punching well above its weight class. Here's how they compare.
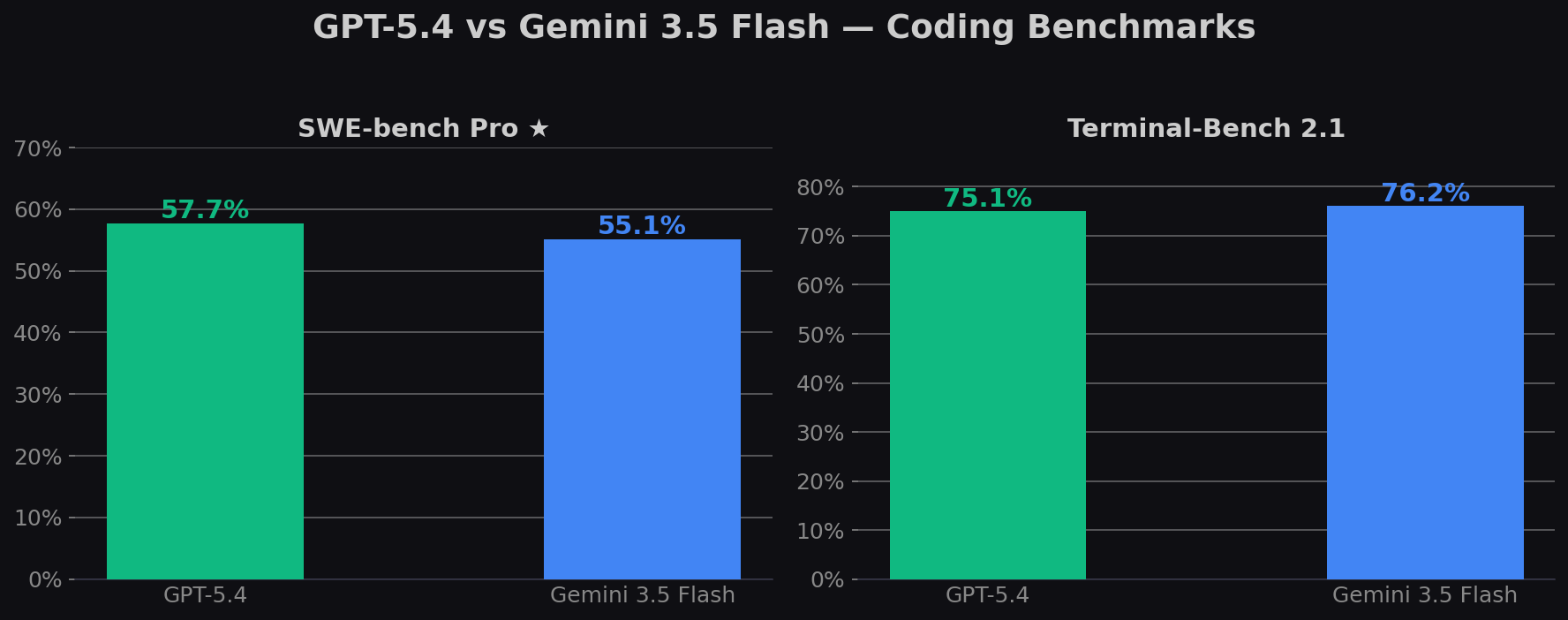
TL;DR: GPT-5.4 wins on agentic terminal tasks (75.1% Terminal-Bench) and long-context retrieval. Gemini 3.5 Flash counters with stronger OSWorld computer use (78.4% vs 75.0%), MCP Atlas tool orchestration (83.6% vs 70.6%), and a 40%+ price advantage on output tokens ($9 vs $15). On SWE-bench Pro — the recommended benchmark now that Verified is considered contaminated — GPT-5.4 leads (57.7% vs 55.1%).
Try both models on CodingFleet: Start a new chat → and pick your model.
Benchmark Comparison
Note: SWE-bench Verified scores are shown for historical context but OpenAI stopped reporting them in February 2026 after finding contamination across all frontier models. SWE-bench Pro is the recommended alternative for meaningful comparisons.
| Benchmark | GPT-5.4 | Gemini 3.5 Flash | Winner |
|---|---|---|---|
| SWE-bench Pro ★ | 57.7% | 55.1% | GPT-5.4 (+2.6) |
| SWE-bench Verified ⚠️ | 78.2% | 78.8% | Gemini (contaminated) |
| Terminal-Bench 2.1 | 75.1% | 76.2% | Gemini 3.5 Flash |
| OSWorld-Verified | 75.0% | 78.4% | Gemini 3.5 Flash |
| MCP Atlas (tool orchestration) | 70.6% | 83.6% | Gemini 3.5 Flash |
| GDPval-AA (Elo) | ~1700 | 1656 | GPT-5.4 |
| MRCR v2 (128K context) | ~94% | 77.3% | GPT-5.4 |
| HLE (academic reasoning) | 52.1% | 40.2% | GPT-5.4 |
| Finance Agent v2 | — | 57.9% | Gemini 3.5 Flash |
Pricing & Specs
| Spec | GPT-5.4 | Gemini 3.5 Flash |
|---|---|---|
| Input (per 1M tokens) | $2.50 | $1.50 |
| Output (per 1M tokens) | $15.00 | $9.00 |
| Batch/Flex discount | 50% off ($1.25/$7.50) | 50% off ($0.75/$4.50) |
| Context window | 1M+ | 1M |
| Multimodal | Text + vision | Text + vision + audio + video |
| Computer Use | Native (OSWorld 75%) | Native (OSWorld 78.4%) |
Which One Should You Use?
| Use Case | Better Model |
|---|---|
| SWE-bench Pro multi-file bug fixing | GPT-5.4 — 57.7% vs 55.1% on the recommended benchmark |
| Computer-use / browser agents | Gemini 3.5 Flash — 78.4% OSWorld |
| Multi-tool MCP orchestration | Gemini 3.5 Flash — 83.6% MCP Atlas vs 70.6% |
| Long-context retrieval (128K+) | GPT-5.4 — significantly better needle retrieval |
| Financial analysis / knowledge work | Gemini 3.5 Flash — 57.9% Finance Agent v2, strong GDPval-AA |
| Cost-sensitive production at scale | Gemini 3.5 Flash — 40% cheaper output, 40% cheaper input |
Conclusion
GPT-5.4 is the stronger reasoning model — better at SWE-bench Pro, long-context retrieval, and academic benchmarks like HLE. Gemini 3.5 Flash is the agentic play — leading on OSWorld computer use, MCP tool orchestration, and Terminal-Bench, all at 40% lower cost. If you're building tool-heavy agentic pipelines or computer-use automation, Gemini 3.5 Flash is the better value. For deep reasoning over large codebases, GPT-5.4 still holds an edge.