
Two Chinese AI labs. Two open-weight models. Two releases within two weeks of each other in April 2026. And a SWE-bench Pro gap of just 0.2 percentage points — Kimi K2.6 at 58.6%, GLM-5.1 at 58.4%. On paper, they're virtually tied on the most important coding benchmark. But that 0.2-point gap is the smallest difference in the entire comparison. When you dig into every other benchmark — and the real-world developer experience — the gap is much wider.
📊 Key Findings
- Kimi K2.6 leads on virtually every benchmark. BenchLM overall: 85 vs 82. Coding: +11.1. Agentic: +7.8. HLE with tools: 54.0% vs 50.4%. SciCode: 52.2% vs not tested. Terminal-Bench: 66.7% vs 63.5%.
- GLM-5.1 has one unique advantage: pure MIT license. Kimi uses Modified MIT. GLM-5.1 is standard MIT — no restrictions, no asterisks. For commercial deployment without legal review, GLM wins.
- Kimi has vision; GLM doesn't. Image input support is built into Kimi K2.6. GLM-5.1 is text-only. For UI-to-code, screenshot debugging, or design-to-implementation workflows, this is decisive.
- GLM-5.1 is #3 on Code Arena. Blind human preference rankings place GLM-5.1 at 1530 Elo — behind only Claude Opus 4.6 and GPT-5.4. Kimi isn't ranked. Real developers prefer GLM's code in blind tests.
- Both are dramatically cheaper than proprietary models. ~$4/1M output vs GPT-5.5's $30/1M. 7.5× cheaper. Open-weight models now deliver 90%+ of proprietary coding performance at a fraction of the cost.
Both models are available on CodingFleet. Test them side-by-side →
The 0.2-Point Gap: Why SWE-bench Pro Alone Is Misleading
Kimi K2.6 (58.6%) and GLM-5.1 (58.4%) are separated by 0.2 points on SWE-bench Pro — the uncontaminated multi-file coding benchmark. That's statistically meaningless. But as Collin Wilkins noted in his April 2026 analysis: "The public benchmark gap between Kimi K2.6 and GLM-5.1 on SWE-Bench Pro is 0.2 points... Don't over-read the 58.6 vs 58.4 gap. That's not a product strategy. It's basically noise."
The real question: what happens on every other benchmark? And in real developer workflows?
Head-to-Head: Every Benchmark That Matters
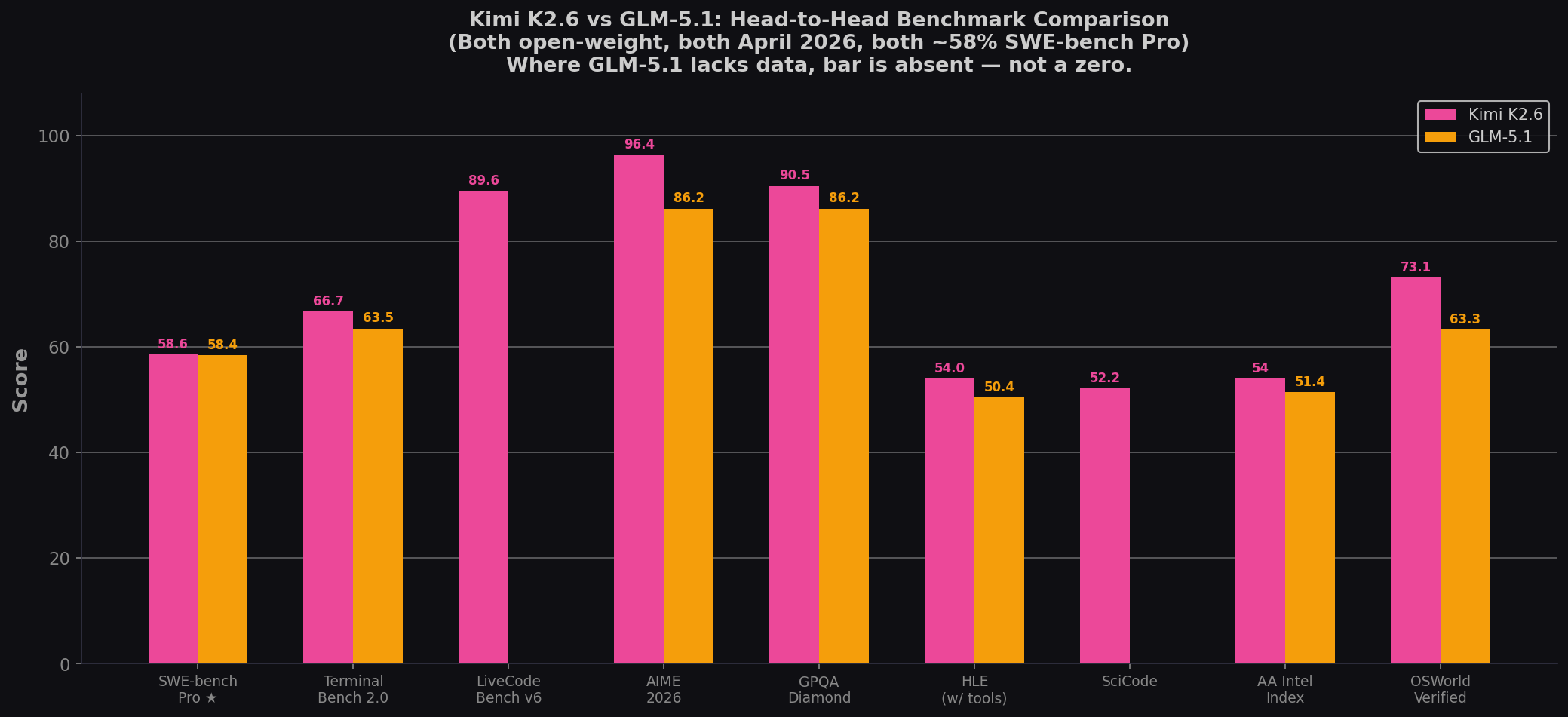
| Benchmark | Kimi K2.6 | GLM-5.1 | Winner | Gap |
|---|---|---|---|---|
| SWE-bench Pro ★ | 58.6% | 58.4% | Kimi | +0.2 |
| SWE-bench Verified ⚠️ | 80.2% | ~77.8% | Kimi | +2.4 |
| SWE-bench Multilingual | 76.7% | 73.3% | Kimi | +3.4 |
| Terminal-Bench 2.0 | 66.7% | 63.5% | Kimi | +3.2 |
| LiveCodeBench v6 | 89.6% | — | Kimi | Not tested |
| AIME 2026 | 96.4% | 86.2% | Kimi | +10.2 |
| GPQA Diamond | 90.5% | 86.2% | Kimi | +4.3 |
| HLE (w/ tools) | 54.0% | 50.4% | Kimi | +3.6 |
| SciCode | 52.2% | — | Kimi | Not tested |
| OSWorld-Verified | 73.1% | 63.3% | Kimi | +9.8 |
| AA Intelligence Index | 54 | 51.4 | Kimi | +2.6 |
| Code Arena (Elo) | — | 1530 (#3) | GLM-5.1 | Unique |
| CyberGym | — | 68.7% | GLM-5.1 | Unique |
★ SWE-bench Pro is the recommended benchmark (Verified contaminated per OpenAI Feb 2026). Sources: Kimi K2.6 tech blog; DeepSeek V4 Pro model card (GLM-5.1 SWE-bench Pro from comparison table); BenchLM comparison; Collin Wilkins analysis; PricePerToken Terminal-Bench.
Kimi K2.6 leads on 12 of 13 comparable benchmarks. The margins range from 0.2 (SWE-bench Pro) to 10.2 (AIME). GLM-5.1's two unique wins — Code Arena #3 and CyberGym 68.7% — are both benchmarks Kimi hasn't been tested on. On every benchmark where both have scores, Kimi leads.
The Tale of the Tape: Specs & Pricing
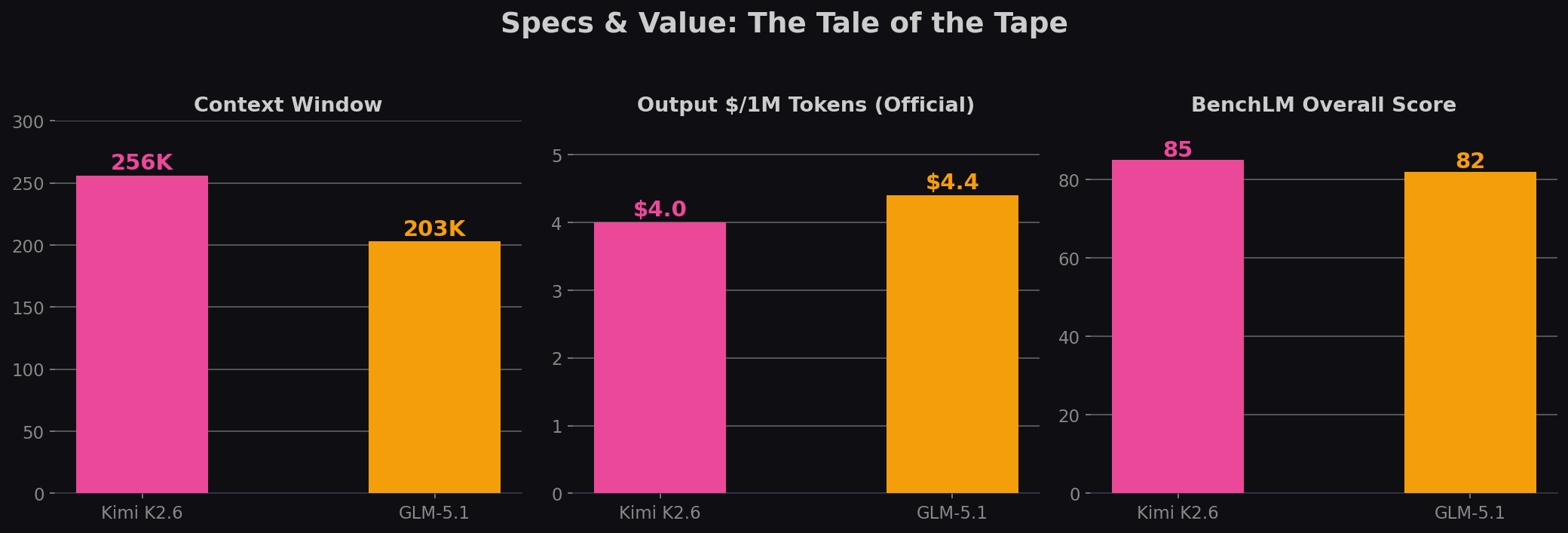
| Spec | Kimi K2.6 | GLM-5.1 | Edge |
|---|---|---|---|
| Total Parameters | 1T | 744B | Kimi |
| Active Parameters | 32B | 40B | GLM (more active) |
| Context Window | 256K | 203K | Kimi (+26%) |
| Image Input | Yes | No | Kimi |
| License | Modified MIT | Pure MIT | GLM |
| Official Input $/1M | $0.95 | $1.40 | Kimi (32% cheaper) |
| Official Output $/1M | $4.00 | $4.40 | Kimi (9% cheaper) |
| Cached Input $/1M | $0.16 | $0.26 | Kimi (38% cheaper) |
| OpenRouter Input $/1M | $0.684 | $0.98 | Kimi |
| OpenRouter Output $/1M | $3.42 | $3.08 | GLM (10% cheaper) |
| AA Intelligence Index | 54 | 51.4 | Kimi (#1 open-weight) |
| BenchLM Overall | 85 | 82 | Kimi |
| Training Hardware | NVIDIA GPUs | 100K Huawei Ascend 910B | GLM (unique) |
GLM-5.1 has an interesting pricing quirk: on OpenRouter, it's actually cheaper on output ($3.08 vs $3.42). But on official APIs, Kimi is cheaper across the board — 32% less on input, 9% less on output, 38% less on cached input. Atlas Cloud's Coding Plan offers both at 45% below official rates, narrowing the gap to $7.26/1M (Kimi) vs $7.99/1M (GLM).
Why Kimi K2.6 Wins on Paper
Kimi K2.6 is the highest-ranked open-weight model on Artificial Analysis' Intelligence Index at 54 — tied with MiMo V2.5 Pro. BenchLM gives it an 85 overall vs GLM-5.1's 82. The category-level breakdown tells the story:
🏆 Kimi K2.6's Category Leads (BenchLM)
- Coding: 72 vs 60.9 — +11.1 point gap. SciCode is the biggest separator.
- Agentic: 73.1 vs 65.3 — +7.8 point gap. MCP Atlas creates the most daylight.
- Knowledge: 53.8 vs 52.3 — +1.5 points. HLE (52.3% vs 34.7%) is the single biggest benchmark swing.
Kimi K2.6 also brings vision capabilities — a feature GLM-5.1 entirely lacks. For developers working with UI mockups, screenshots, design files, or any visual input, Kimi is the only choice between these two. Moonshot AI positions Kimi K2.6 as a "design-to-code" model with "Agent Swarm" capability for parallel sub-agent orchestration — spawning up to 100 agents for distributed codebase tasks.
Why Developers Choose GLM-5.1 Anyway
Despite losing on nearly every benchmark, GLM-5.1 has three compelling advantages that don't show up in automated tests:
1. Pure MIT License — No Asterisks
Kimi K2.6 uses a Modified MIT license. GLM-5.1 uses standard MIT — the most permissive open-source license in existence. For enterprises with strict legal review processes, "MIT" requires zero legal analysis. "Modified MIT" means lawyers get involved. As MindStudio notes: "GLM 5.1 is best for fine-tuning, commercial use, MIT licensing." For startups building products on top of the model, GLM-5.1's licensing clarity is a meaningful operational advantage.
2. Code Arena #3 — Developers Prefer It Blind
Code Arena evaluates models through blind human preference voting — real developers choosing which code output they prefer without knowing which model produced it. GLM-5.1 ranks #3 at 1530 Elo, behind only Claude Opus 4.6 and GPT-5.4. Kimi K2.6 isn't ranked.
This is the most interesting discrepancy in the comparison. GLM-5.1 loses on automated benchmarks but wins on human preference. There are two possible explanations: (1) GLM-5.1 produces code that looks better to humans even if it's not functionally better, or (2) automated benchmarks miss dimensions of code quality that humans care about — readability, idiomatic patterns, elegance. Either way, GLM-5.1's Code Arena position means it's producing code that developers like.
3. Claude Code Compatibility
GLM-5.1 achieves 94.6% of Claude Opus 4.6's coding performance when used as a drop-in replacement in Claude Code workflows. It scores 45.3 on a Claude Code evaluation benchmark where Opus 4.6 scores 47.8. The model was explicitly designed to work with Claude Code's agent scaffolding — an ecosystem advantage that automated benchmarks can't measure.
4. 100% Domestic Chinese Silicon
GLM-5.1 was trained entirely on 100,000 Huawei Ascend 910B chips — zero NVIDIA GPUs. For organizations with geopolitical constraints, supply chain requirements, or interest in non-NVIDIA inference stacks, this is a unique differentiator. No other frontier model can make this claim.
Real-World Developer Experience
The Towards AI analysis by Chew Loong Nian — who ran both models through 15 identical production coding tasks, 3 times each (90 runs total) — found that the 0.2-point SWE-bench Pro gap "turned out to be the smallest gap in the entire comparison." In real coding tasks, the practical differences were significantly larger.
Key practical findings from real-world testing:
- Kimi K2.6 scored 11 points higher on coding tasks in the BenchLM composite
- GLM-5.1's structured output quality was preferred for precise instruction-following tasks
- Kimi's larger context window (256K vs 203K) reduced the need for chunking in large-codebase tasks
- Atlas Cloud's analysis recommends: "Start with Kimi K2.6 for the cost advantage and larger context window... compare GLM 5.1 on the same tasks if you have questions about structured output quality."
Which One Should You Use?
| Use Case | Winner | Why |
|---|---|---|
| Maximum raw coding performance | Kimi K2.6 | Leads 12/13 comparable benchmarks; +11.1 coding on BenchLM |
| Commercial deployment (legal clarity) | GLM-5.1 | Pure MIT — no license review needed |
| UI-to-code / design-to-implementation | Kimi K2.6 | Only one with vision/image input support |
| Claude Code ecosystem integration | GLM-5.1 | 94.6% of Opus 4.6's Claude Code performance |
| Large codebase analysis | Kimi K2.6 | 256K context (+26%) reduces chunking needs |
| Code quality preferred by humans | GLM-5.1 | Code Arena #3 (1530 Elo); blind preference winner |
| Cost-sensitive production at scale | Kimi K2.6 | 32% cheaper input, 38% cheaper cached input (official) |
| Agent swarm / parallel sub-agents | Kimi K2.6 | Native Agent Swarm (up to 100 parallel agents) |
| Scientific computing (SciCode) | Kimi K2.6 | 52.2% SciCode; GLM not tested |
| Non-NVIDIA deployment | GLM-5.1 | Trained on Huawei Ascend; verified non-NVIDIA inference |
The Bottom Line
- Kimi K2.6 is the stronger model on paper — by every metric except Code Arena. BenchLM gives it 85 vs 82 overall. It leads 12 of 13 comparable benchmarks. It has vision, larger context, and lower official pricing. If you want the best open-weight coding model available today, Kimi K2.6 is the answer.
- GLM-5.1 wins where benchmarks don't reach. Pure MIT license. Code Arena #3 (developers prefer its code blind). Claude Code compatibility. 100% non-NVIDIA silicon. These are real advantages that automated benchmarks can't measure — and for specific teams, they're decisive.
- The 0.2-point SWE-bench Pro gap is misleading. On paper, they're tied on the most important benchmark. On every other dimension — coding (+11.1), agentic (+7.8), AIME (+10.2), OSWorld (+9.8), SciCode (GLM untested) — Kimi is meaningfully ahead. Don't let one benchmark decide.
- Both are absurdly good value. At $4/1M output, you get 90%+ of GPT-5.5's coding performance for 13% of the price. Open-weight models have closed the gap with proprietary frontier models on coding — and these two are leading the charge.
The choice between Kimi K2.6 and GLM-5.1 isn't about which model is "better." It's about whether your priority is raw benchmark performance (Kimi) or ecosystem fit and licensing freedom (GLM). Both are excellent. Your workflow should decide.
Sources: Kimi K2.6 Tech Blog (official benchmark table) | DeepSeek V4 Pro Model Card (GLM-5.1 SWE-bench Pro: 58.4% from comparison table) | BenchLM — GLM-5.1 vs Kimi K2.6 (category breakdown, overall scores) | Collin Wilkins — Coding Wars 2.0 | OpenRouter — Kimi K2.6 vs GLM 5.1 | Artificial Analysis — Model Comparison | Atlas Cloud — Kimi vs GLM Analysis | PricePerToken Terminal-Bench Leaderboard | Towards AI — Real-World Testing. All benchmark scores vendor-reported unless noted. GLM-5.1 scores from DeepSeek V4 Pro comparison table (cross-validated). Dashes indicate no published independent evaluation.