MCP Atlas Leaderboard
Multi-server tool orchestration. 36 real MCP servers, 1,000 tasks, claims-based scoring. The benchmark that tests what AI agents actually do — chain tools together correctly.
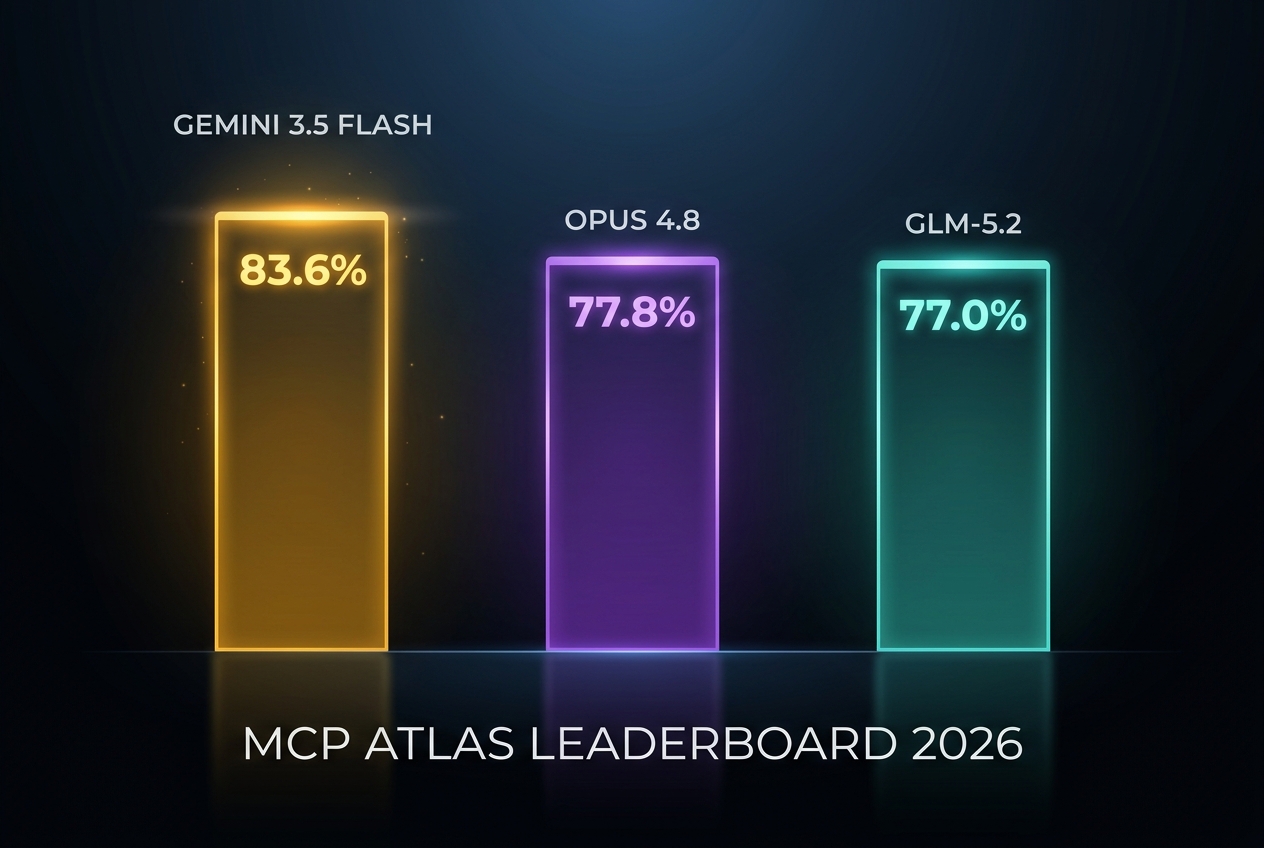
Last updated: July 21, 2026 · 🆕 Muse Spark 1.1 leads at 88.1%; Kimi K3 reaches 84.2% · SWE-bench Pro → · Terminal-Bench →
#
Model
Prov
Score
License
$/1M Out
Released
Src
MCP Atlas Score Comparison
Vendor-published scores; hover to inspect the source. Cross-harness results are directional.
About MCP Atlas: 1,000-task benchmark across 36 real MCP servers. Tests multi-step tool orchestration — calling the right API, in the right order, with the right parameters. Scale's April 2026 update replaced a 20-turn limit with a 100 tool-call budget and claims-based scoring.
⚠️ Methodology note: Scores below come from different vendors using their own evaluation scaffolds. Scores from different sources are NOT directly comparable — a 83.6% from Google's harness vs 83.3% from Anthropic's harness doesn't mean one model is definitively better. Within a single lab's table (e.g., Z.AI's cross-model table), scores ARE comparable.
🆕 Muse Spark 1.1 leads at 88.1% in Meta's official evaluation, ahead of Gemini 3.5 Flash's 83.6% vendor result. Kimi K3 scores 84.2% on Moonshot's 500-task public subset with a 100-turn limit and Gemini 3.1 Pro as judge. Because these use different subsets and scaffolds, the ordering is directional rather than a controlled head-to-head.
⚠️ Methodology note: Scores below come from different vendors using their own evaluation scaffolds. Scores from different sources are NOT directly comparable — a 83.6% from Google's harness vs 83.3% from Anthropic's harness doesn't mean one model is definitively better. Within a single lab's table (e.g., Z.AI's cross-model table), scores ARE comparable.
🆕 Muse Spark 1.1 leads at 88.1% in Meta's official evaluation, ahead of Gemini 3.5 Flash's 83.6% vendor result. Kimi K3 scores 84.2% on Moonshot's 500-task public subset with a 100-turn limit and Gemini 3.1 Pro as judge. Because these use different subsets and scaffolds, the ordering is directional rather than a controlled head-to-head.
Test tool orchestration on real MCP servers
20+ LLMs on CodingFleet. Run your own MCP tool chains. Benchmarks are directional — your codebase is the real test.
🚀 Try on CodingFleet →Sources & Links
- Meta Muse Spark 1.1 model page — MCP Atlas 88.1%, Terminal-Bench 2.1 80.0%, SWE-bench Pro 61.5%
- Moonshot AI Kimi K3 launch and benchmark table — MCP Atlas 84.2% on the 500-task public subset
- Anthropic System Card — Claude Fable 5 & Mythos 5 — Fable 5: 83.3%, Opus 4.8: 82.2% (Anthropic harness)
- Google Model Card — Gemini 3.5 Flash — 83.6% (Google harness)
- Z.AI Cross-Model Table (VentureBeat) — GLM-5.2, Opus 4.8, GPT-5.5, GLM-5.1, Gemini 3.1 Pro (Z.AI harness)
- Qwen Official Blog — Qwen 3.7 Max (76.4%), Opus 4.6 (Qwen harness)
- VentureBeat — MiniMax M3 analysis
- DeepSeek V4 Pro Model Card
- Scale SEAL MCP Atlas Leaderboard — standardized evaluation methodology
- Zvi Mowshowitz — Fable 5 & Mythos 5 capabilities