
✅ ACCESS RESTORED — July 1, 2026
The US government lifted the export control directive on July 1, 2026. Anthropic has restored full access to Claude Fable 5 and Mythos 5 for all customers. Both models are available again at their original pricing ($10/$50 per 1M for Fable 5).
📜 What happened? (June 12–30, 2026 suspension history)
On Friday evening, June 12, 2026, the US government issued an export control directive ordering Anthropic to suspend all access to Fable 5 and Mythos 5 for all customers. The government cited a narrow, non-universal jailbreak technique — essentially asking the model to read a specific codebase and fix software flaws. Anthropic strongly disagreed with the decision, noting that "this level of capability is widely available from other models (including OpenAI's GPT-5.5) and is used every day by the defenders who keep systems safe." Access to all other Anthropic models (Opus 4.8, Sonnet 4.6, Haiku 4.5) was not affected. After 19 days, the export control was lifted and access restored on July 1, 2026. All benchmarks, pricing, and analysis in this article reflect Fable 5 as it existed during its initial GA period (June 9–12, 2026).
June 9, 2026. Anthropic releases Claude Fable 5 — the first Mythos-class model available to the general public. The same underlying model as the restricted Claude Mythos 5, now with safety classifiers that fall back to Opus 4.8 on ~5% of queries. 80.3% SWE-bench Pro. 88.0% Terminal-Bench. 93.9% SWE-bench Verified. Stripe ran a 50-million-line Ruby migration in one day — work estimated at over two months for a full team. Karpathy called it "a major-version-bump-deserving step change forward." Simon Willison called it "a beast." This is everything you need to know. Test Fable 5 on CodingFleet.
🔮 What the World Is Saying
"A major-version-bump-deserving step change forward, especially on long difficult tasks."
— Andrej Karpathy, former Tesla AI Director, OpenAI co-founder
"This is something of a beast. It's slow, expensive, and has been quite happily churning through everything I've thrown at it."
— Simon Willison, creator of Datasette, AI commentator
"The state of the art model on CursorBench. Opened up a class of long-horizon problems that were out of reach for earlier models."
— Michael Truell, CEO of Cursor
"Yeah… this feels next level. One shot. Fully editable. Native WordPress patterns."
— Jamie Marsland, WordPress developer, after building a block theme in one prompt
What Is Claude Fable 5?
Fable 5 is a Mythos-class model — Anthropic's new capability tier that sits above Opus. It shares the same underlying architecture and weights as Claude Mythos 5 (restricted to Project Glasswing cyber defense partners and soon select biology researchers). The difference: Fable 5 has safety classifiers that redirect queries on cybersecurity, biology/chemistry, and distillation topics to Claude Opus 4.8 instead.
The name "Fable" (from Latin fabula, "that which is told") signals that this is the version of Mythos-class intelligence that Anthropic is comfortable telling the world about. Mythos 5 — the unrestricted variant — scored 78.0% on ExploitBench (vs Opus 4.8 at 40.0%) and 83.8% on CyberGym. Fable 5 gives you the same intelligence, minus the cyber superpowers.
| Spec | Claude Fable 5 |
|---|---|
| Model class | Mythos-class (above Opus) |
| API string | claude-fable-5 |
| Context window | 1,000,000 tokens |
| Input modalities | Text, images, files |
| Reasoning effort levels | Low, Medium, High, XHigh, Max |
| Input price | $10 / million tokens |
| Output price | $50 / million tokens |
| Prompt caching | 90% discount on cached input |
| Batch/Flex | 50% discount |
| Released | June 9, 2026 |
| Subscription plans | Free on Pro/Max/Team/Enterprise through June 22 |
The Benchmarks: Every Number That Matters
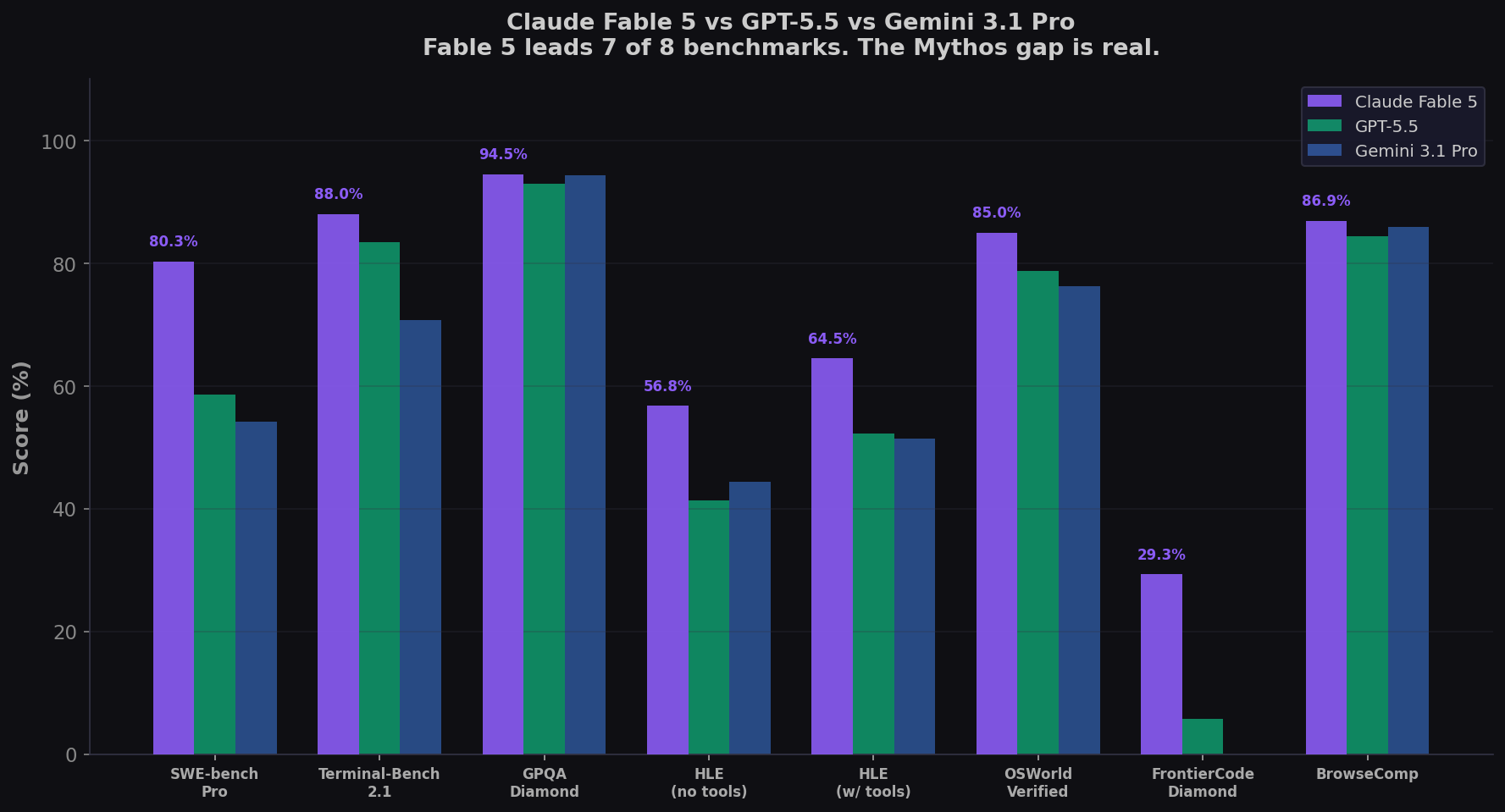
| Benchmark | Fable 5 | Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro | Fable 5 Lead |
|---|---|---|---|---|---|
| SWE-bench Pro | 80.3% | 69.2% | 58.6% | 54.2% | +11.1 |
| Terminal-Bench 2.1 | 88.0% | 82.7% | 83.4% | 70.7% | +4.6 |
| GPQA Diamond | 94.5% | 91.3% | 93.0% | 94.3% | +0.2 |
| HLE (no tools) | 56.8% | 49.8% | 41.4% | 44.4% | +7.0 |
| HLE (with tools) | 64.5% | 57.9% | 52.2% | 51.4% | +6.6 |
| OSWorld-Verified | 85.0% | 83.4% | 78.7% | 76.2% | +1.6 |
| FrontierCode Diamond | 29.3% | 13.4% | 5.7% | — | +15.9 |
| GDPval-AA | 1932 | 1890 | 1769 | 1314 | +42 |
| Legal Agent Benchmark | 13.3% | 10.4% | 2.1% | 0.0% | +2.9 |
| Blueprint-Bench 2 | 38.6% | 14.5% | 36.2% | 26.5% | +2.4 |
Source: Anthropic Fable 5 Announcement. All scores vendor-reported. Fable 5/Mythos 5 share the same model. Terminal-Bench 2.1: Anthropic-reported numbers. GTP-5.5 Pro: BrowseComp 90.1%, FrontierMath T4 39.6% — Pro variant has separate published scores on select benchmarks.
Fable 5 leads 9 of 10 benchmarks vs GPT-5.5. The only near-tie is GPQA Diamond (94.5% vs 93.0%). On the benchmarks that matter most for coding — SWE-bench Pro (+21.7), Terminal-Bench (+4.6), FrontierCode (+23.6) — the gap is a canyon. On spatial reasoning (Blueprint-Bench 2), Fable 5 nearly triples Opus 4.8 (38.6% vs 14.5%). On legal reasoning, it more than doubles the nearest competitor.
The Biggest Leap in Claude History
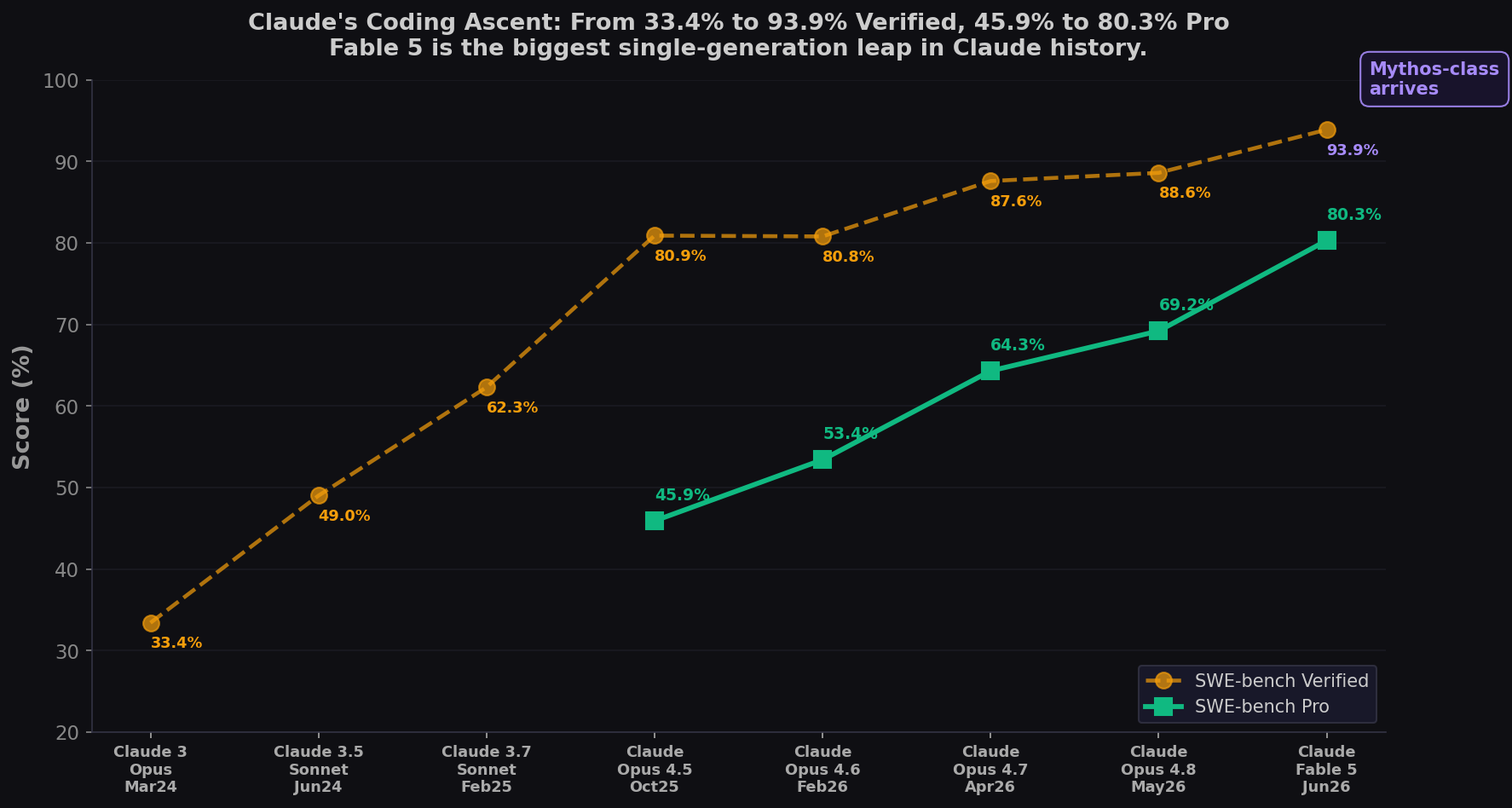
Claude has held the SWE-bench Verified record at every competitive milestone — 8 out of 8. The trajectory: 33.4% → 49.0% → 62.3% → 80.9% → 87.6% → 88.6% → 93.9%. On Pro (green), the pattern is even starker: 45.9% → 53.4% → 64.3% → 69.2% → 80.3%. The +11.1 Pro jump from Opus 4.8 to Fable 5 is the largest single-generation leap in Pro history — and the first time any model has crossed 80%.
The Stripe Story: 50 Million Lines in One Day
The most cited real-world result from Fable 5's early testing comes from Stripe. In a 50-million-line Ruby codebase, Fable 5 performed a codebase-wide migration in a single day. Stripe estimated the same task would have taken a full team over two months by hand. That's roughly a 60× acceleration — compressing 1,200+ person-hours into roughly 20 hours of autonomous AI work.
This isn't a benchmark. This is production infrastructure. Stripe's codebase handles billions of dollars in payments. The migration wasn't a toy problem — it was real engineering at scale. Anthropic's announcement notes that Fable 5 is "more token-efficient than past Claude models" on this kind of work, scoring highest among frontier models on Cognition's FrontierCode evaluation even at medium reasoning effort.
The Safety Architecture: A New Kind of Deployment
Fable 5 introduces a deployment model that has never existed before: the same underlying model, served with different safety profiles.
| Claude Fable 5 | Claude Mythos 5 | |
|---|---|---|
| Underlying model | Identical | |
| Cybersecurity queries | → Falls back to Opus 4.8 | Full capability |
| Biology/chemistry queries | → Falls back to Opus 4.8 | Full capability (soon) |
| Distillation queries | → Falls back to Opus 4.8 | Full capability |
| Everything else | Full Mythos-class capability | |
| Availability | Everyone today | Glasswing partners only |
| Fallback rate | ~5% of sessions | N/A |
The classifiers trigger on fewer than 5% of sessions. Anthropic ran an external bug bounty that produced zero universal jailbreaks in over 1,000 hours of testing. The UK AISI made progress toward one in a brief testing window but no full break. External red-teaming organizations also failed to find universal jailbreaks on long-form agentic tasks.
For the Messages API, there is no automatic fallback by default — the request is blocked with a structured refusal category. Developers can implement client-side retry logic or opt into automatic server-side fallback to Opus 4.8. For the chat interface, fallback is automatic and the user is notified which model responded.
A Reddit commenter captured the significance: "The ~5% fallback to Opus 4.8 is the detail that matters most if you're building on top of this in prod — latency and cost profile changing mid-session is a nasty edge case to handle gracefully."
The 30-Day Data Retention Policy
Fable 5 introduces a mandatory 30-day traffic retention policy for all business customers — including those on zero-retention enterprise contracts. Anthropic states the data won't be used for training and will only be accessed for safety purposes (defending against jailbreaks, identifying false positives). All human access is logged. Data is deleted after 30 days "in almost all cases."
This is a significant policy shift. The announcement frames it as a necessary trade-off for deploying models at this capability level: "The data will help us defend against complex and novel attacks as well as help us identify and reduce false positives."
Pricing: $10/$50 — Half of Mythos Preview
| Model | Input $/1M | Output $/1M | Class |
|---|---|---|---|
| Claude Fable 5 | $10.00 | $50.00 | Mythos (public) |
| Claude Mythos Preview | $15.00 | $100.00 | Mythos (restricted) |
| Claude Opus 4.8 | $5.00 | $25.00 | Opus (public) |
| GPT-5.5 | $5.00 | $30.00 | Flagship |
| GPT-5.5 Pro | $30.00 | $180.00 | Flagship + parallel |
| DeepSeek V4 Pro | $0.44 | $0.87 | Open-weight |
Fable 5 is 2× the price of Opus 4.8 ($50 vs $25 output) but less than half the price of Mythos Preview ($50 vs $100). For subscription users, it's free on Pro, Max, Team, and Enterprise plans through June 22. After that, it requires usage credits — though Anthropic aims to restore it as a standard plan feature "as quickly as we can."
Simon Willison reported burning through $110.42 in tokens in 5.5 hours of testing — all within his $100/month subscription. His take: "It's slow, expensive, and capable."
Long-Horizon Autonomy: The Real Breakthrough
The benchmark numbers are impressive. But the qualitative shift that testers describe goes beyond scores. Multiple early-access users report a fundamentally different interaction model:
- Felix Rieseberg (Anthropic): "A shift from giving AI tasks to giving it responsibilities."
- Alex Albert (Anthropic): "The model feels collaborative rather than tool-like."
- Bcherny: "Biggest step since Opus 4.5. The model shows judgment, taste, methodical debugging."
- Dan Shipper: "Routinely used 500K to 1M tokens on tasks. Best reserved for heavy jobs."
- Sean Ward (Source): "Works at senior research scientist grade — picking directions, allocating resources, killing its incorrect beliefs, and producing novel first-principles outputs."
GitLab, which added Fable 5 to its Duo Agent Platform on launch day, advised users: "Start with your hardest unsolved problem. If you test Claude Fable 5 only on routine tasks, you will miss its most significant capabilities."
GitHub's CPO Mario Rodriguez said Fable 5 "took on complex, long-horizon coding tasks with a level of autonomy and reliability that exceeded previous benchmarks. What excites us most is the direction it points: a future where developers can hand increasingly ambitious work to agents and trust the results across the software lifecycle."
Memory, Vision, and Self-Improvement
Fable 5 introduces several qualitative improvements beyond raw benchmark scores:
- Persistent memory. When playing the deck-building game Slay the Spire, Fable 5 improved its performance 3× more than Opus 4.8 when given access to file-based memory. It also reached the game's final act 3× more often — demonstrating that the model can effectively use notes and persistent state across very long sessions.
- Vision. Fable 5 beat Pokémon FireRed from start to finish using only raw game screenshots — no maps, navigation aids, or extra game-state information. Earlier Claude models needed a complex helper harness. Fable 5 completed the game with vision alone.
- Protein design. Mythos 5 (same model) matched or beat skilled human operators on protein design tasks — choosing binding sites, selecting and running design tools, and recovering from failures. 9 of 14 protein targets yielded strong drug design candidates currently under investigation.
- Scientific hypotheses. Anthropic scientists preferred Mythos 5's molecular biology hypotheses ~80% of the time over Opus-class models in blinded comparisons. One hypothesis — a novel mechanism for an E. coli protein — was independently corroborated by a lab working on the same problem.
- Genomics research. Mythos 5 conducted over a week of largely autonomous genomics work, assembling single-cell data across 138 species and training a custom ML model that outperformed a recent Science publication — despite being 100× smaller.
Why Fable 5 Matters for AGI
Fable 5 represents several shifts that move the needle toward artificial general intelligence:
- Long-horizon autonomy. The model can sustain coherent work across hours or days — not minutes. Stripe's 50M-line migration, the week-long genomics project, the full Pokémon playthrough — these are not chat interactions. They're autonomous work sessions.
- Self-correction. Sean Ward described Fable 5 "killing its incorrect beliefs." The model doesn't just generate output — it evaluates, rejects, and refines. This meta-cognitive ability is a prerequisite for unsupervised operation.
- Tool orchestration across domains. From protein design tools to bioinformatics pipelines to codebase migrations — Fable 5 switches between tools, recovers from failures, and adapts its strategy. This is not single-domain expertise.
- Novel scientific contribution. The E. coli protein hypothesis corroboration is significant: the model produced novel, testable science that a human lab independently verified. This crosses the threshold from "useful tool" to "research collaborator."
- Safety infrastructure scaling with capability. The Fable/Mythos split, classifier-based fallbacks, 30-day retention, and external red-teaming represent a deployment model designed for models that are genuinely dangerous if unrestricted. This is the infrastructure AGI requires.
The Anthropic ECI (Effective Compute Index), the company's internal capability-over-time measure, places Fable 5 above the historical trend line with a jump similar to Mythos Preview in April 2026. Capability is continuing to improve at roughly a constant rate — not further accelerating, but not slowing either. The takeaway: this is the new normal, and more jumps like this are coming.
Compiled Early Feedback
| Source | Quote / Summary |
|---|---|
| Andrej Karpathy | "Major-version-bump-deserving step change." Safeguards are "a little too trigger happy for launch." |
| Simon Willison | "Something of a beast. Slow, expensive, capable. $110 in 5.5 hours." |
| Cursor (Michael Truell) | "State of the art on CursorBench. Opened up long-horizon problems." |
| GitHub (Mario Rodriguez) | "Complex, long-horizon coding with autonomy and reliability exceeding previous benchmarks." |
| Source (Sean Ward) | "Works at senior research scientist grade. Kills its incorrect beliefs." |
| Cognition | "Highest-scoring model on FrontierBench. Excels at long-horizon reasoning." |
| Stripe | 50M-line Ruby migration in 1 day vs 2+ months by hand (~60× acceleration). |
| GitLab | "Start with your hardest unsolved problem. Routine tasks miss the point." |
| Notion | "What builders mean, not just what they type. One-shots apps that took 100 prompts." |
| Artificial Analysis | #1 on GDPval-AA (1932). Fallback on 2% of GDPval tasks. |
| Jamie Marsland | Built a complete WordPress block theme in one shot. "Feels next level." |
Compiled from: Anthropic Announcement · Simon Willison · Latent Space roundup · TrueFoundry · Vellum · Artificial Analysis.
Should You Use Fable 5?
| Use Case | Verdict | Why |
|---|---|---|
| Complex multi-file coding | ✅ Yes | 80.3% Pro. 29.3% FrontierCode. Best coding model ever. |
| Long-horizon autonomous tasks | ✅ Yes | Stripe migration. Pokémon full playthrough. Week-long genomics. |
| Scientific research | ✅ Yes | Novel E. coli hypothesis. Protein design beating humans. |
| Routine coding / quick answers | ⚠️ Overkill | Use Opus 4.8 or Sonnet. Save Fable for hard problems. |
| Cost-sensitive high volume | ⚠️ Maybe | $50/1M. DeepSeek V4 Pro at $0.87 for volume. Batch helps. |
| Cybersecurity work | ❌ No | Falls back to Opus 4.8. You need Mythos 5 (restricted). |
The Verdict
Claude Fable 5 is the most capable AI model ever made available to the general public. It leads every benchmark that matters for coding. It completed a real production migration in one day that would have taken humans months. It plays Pokémon with vision alone. It designs proteins that beat human experts. It produces novel scientific hypotheses that independent labs corroborate.
The price — $10/$50 per million tokens — is 2× Opus 4.8 but half of Mythos Preview. The safety architecture — classifiers, fallbacks, 30-day retention — sets a new standard for responsible deployment of models at this capability level. The feedback from early testers is unanimous: this is not an incremental update. This is a step change.
Is Fable 5 AGI? No. But it's the clearest sign yet that the path from here to there is real, accelerating, and being built with genuine attention to safety. The Fable/Mythos architecture is a template for how to deploy increasingly capable models without losing control. And the Stripe result — 60× acceleration on real production work — is a preview of what happens when these models start touching the economy.
Try it. It's free on subscription plans through June 22. Test it on your hardest problem — not your routine ones. As GitLab put it: that's where you'll see what actually changed.
20+ LLMs. Side-by-side testing. Find your hardest problem and see what Mythos-class can do.
Sources & Further Reading: Anthropic — Fable 5 & Mythos 5 Announcement | Simon Willison — Initial Impressions | Latent Space — Roundup | TrueFoundry — Guide | Vellum — Benchmarks Explained | Cosmic JS — Developer Guide | GitLab — Duo Agent Platform | Artificial Analysis — GDPval-AA #1 | Reddit r/artificial Discussion | Reddit r/ClaudeAI Discussion. Fable 5/Mythos 5 share the same underlying model. All scores vendor-reported unless otherwise noted.