🆕 Updated June 9, 2026: Claude Fable 5 launched — 93.9% SWE-bench Verified, 80.3% SWE-bench Pro, 88.0% Terminal-Bench 2.1. The first Mythos-class model available to everyone. First model to break 90% Verified. First to break 80% Pro. First to break 85% Terminal-Bench — taking the crown from GPT-5.5, which had dominated CLI coding at 83.4%. $10/$50 per 1M tokens. This is the story of the most intense period of progress in AI history. Test all models on CodingFleet.
🆕 Claude Fable 5 — The Mythos Milestone
June 9, 2026: Anthropic's first publicly available Mythos-class model. Same underlying model as Claude Mythos 5 (restricted). 93.9% SWE-bench Verified (+5.3 over Opus 4.8), 80.3% SWE-bench Pro (+11.1), 88.0% Terminal-Bench 2.1 (+4.6 over GPT-5.5 — dethrones the former CLI king). First model above 90% Verified. First above 80% Pro. Price: $10/$50 per 1M. Safety classifiers on cyber/bio/chemistry queries fall back to Opus 4.8 (~5% of sessions). See full leaderboard →
In March 2024, Claude 3 Opus scored 33.4% on SWE-bench Verified — the best available. It cost $75 per million output tokens. Twenty-seven months later, Claude Fable 5 scores 93.9% — a 60.5-point leap. But the price story split: OpenAI's GPT-5.5 doubled to $30, Anthropic launched Fable 5 at $50, while DeepSeek V4 Pro collapsed to $0.87. The gap between cheapest frontier and most expensive is now 57×.
📊 Key Milestones
- Mar 2024: Claude 3 Opus scores 33.4% on SWE-bench Verified at $75/1M output. The starting line.
- Oct 2025: Claude Opus 4.5 breaks 80% for the first time (80.9%). Anthropic cuts Opus price from $75 to $25.
- Feb 2026: OpenAI stops reporting Verified scores — contamination confirmed. SWE-bench Pro becomes the trusted benchmark.
- Apr 2026: Claude Opus 4.7 at 87.6%. GPT-5.5 launches and dominates Terminal-Bench at 83.4% — a record that stands until Fable 5.
- May 2026: DeepSeek makes 75% discount permanent: $0.87/1M. Claude Opus 4.8 at 88.6% Verified, 69.2% Pro.
- 🆕 Jun 9, 2026: Claude Fable 5 — first model above 90% Verified (93.9%), first above 80% Pro (80.3%), first above 85% Terminal-Bench (88.0%), dethroning GPT-5.5 as CLI king. 57× spread vs DeepSeek V4 Pro.
The SWE-bench Verified Ascent: From 33.4% to 93.9%
SWE-bench Verified — 500 real GitHub issues from 12 Python repositories — has been the industry's north star since August 2024. Claude has held the record at all 8 competitive checkpoints:
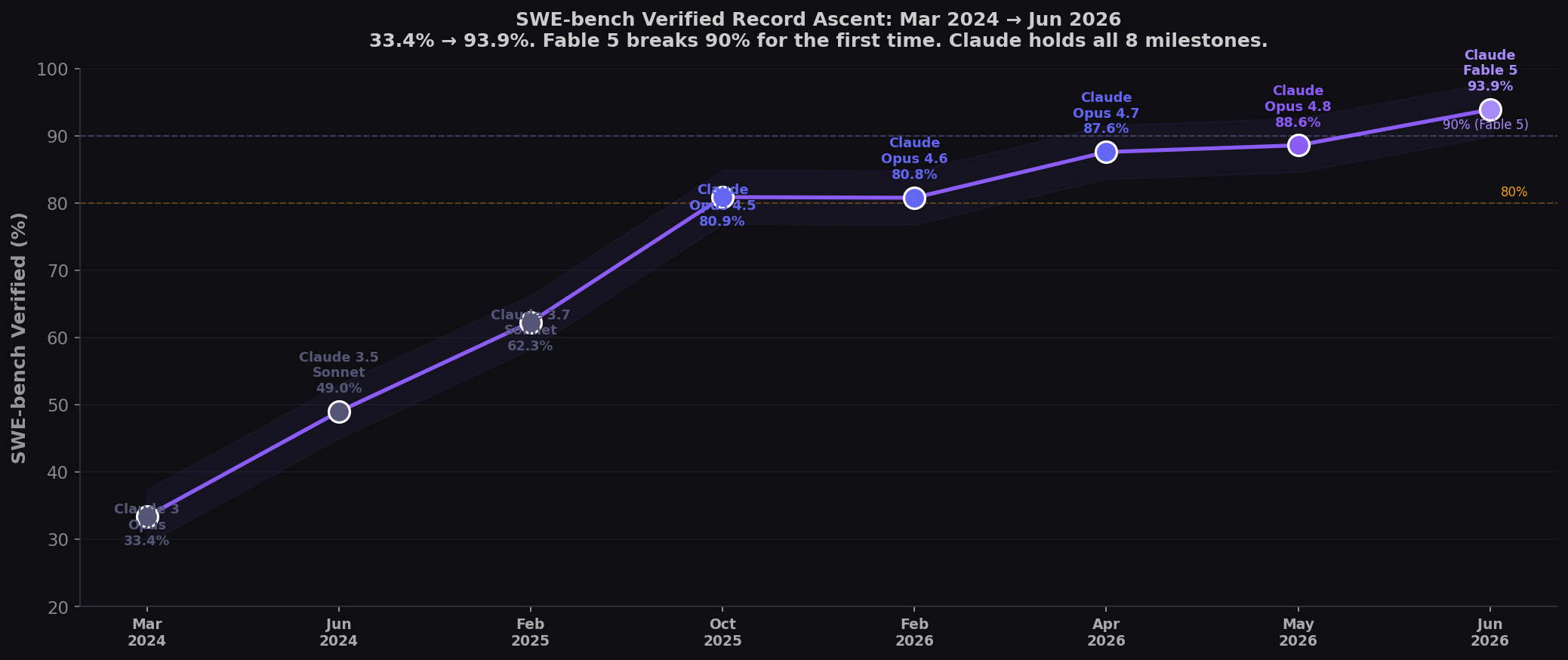
| Date | Record-Setting Model | SWE-bench Verified | Significance |
|---|---|---|---|
| Mar 2024 | Claude 3 Opus | 33.4% | Starting line. |
| Jun 2024 | Claude 3.5 Sonnet | 49.0% | First near 50%. |
| Feb 2025 | Claude 3.7 Sonnet | 62.3% | First to break 60%. |
| Oct 2025 | Claude Opus 4.5 | 80.9% | First to break 80%. Anthropic cuts Opus 67%. |
| Feb 2026 | Claude Opus 4.6 | 80.8% | Verified saturating. OpenAI withdraws. |
| Apr 2026 | Claude Opus 4.7 | 87.6% | Biggest jump before Fable 5. |
| May 2026 | Claude Opus 4.8 | 88.6% | Former record. |
| 🆕 Jun 2026 | Claude Fable 5 | 93.9% | First above 90%. Mythos-class. |
The Three-Lane Race: Claude vs GPT-5.5
By late 2025, a single benchmark was no longer sufficient. SWE-bench Pro launched as the contamination-resistant successor. Terminal-Bench emerged as the standard for CLI coding. GPT-5.5 dominated Terminal-Bench from April 2026 at 83.4% — until Fable 5 arrived at 88.0% and took the crown. Here's the full timeline:
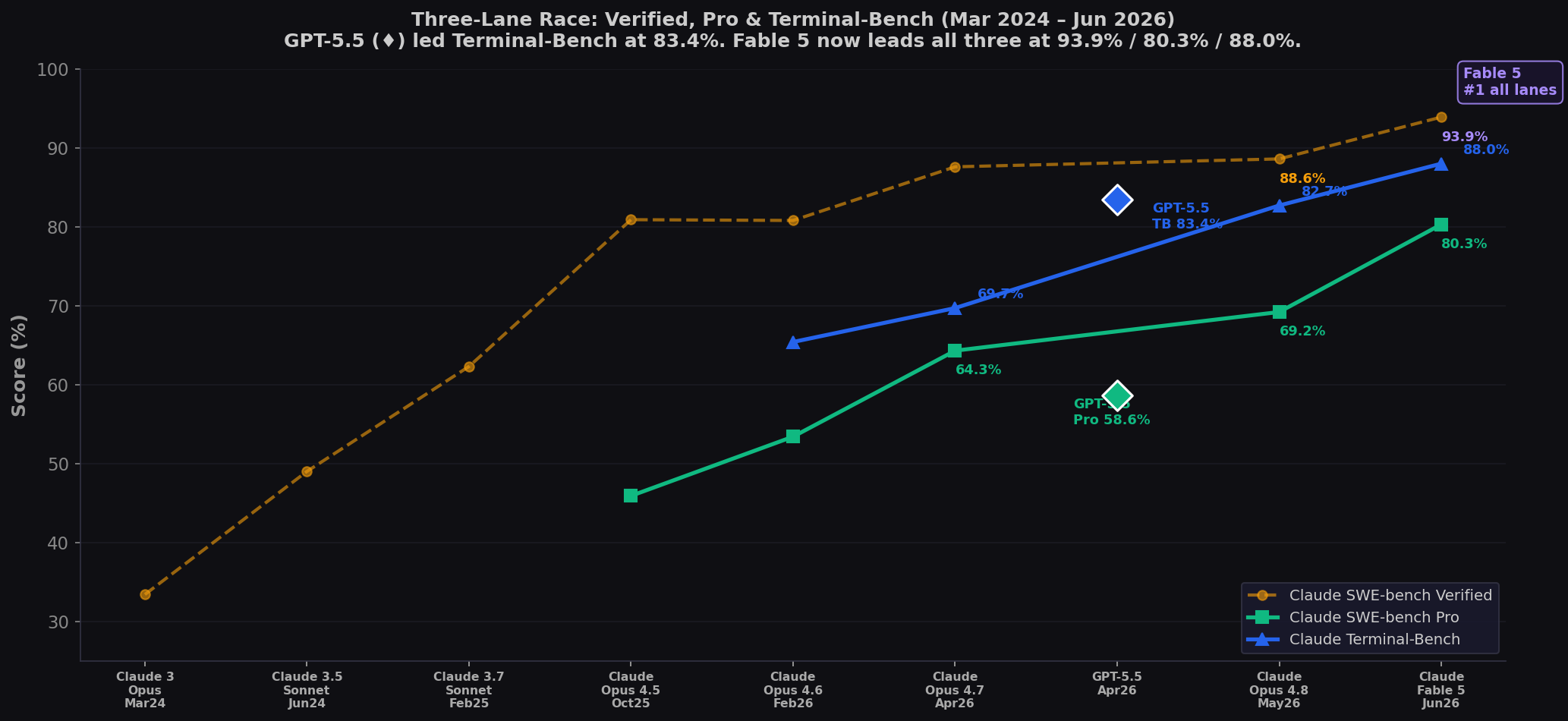
Claude owns Verified (yellow) and Pro (green). GPT-5.5 (♦ markers) entered in April 2026 and immediately led Terminal-Bench at 83.4% — holding that position for 47 days until Fable 5's 88.0% in June. Fable 5 now leads all three lanes.
Fable 5 vs Previous Champions
| Benchmark | Claude Fable 5 | Previous Best | Gap |
|---|---|---|---|
| SWE-bench Pro | 80.3% | Opus 4.8 (69.2%) | +11.1 |
| Terminal-Bench 2.1 | 88.0% | GPT-5.5 (83.4%) | +4.6 |
| SWE-bench Verified | 93.9% | Opus 4.8 (88.6%) | +5.3 |
| GPQA Diamond | 94.5% | Gemini 3.1 Pro (94.3%) | +0.2 |
| HLE (no tools) | 56.8% | Gemini 3.1 Pro (44.4%) | +12.4 |
| FrontierCode Diamond | 29.3% | Opus 4.8 (13.4%) | +15.9 |
Pricing: Premium $50, Stable $30, Freefall $0.87
Three diverging strategies: OpenAI holding at $30, Anthropic launching a premium $50 Mythos tier, open-weight collapsing below $1:
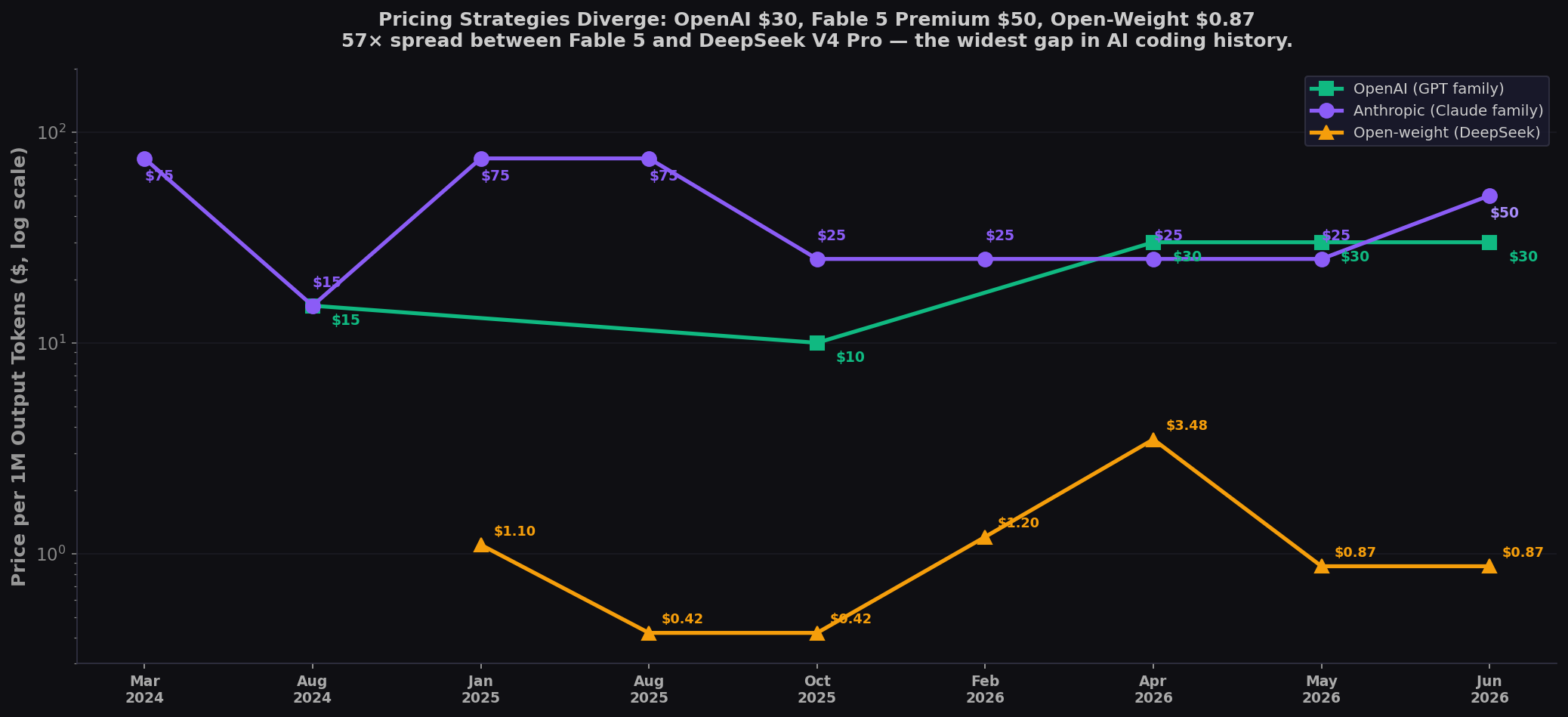
| Date | Highest-Priced | $/1M | Lowest (Frontier) | $/1M | Spread |
|---|---|---|---|---|---|
| Mar 2024 | Claude 3 Opus | $75.00 | — | — | — |
| Jan 2025 | Claude Opus 4.1 | $75.00 | DeepSeek V3 | $1.10 | 68× |
| Oct 2025 | Claude Opus 4.5 | $25.00 | DeepSeek V3.2 | $0.42 | 60× |
| May 2026 | GPT-5.5 | $30.00 | DeepSeek V4 Pro | $0.87 | 34× |
| 🆕 Jun 2026 | Claude Fable 5 | $50.00 | DeepSeek V4 Pro | $0.87 | 57× |
The 27 Months That Changed Everything
In March 2024, AI coding was an experiment: 33.4% Verified, $75/1M, no open-weight alternatives. In June 2026, AI coding is infrastructure. The best model scores 93.9% Verified, 80.3% Pro, 88.0% Terminal-Bench. Open-weight delivers frontier-adjacent coding at $0.87/1M. Premium Mythos-class capability costs $50/1M. GPT-5.5's 47-day Terminal-Bench reign is over. Fable 5 leads every lane.
Sources: Anthropic Fable 5 Announcement (Jun 9, 2026) | Vals.ai | SWE-bench Official | DeepSeek V4 Model Card. Fable 5/Mythos 5 share the same model. Verified score from Mythos Preview system card — Anthropic has not published a separate Fable 5 Verified score. ⚠️ Verified contaminated per OpenAI (Feb 2026).