
Claude Opus 4.8 is the coding king — 69.2% SWE-bench Pro, 85.0% Terminal-Bench 2.1, #1 on the AA Intelligence Index. GLM-5.2 is the MIT upstart — 62.1% Pro, 81.0% TB 2.1, $4.40/1M output. Opus wins every shared benchmark. But on FrontierSWE, the gap is 0.7 points (75.1% vs 74.4%). On MCP Atlas, it's 0.8 points (77.8% vs 77.0%). A model that costs 5.7× less, with open MIT weights and Claude Code compatibility, is breathing down the neck of the most capable non-Mythos coding model in existence. LLM Stats' verdict: "GLM-5.2 is the first open-weights model to make Claude Opus 4.8 look expensive without making it look slow." Full comparison. Test both on CodingFleet.
TL;DR — Key Findings
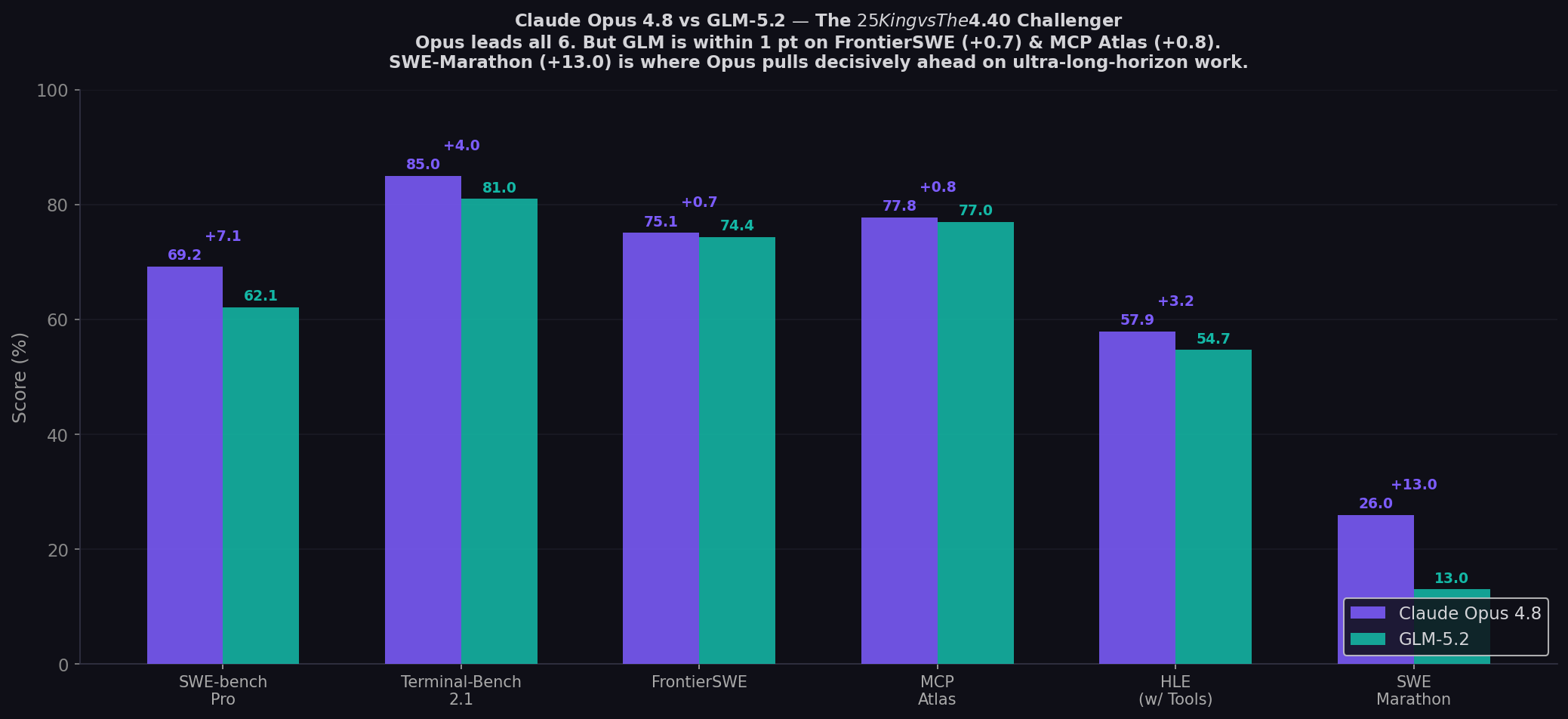
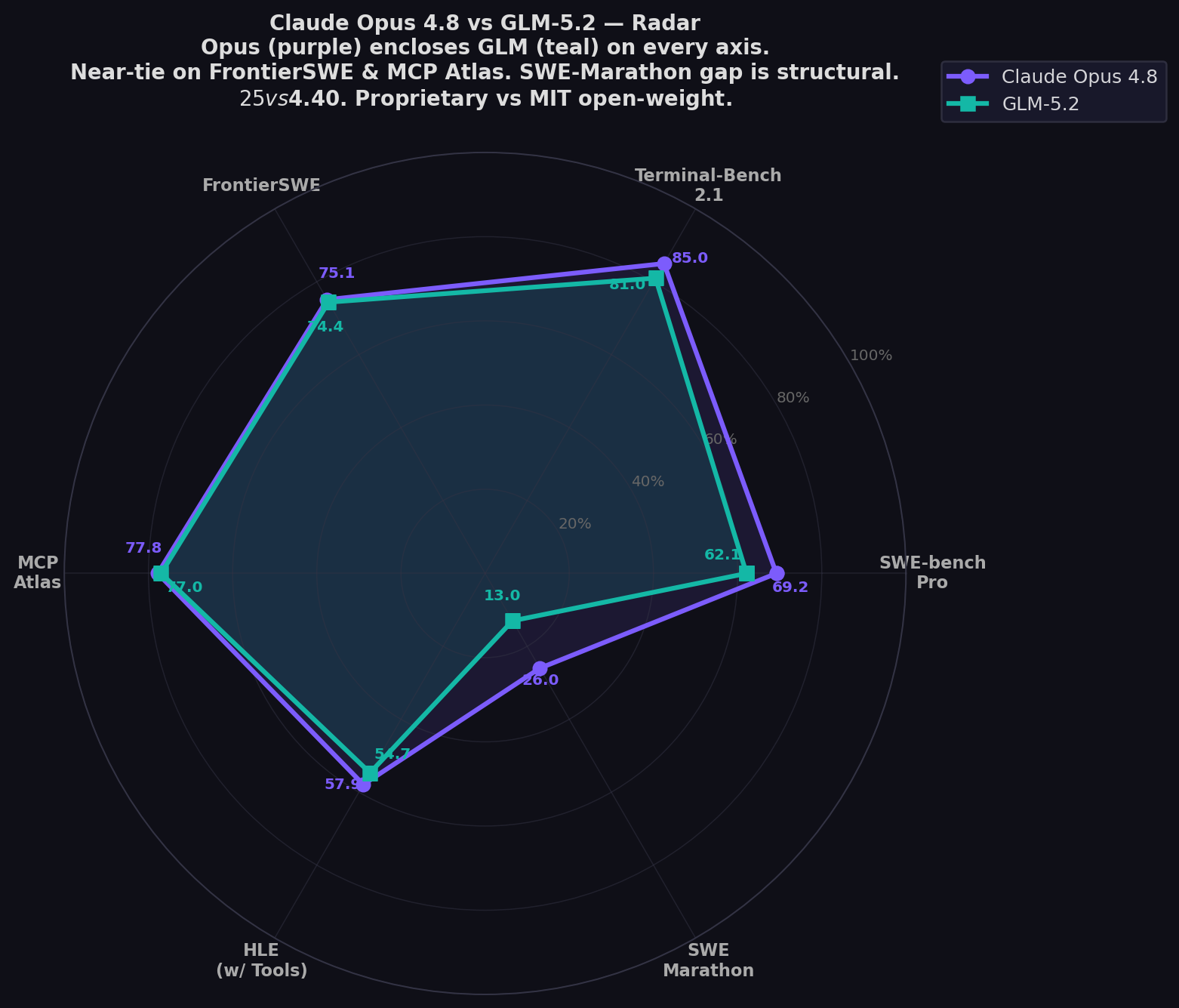
- Opus 4.8 leads every shared benchmark: Pro (+7.1), TB 2.1 (+4.0), HLE (+3.2), SWE-Marathon (+13.0), PostTrainBench (+2.9).
- But GLM-5.2 is within 1 point on two: FrontierSWE (+0.7), MCP Atlas (+0.8). Near-tie territory.
- 5.7× price gap: Opus $5/$25 vs GLM $1.40/$4.40 per 1M. At 100M output: Opus $2,500 vs GLM $440.
- GLM is MIT open-weight: Download from HuggingFace. Self-host. Fine-tune. Deploy air-gapped. Opus is proprietary only.
- SWE-Marathon gap is structural (+13.0): On ultra-long-horizon tasks, Opus's training and Claude Code infrastructure dominate.
- Both have 1M context, Anthropic API compatible: GLM drops into Claude Code natively. Both support adjustable thinking effort.
Try both models on CodingFleet
Benchmark Comparison
| Benchmark | Claude Opus 4.8 | GLM-5.2 | Winner |
|---|---|---|---|
| SWE-bench Pro ★ | 69.2% | 62.1% | Opus (+7.1) |
| Terminal-Bench 2.1 | 85.0% | 81.0% | Opus (+4.0) |
| FrontierSWE | 75.1% | 74.4% | Opus (+0.7 — near tie) |
| MCP Atlas | 77.8% | 77.0% | Opus (+0.8 — near tie) |
| HLE (with tools) | 57.9% | 54.7% | Opus (+3.2) |
| DeepSWE | 58.0% | 46.2% | Opus (+11.8) |
| PostTrainBench | 37.2% | 34.3% | Opus (+2.9) |
| SWE-Marathon | 26.0% | 13.0% | Opus (+13.0) |
| NL2Repo | 69.7% | 48.9% | Opus (+20.8) |
| ProgramBench | 71.9% | 63.7% | Opus (+8.2) |
| Tool-Decathlon | 59.9% | 48.2% | Opus (+11.7) |
| Output Price /1M tok | $25.00 | $4.40 | GLM (5.7× cheaper) |
| Input Price /1M tok | $5.00 | $1.40 | GLM (3.6× cheaper) |
Sources: GLM-5.2 scores from Z.AI cross-model table via VentureBeat | Opus 4.8 from Vellum & Anthropic system card | LLM Stats comparison. All scores vendor-reported from Z.AI's published cross-model table.
FrontierSWE: 0.7 Points From the King
The headline. GLM-5.2 at 74.4% vs Opus 4.8 at 75.1%. A 0.7-point gap on the benchmark designed to test long-horizon task completion. This is not a rounding error — it's a statement. An MIT-licensed model at $4.40/1M output is functionally tied with the $25/1M proprietary king on one of the hardest agentic coding benchmarks. VentureBeat: "GLM-5.2 hit 74.4%, surpassing GPT-5.5 (72.6%) and finishing in a near-tie with Claude Opus 4.8 (75.1%)." LLM Stats frames it perfectly: "GLM-5.2 closes to within a point on FrontierSWE and MCP-Atlas. It does this at $1.4/$4.4 per million tokens against Opus 4.8's $5/$25, with open MIT weights and a 1M context."
SWE-Marathon: The 13.0-Point Reality Check
The widest gap — and the one that defines where Opus justifies its premium. SWE-Marathon at 26.0% vs 13.0%. This benchmark tests ultra-long-horizon software engineering: project-scale tasks that require sustained reasoning across hours, not minutes. The SWE-Marathon paper describes it as testing whether "agents can autonomously complete ultra-long-horizon software work." Opus 4.8 doubles GLM-5.2's score. LLM Stats explains: "The moment tasks stretch to the marathon length Opus was tuned for, the closed model's lead roughly doubles. If your agents routinely run for hours, that is where you pay for Opus."
MCP Atlas: 0.8 Points — The Tool-Use Convergence
Opus at 77.8% vs GLM at 77.0%. On multi-step tool orchestration via MCP, these models are functionally identical. For developers building agent pipelines with complex tool chains, GLM-5.2 at 1/6 the cost delivers essentially the same reliability. This is the benchmark that most directly tests what AI agents actually do — chain tools together — and GLM-5.2 is statistically indistinguishable from the king.
Architecture & Ecosystem
| Feature | Claude Opus 4.8 | GLM-5.2 |
|---|---|---|
| Release Date | May 28, 2026 | June 13, 2026 |
| Developer | Anthropic | Z.ai (Beijing) |
| Parameters | Not disclosed | 753B (MoE) |
| Context Window | 1,000,000 tokens | 1,000,000 tokens |
| Max Output | 128K tokens | 131,072 tokens |
| Thinking Modes | High, xHigh, Max (3 levels) | High, Max (2 levels) |
| License | Proprietary | MIT (open weights on HuggingFace) |
| API Compatibility | Anthropic SDK, Claude Code native | Anthropic API — Claude Code compatible |
| Agent Ecosystem | Claude Code, MCP native, Dynamic Workflows, Agent Teams | Claude Code, Cline, OpenClaw, Kilo Code |
| Self-Hosting | No | Yes — MIT, HuggingFace, vLLM/SGLang |
| Best at | Ultra-long-horizon SWE, deep reasoning, tool orchestration | Cost-efficient coding, self-hosted deployment, Claude Code replacement |
Which Model Should You Use?
| Use Case | Winner | Why |
|---|---|---|
| Hardest bug fixing | Opus ✅ | +7.1 Pro. Still the most reliable non-Mythos coder |
| Ultra-long-horizon tasks | Opus ✅ | +13.0 SWE-Marathon. Hours-long agents need Opus |
| Deep multi-file refactors | Opus ✅ | +11.8 DeepSWE, +20.8 NL2Repo. Structural advantage |
| Long-horizon engineering | ⚖️ Near tie | +0.7 FrontierSWE. Functionally identical |
| Tool orchestration (MCP) | ⚖️ Near tie | +0.8 MCP Atlas. Same reliability at 1/6 cost |
| Self-hosting / air-gapped | GLM ✅ | MIT license. HuggingFace. No API dependency |
| Budget / high-volume | GLM ✅ | 5.7× cheaper API. GLM Coding Plan from $3/mo |
| Claude Code replacement | GLM ✅ | Drop-in. Swap base URL + model ID. Same harness |
Conclusion: The King Still Reigns — But the Court Costs 6× Less
Claude Opus 4.8 is the better model. It leads every shared benchmark — often by significant margins on the hardest tests (SWE-Marathon +13.0, DeepSWE +11.8, NL2Repo +20.8). For teams building production coding agents where correctness on ultra-long-horizon tasks justifies the premium, Opus remains the safe choice.
But GLM-5.2 has done something no open-weight model has before: closed to within a single point of the proprietary king on two of the most important agentic benchmarks (FrontierSWE and MCP Atlas). At 5.7× lower cost, with MIT open weights and native Claude Code compatibility. LLM Stats' verdict: "Pick Opus 4.8 for the agentic SWE ceiling; pick GLM-5.2 when cost, self-hosting, or open weights matter more than the last few points."
Julian Goldie (400K YouTube subscribers) tested both models head-to-head on real coding tasks — a voxel runner, an orbit simulation, a landing page, an arcade game. Result: GLM-5.2 won 4 out of 5 tests, producing "the most fun, polished, and feature-rich results." Opus won the solar-system orbit map. Benchmarks favor the king. But real-world building? The gap is smaller than the leaderboards suggest.
💡 The Bottom Line
You don't have to choose. The smartest teams run Opus for the 20% of tasks where the benchmark gap matters — and GLM-5.2 for the other 80%. At $440 vs $2,500 per 100M output tokens, the math is simple. Generate code with both on CodingFleet — your sandbox stays running even when your laptop goes to sleep.
Sources & Links
- LLM Stats — GLM-5.2 vs Claude Opus 4.8 full comparison
- VentureBeat — GLM-5.2 beats GPT-5.5, near-ties Opus 4.8
- Vellum — Claude Opus 4.8 benchmarks explained
- SWE-Marathon paper — ultra-long-horizon software engineering
- Julian Goldie (400K) — GLM-5.2 vs Opus 4.8 vs Kimi K2.7
- Julian Goldie (400K) — GLM-5.2 destroys Claude?
- MorphLLM — SWE-bench Pro leaderboard
- MarkTechPost — GLM-5.2 launch details
Read This Next
- GLM-5.2 vs GPT-5.5 — MIT open-weight beats OpenAI on Pro
- SWE-bench Pro Leaderboard — every model ranked
- AI Model Pricing Calculator — compare real costs