
Here's a scenario every heavy AI coding user knows: you start the month on Claude Opus 4.8. It's brilliant — 69.2% on SWE-bench Pro, the best coding model in the world. You code all day. Your agent runs overnight. You refactor entire codebases. Then the bill arrives: $2,000–$5,000. For a single developer. And you realize the real bottleneck in AI-assisted coding isn't intelligence — it's cost per token. The good news: a new generation of open-weight models delivers 80–95% of flagship coding performance at 2–5% of the price. This is the stack that replaces a $5,000/month Opus habit with a $200/month multi-model setup — without feeling the downgrade.
📊 Key Findings
- A heavy user on Claude Opus 4.8 at 200M output tokens/month pays ~$5,000. The same workload on DeepSeek V4 Pro: $174. That's a 96.5% reduction — for a 13.8-point SWE-bench Pro gap.
- DeepSeek V4 Pro's 75% discount is now permanent. $0.435 input, $0.87 output per 1M tokens. Announced May 22, 2026. This is the new price floor for frontier-tier coding models.
- MiniMax M2.7 is the efficiency-per-parameter champion. 10B active params, 56.22% SWE-bench Pro, $1.20/1M output. The best coding-per-dollar of any model with published benchmarks.
- Kimi K2.6 is the best open-weight coder — period. 58.6% SWE-bench Pro, 89.6% LiveCodeBench, 66.7% Terminal-Bench. The #1 open-weight model on AA Intelligence Index at 54.
- You don't need to pick one model. The optimal stack routes tasks by complexity: Kimi for hard problems, DeepSeek for volume, MiniMax for boilerplate. Total monthly cost: ~$200 for whale-level usage.
All models in this analysis are available on CodingFleet. Build your stack →
The $5,000 Problem: What Heavy Usage Actually Costs
Let's define "heavy user." This is someone running AI-assisted coding daily — agentic workflows, multi-file refactors, test generation, overnight autonomous runs. They burn through tokens at rates that make per-1M pricing the dominant factor in their AI bill.
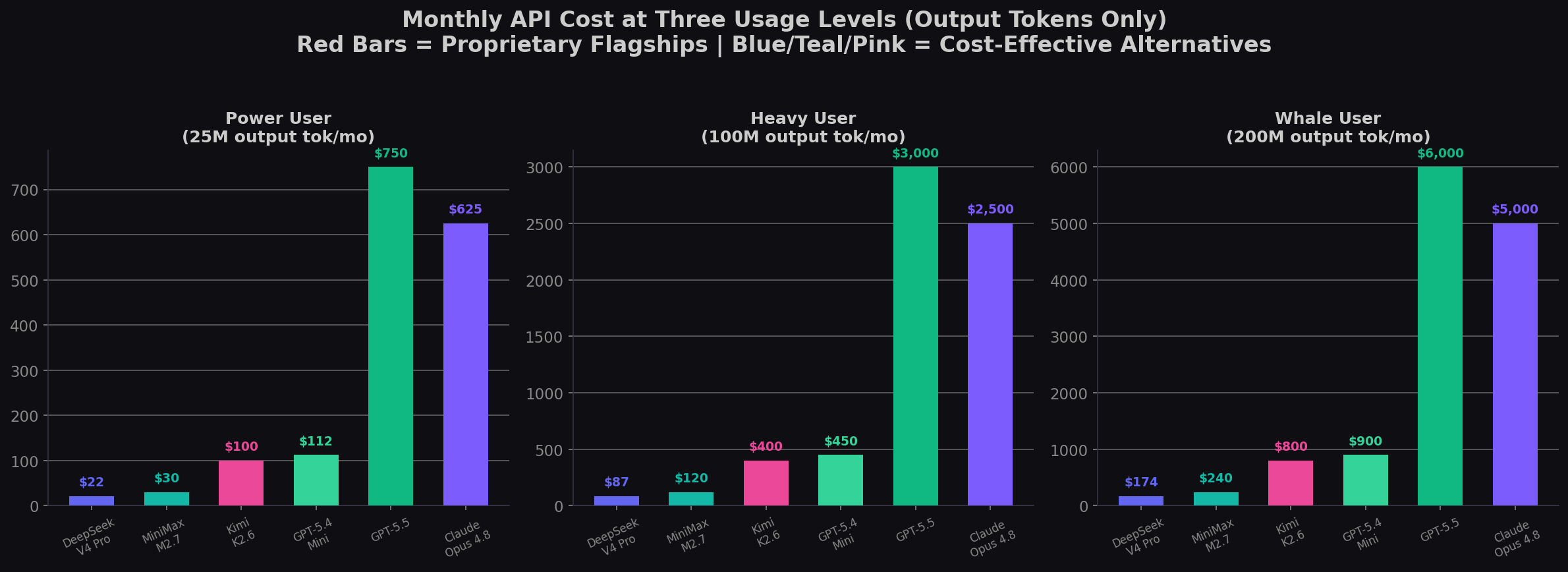
| Model | Output $/1M | 25M/mo | 100M/mo | 200M/mo |
|---|---|---|---|---|
| DeepSeek V4 Pro | $0.87 | $22 | $87 | $174 |
| MiniMax M2.7 | $1.20 | $30 | $120 | $240 |
| Kimi K2.6 | $4.00 | $100 | $400 | $800 |
| GPT-5.4 Mini | $4.50 | $113 | $450 | $900 |
| Gemini 3.5 Flash | $9.00 | $225 | $900 | $1,800 |
| GPT-5.4 | $15.00 | $375 | $1,500 | $3,000 |
| Claude Opus 4.8 | $25.00 | $625 | $2,500 | $5,000 |
| GPT-5.5 | $30.00 | $750 | $3,000 | $6,000 |
Prices as of May 31, 2026. DeepSeek V4 Pro at permanent 75% discount rate. Sources: DeepSeek pricing; OpenRouter; TokenMix.
The math is brutal. At 200M output tokens per month — a realistic number for someone running Claude Code or Codex agentic workflows daily — GPT-5.5 costs $6,000 while DeepSeek V4 Pro costs $174. That's a 34× price difference. The question isn't whether DeepSeek is as good as GPT-5.5. The question is whether GPT-5.5 is 34× better. It's not.
DeepSeek V4 Pro: The Permanent 75% Discount
On May 22, 2026, DeepSeek announced that its 75% promotional discount would become permanent. The pricing that was supposed to expire on May 31 is now the standard rate:
| Token Type | Original Price | Permanent Price | Discount |
|---|---|---|---|
| Input (cache miss) | $1.74/1M | $0.435/1M | 75% |
| Input (cached) | $0.0145/1M | $0.003625/1M | 75% |
| Output | $3.48/1M | $0.87/1M | 75% |
This is DeepSeek's playbook: launch at a reference price, offer a "temporary" discount, then make it permanent. The result: a frontier-tier coding model at 2% of GPT-5.5's output price. Context: 1M tokens. Max output: 384K tokens. License: MIT.
🔧 How DeepSeek Made 1M-Context Affordable
DeepSeek rebuilt the architecture to make long-context inference radically cheaper:
- Hybrid Attention (CSA + HCA): Compressed Sparse Attention handles precise lookups; Heavily Compressed Attention handles global signal. At 1M-token context, V4 Pro uses 27% of the FLOPs and 10% of the KV cache of its predecessor — a 10× memory reduction.
- Manifold-Constrained Hyper-Connections (mHC): Stabilizes signal across the deep network so hybrid attention layers can learn which variant to use at each depth.
- Muon Optimizer at 1.6T scale: First deployment on a trillion-parameter MoE. Faster convergence and better stability than AdamW.
- FP4 + FP8 Mixed Precision: Expert parameters in FP4, most others in FP8. Maximizes memory efficiency without degrading output.
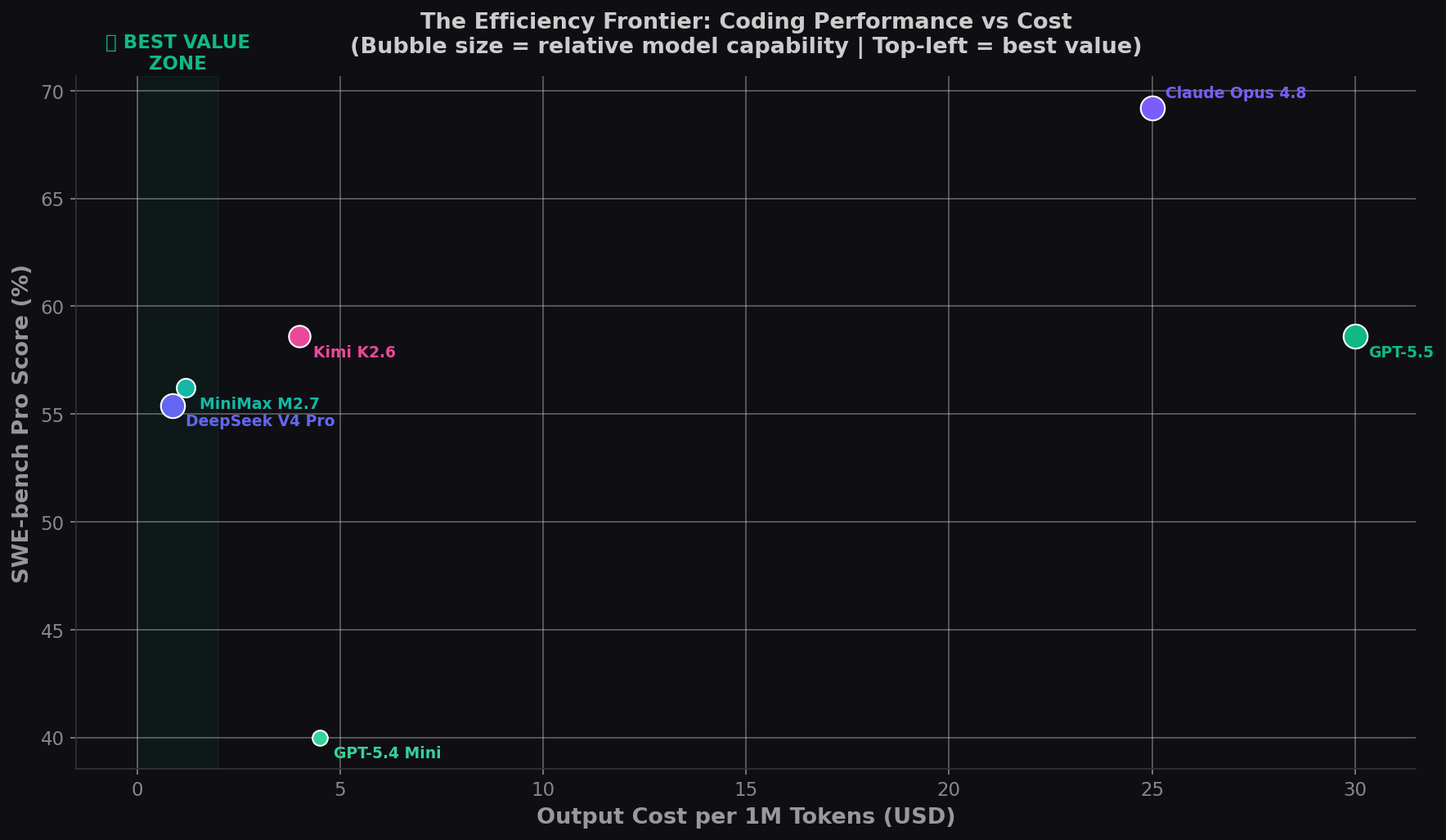
Benchmarks: What You Give Up for the Savings
| Model | SWE-bench Pro ★ | Terminal-Bench | LiveCodeBench | AA Intel Index | Output $/1M |
|---|---|---|---|---|---|
| Claude Opus 4.8 | 69.2% | — | — | — | $25.00 |
| GPT-5.5 | 58.6% | 78.2% | 56% | 60 | $30.00 |
| Kimi K2.6 | 58.6% | 66.7% | 89.6% | 54 | $4.00 |
| MiniMax M2.7 | 56.22% | 57.0% | — | 50 | $1.20 |
| DeepSeek V4 Pro Max | 55.4% | 67.9% | 93.5% | 52 | $0.87 |
| GPT-5.4 Mini | — | — | — | — | $4.50 |
Sources: DeepSeek V4 Pro; Kimi K2.6; MiniMax M2; OpenAI/Anthropic system cards.
The headline: Kimi K2.6 matches GPT-5.5 on SWE-bench Pro (58.6% vs 58.6%) at 7.5× lower cost. DeepSeek V4 Pro scores 55.4% — within 3.2 points — at 34× lower cost.
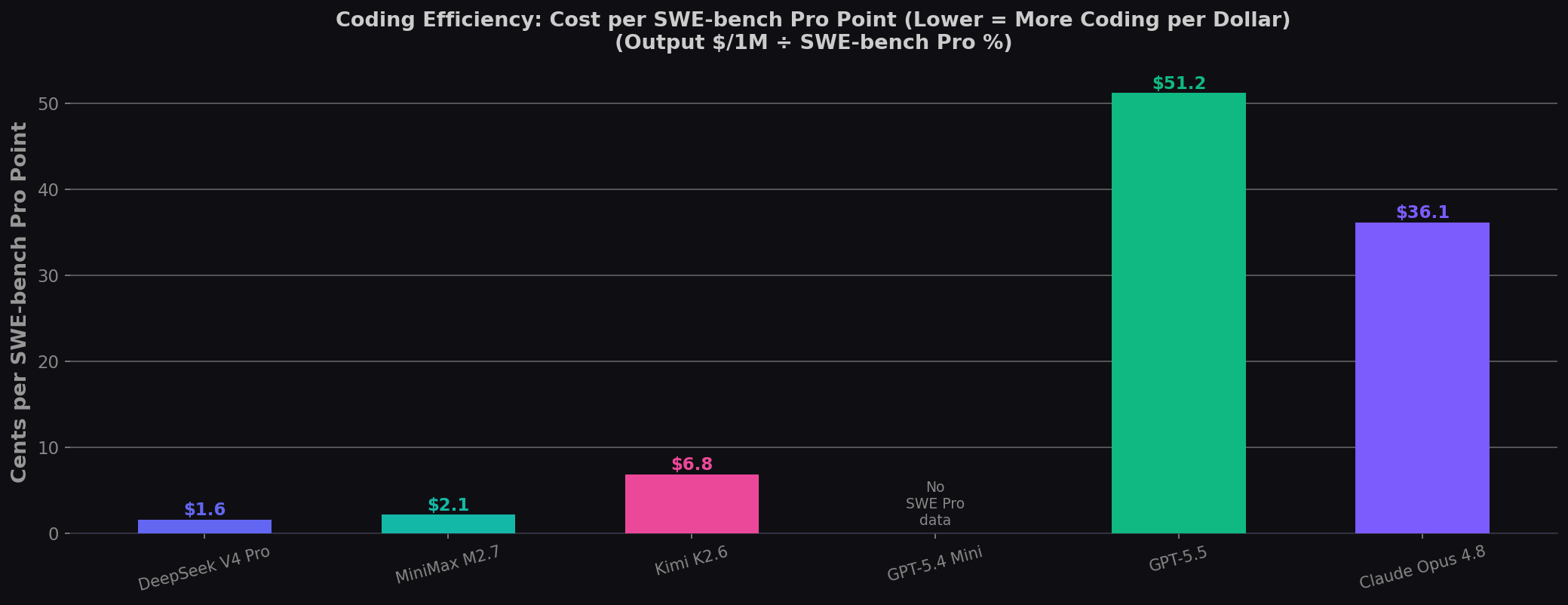
Cost per SWE-bench Pro point — the single most useful metric for heavy users:
| Model | SWE-bench Pro | Output $/1M | $ per Pro Point | vs GPT-5.5 |
|---|---|---|---|---|
| DeepSeek V4 Pro | 55.4% | $0.87 | $1.57 | 32.5× cheaper |
| MiniMax M2.7 | 56.22% | $1.20 | $2.13 | 24× cheaper |
| Kimi K2.6 | 58.6% | $4.00 | $6.83 | 7.5× cheaper |
| Claude Opus 4.8 | 69.2% | $25.00 | $36.13 | 1.4× cheaper |
| GPT-5.5 | 58.6% | $30.00 | $51.19 | Baseline |
The Optimal Heavy User Stack
The strategy: a tiered stack routing tasks by complexity:
| Tier | Model | Use For | Monthly Cost (100M tok) |
|---|---|---|---|
| Primary Workhorse | Kimi K2.6 | Complex bug fixes, multi-file refactors, agentic coding | $400 |
| Volume Runner | DeepSeek V4 Pro | High-volume code gen, test generation, boilerplate, overnight agents | $87 |
| Budget Fill | MiniMax M2.7 | Simple completions, documentation, code review | $120 |
Total stack cost at 100M output tokens/month: ~$200–$600 depending on routing ratios. Compare to $2,500 on Claude Opus 4.8 or $3,000 on GPT-5.5. Savings: 80–93%.
When to Still Pay for Flagships
The cost-effective models aren't always right. Pay for GPT-5.5 or Claude Opus 4.8 when:
- Terminal/CLI automation is your primary workflow. GPT-5.5 at 78.2% Terminal-Bench is 10+ points ahead of any alternative.
- You need the absolute best multi-file debugging. Claude Opus 4.8 at 69.2% SWE-bench Pro. For mission-critical bugs, the premium pays for itself.
- Long-context retrieval above 500K tokens. GPT-5.5 at 74.0% MRCR v2 at 512K–1M is unmatched.
Route the 10% of tasks that need flagship intelligence to Opus or GPT-5.5. Route the 90% to DeepSeek, MiniMax, and Kimi. Your bill drops from $5,000 to $500.
The Bottom Line
- The AI coding cost crisis is solvable. A tiered stack delivers 80–95% of flagship performance for 3–7% of the cost.
- DeepSeek V4 Pro at $0.87/1M is the new price floor. Permanent. MIT license. 1M context. 32.5× cheaper than GPT-5.5 per coding point.
- Kimi K2.6 matches GPT-5.5 on SWE-bench Pro at 7.5× lower cost. Best open-weight coder.
- Use flagships surgically. 90% cost-effective models + 10% flagship = $500/month instead of $5,000.
Sources: DeepSeek — Permanent 75% Discount | DeepSeek V4 Pro Model Card | Codersera Analysis | TokenMix Pricing | Acing AI Architecture | Kimi K2.6 | MiniMax M2 | AA M2.7. All prices May 31, 2026.