
June 30, 2026. Anthropic retires the "4.6" suffix and ships Claude Sonnet 5 — same list price ($3/$15), same 1M context, same Sonnet tier. But the benchmarks tell a different story. Terminal-Bench 2.1 jumps from 67.0% to 80.4% (+13.4). HLE with tools from 46.8% to 57.4% (+10.6). FrontierCode more than doubles from 15.1% to 38.8%. And on knowledge work, Sonnet 5 adds 223 Elo points — jumping from 1395 to 1618, which actually beats Opus 4.8. This is not an incremental refresh. It's the biggest generation-over-generation leap in Sonnet history. Here's every benchmark, sourced from Anthropic's Sonnet 5 System Card. Test both on CodingFleet.
TL;DR — Sonnet 5 vs Sonnet 4.6
- Same price, massive gains: $3/$15 list price unchanged. Introductory $2/$10 through Aug 31, 2026.
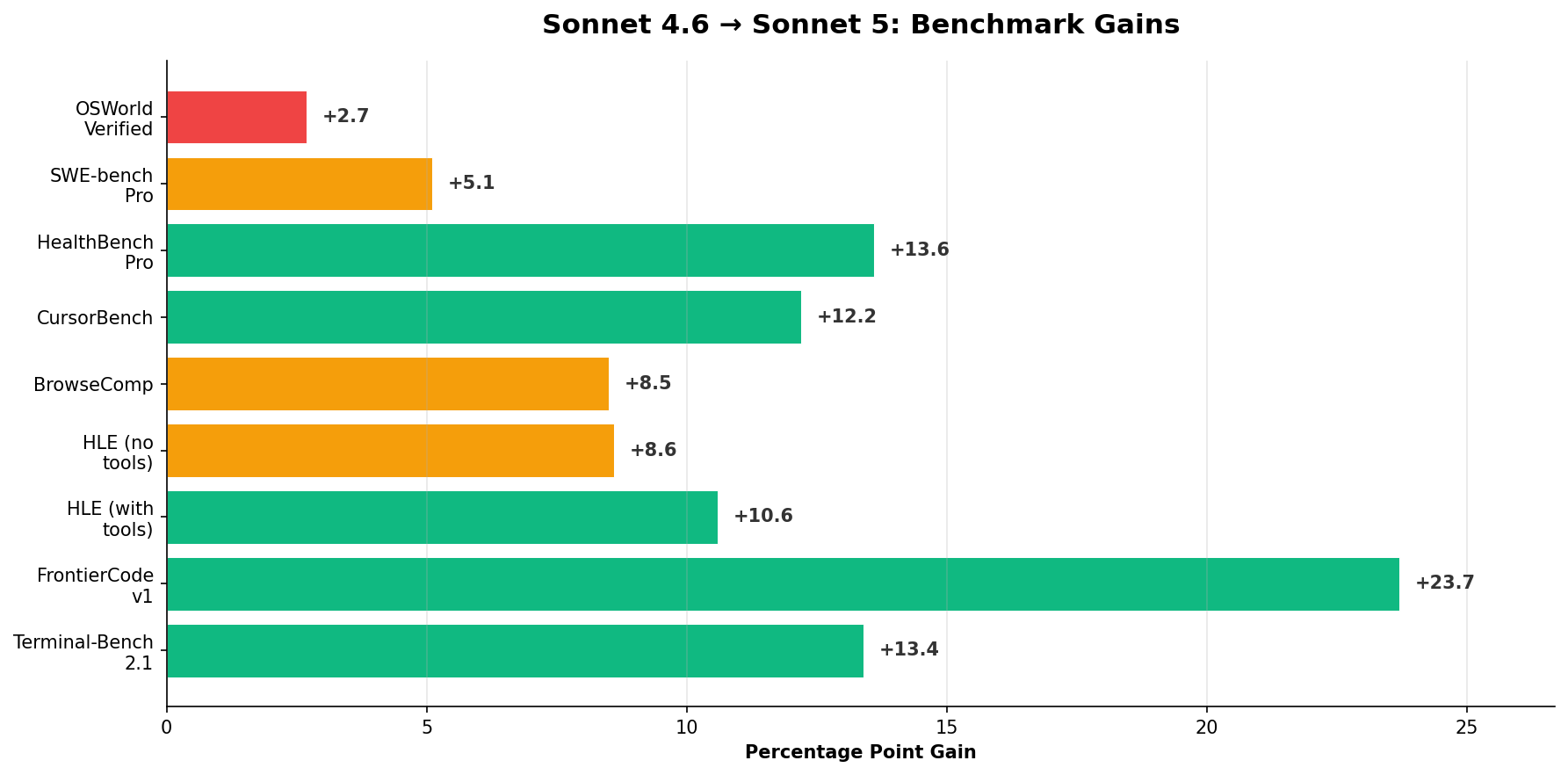
- +13.4 Terminal-Bench 2.1: 67.0% → 80.4%. The biggest single-benchmark jump.
- +10.6 HLE (with tools): 46.8% → 57.4%. Agentic reasoning nearly matches Opus 4.8 (57.9%).
- +5.1 SWE-bench Pro: 58.1% → 63.2%. Within 6 points of Opus 4.8.
- +223 GDPval-AA v2: 1395 → 1618. Sonnet 5 beats Opus 4.8 on knowledge work.
- FrontierCode more than doubles: 15.1% → 38.8%. Structural improvement in frontier coding.
- Tokenizer caveat: Same text = 1.0–1.35× more tokens vs 4.6. Effective cost slightly higher at scale.
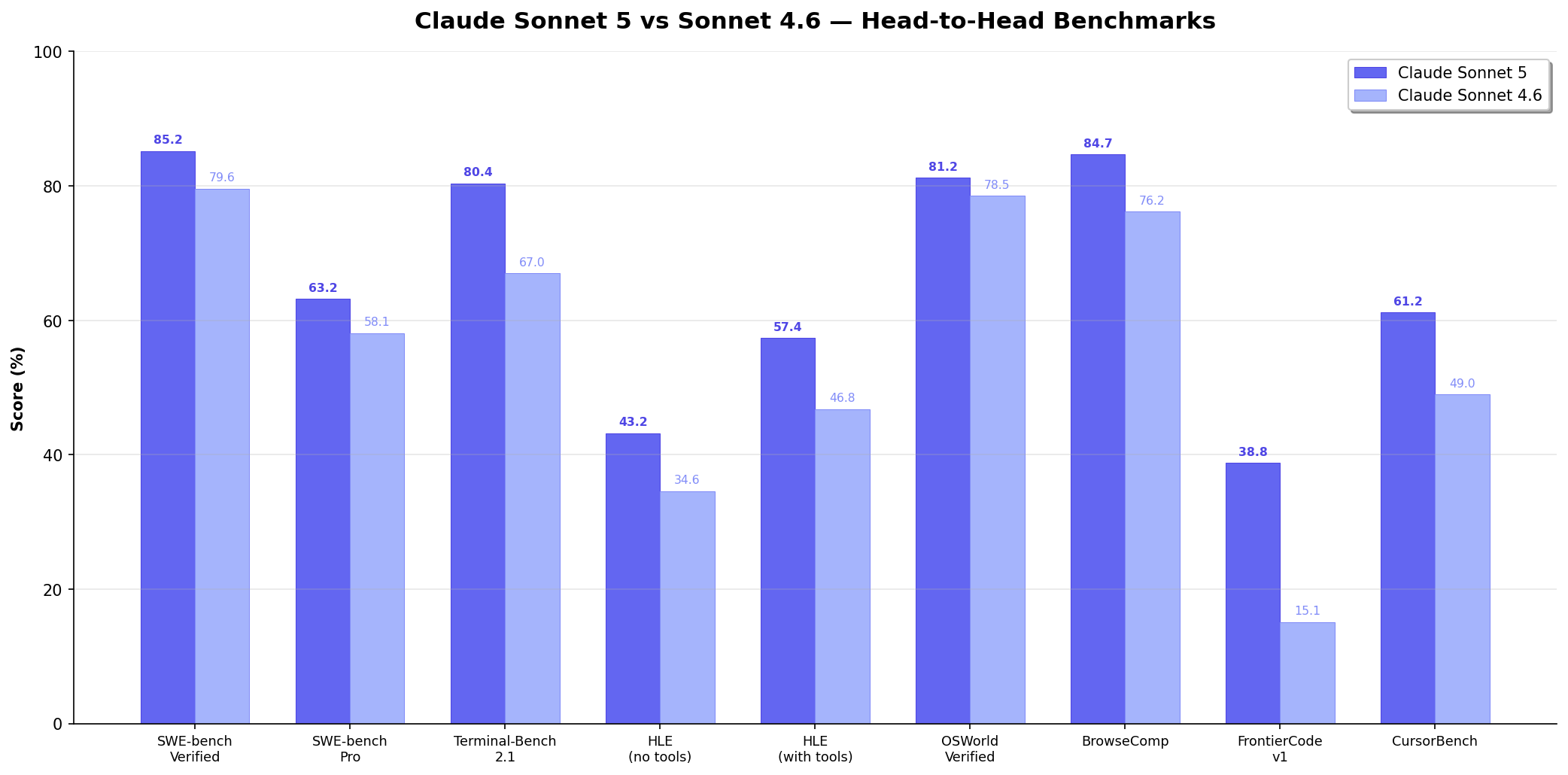
Full Benchmark Comparison
| Benchmark | Sonnet 5 | Sonnet 4.6 | Gain |
|---|---|---|---|
| Agentic coding (Terminal-Bench 2.1) | 80.4% | 67.0% | +13.4 |
| HealthBench Professional | 57.8% | 44.2% | +13.6 |
| FrontierCode v1 | 38.8% | 15.1% | +23.7 |
| CursorBench (independent) | 61.2% | 49.0% | +12.2 |
| Reasoning (HLE, with tools) | 57.4% | 46.8% | +10.6 |
| Reasoning (HLE, no tools) | 43.2% | 34.6% | +8.6 |
| Agentic search (BrowseComp) | 84.7% | 76.2% | +8.5 |
| Knowledge work (GDPval-AA v2) | 1618 | 1395 | +223 |
| AutomationBench | 13.5% | 5.3% | +8.2 |
| SWE-bench Verified | 85.2% | 79.6% | +5.6 |
| Agentic coding (SWE-bench Pro) | 63.2% | 58.1% | +5.1 |
| Toolathlon (multi-app agent) | 54.3% | 49.4% | +4.9 |
| USAMO 2026 (math olympiad) | 79.5% | 55.0% | +24.5 |
| Computer use (OSWorld-Verified) | 81.2% | 78.5% | +2.7 |
Source: All benchmark scores from Anthropic's Claude Sonnet 5 System Card, Table 8.1.A and relevant subsection details. All Sonnet 5 results use adaptive thinking at max effort, default sampling, averaged over 5 trials. Sonnet 4.6 scores from the same evaluation harness. CursorBench scores independently measured by Cursor in their production harness. SWE-bench Verified Sonnet 4.6 score (79.6%) from Anthropic's Sonnet 4.6 launch announcement.
The +13.4 Terminal-Bench Leap: Agentic Coding Transformed
The single biggest percentage-point gain on any benchmark. Sonnet 4.6 at 67.0% on Terminal-Bench 2.1 was respectable — competitive with GPT-5.4 (75.1%). Sonnet 5 at 80.4% is a different tier entirely. It now sits within 2.3 points of Opus 4.8 (82.7%) and ahead of Opus 4.7 (69.7%). Terminal-Bench measures real CLI agentic coding — package management, git operations, build system debugging, server configuration. This is the benchmark that most directly reflects what developers experience in Claude Code. Anthropic's System Card confirms the evaluation uses the same mini-SWE-agent harness for both models, making this a clean apples-to-apples comparison.
The practical implication: tasks that Sonnet 4.6 would fail on 33% of the time, Sonnet 5 now handles successfully 80% of the time. For developers using Claude Code as a daily driver, this is the difference between constant hand-holding and genuine autonomy.
FrontierCode: More Than Doubled
FrontierCode v1 tests cutting-edge coding challenges that require novel algorithmic thinking — the kind of problems where models can't pattern-match from training data. Sonnet 4.6 at 15.1% was barely functional. Sonnet 5 at 38.8% is +23.7 points — more than double. This isn't just incremental tuning. It's a structural improvement in how the model handles unfamiliar coding problems. Anthropic's framing: "Sonnet 5 is built to be the most agentic Sonnet model yet." FrontierCode is where that claim is most visible.
HLE with Tools: Now Matches Opus 4.8
Humanity's Last Exam with tools is the hardest reasoning benchmark with tool access. Sonnet 4.6 scored 46.8%. Sonnet 5 scores 57.4% — a +10.6 point jump that puts it within 0.5 points of Opus 4.8 (57.9%). That's functionally identical. For developers building agentic research workflows — where the model uses browsers, code execution, and file manipulation to solve complex problems — Sonnet 5 delivers Opus-level reasoning at 60% of the price.
Without tools, the gap to Opus remains wider (43.2% vs 49.8%), but Sonnet 5 still gained +8.6 points over Sonnet 4.6 (34.6%). Raw reasoning improved substantially — tools just make it competitive with the flagship.
Knowledge Work: Sonnet 5 Beats Opus 4.8
GDPval-AA v2 is an independent benchmark from Artificial Analysis that measures real-world professional task completion across 220 tasks and 44 occupations. Sonnet 4.6 scored 1395 Elo — solidly mid-pack. Sonnet 5 scores 1618 Elo — a +223 point gain that places it ahead of Opus 4.8 (1615). This is the first time a Sonnet-tier model has outscored the concurrent Opus flagship on any benchmark. The System Card notes: "Claude Sonnet 5 ranks second (ELO 1618), statistically tied with Opus 4.8 (ELO 1615) and trailing only Fable 5 (ELO 1783)."
For everyday professional use — document analysis, slide creation, spreadsheet work, research synthesis — Sonnet 5 delivers better-than-Opus quality at 60% of the cost. There is no tradeoff.
SWE-bench: Solid Gains on Both Pro and Verified
On SWE-bench Pro (the harder, contamination-resistant variant): +5.1 points (58.1% → 63.2%). On SWE-bench Verified (the classic 500-problem set): +5.6 points (79.6% → 85.2%). These are meaningful but not structural gains — SWE-bench is becoming a saturated benchmark at the frontier. The more interesting story is in the independent evaluation: CursorBench, measured by Cursor in their production harness, shows Sonnet 5 at 61.2% vs Sonnet 4.6 at 49.0% — a +12.2 point gain. Different tasks, different harness, but a consistent signal: Sonnet 5 is materially better at real-world coding.
Math: USAMO Jumps +24.5 Points
The USA Mathematical Olympiad 2026 — a proof-based competition held March 21–22, after Sonnet 5's training data cutoff — shows the most dramatic gain of any benchmark: Sonnet 4.6 at 55.0% vs Sonnet 5 at 79.5% (+24.5). This is a completely uncontaminated evaluation (the 2026 USAMO took place after pretraining data collection ended). The gain suggests genuine improvements in mathematical reasoning, not memorization. For reference, Opus 4.8 scored 96.7% and Mythos 5 scored 99.8% — Sonnet 5 still trails the frontier, but the gap has narrowed dramatically.
Specification Comparison
| Feature | Claude Sonnet 5 | Claude Sonnet 4.6 |
|---|---|---|
| Released | June 30, 2026 | February 17, 2026 |
| API ID | claude-sonnet-5 | claude-sonnet-4-6 |
| Context Window | 1,000,000 tokens | 1,000,000 tokens |
| Max Output | 128K (300K batch) | 64K |
| Thinking | Adaptive (effort: high default) | Adaptive (effort levels) |
| Extended Thinking | No | Yes |
| Knowledge Cutoff | Jan 2026 | Jan 2026 (reliable: Aug 2025) |
| Comparative Latency | Fast | Fast |
| Pricing (API) | $3 / $15 per MTok* | $3 / $15 per MTok |
| Tokenizer | New (Opus 4.7+ tokenizer) | Old (Sonnet 4.6 tokenizer) |
| Max Output (batch beta) | 300K | Not supported |
* Introductory pricing of $2/$10 per MTok through August 31, 2026. Sources: Claude Platform Docs, Sonnet 5 System Card.
The Tokenizer Caveat: Same List Price, Higher Token Count
The headline prices are identical ($3/$15), but Sonnet 5 uses the updated tokenizer Anthropic introduced with Opus 4.7. The same text produces 1.0× to 1.35× more tokens than Sonnet 4.6, depending on content. Simon Willison's analysis: English ~1.33–1.42×, Python code ~1.27–1.28×, Spanish ~1.33×, Simplified Chinese ~1.01×.
In practice: if your workload averaged $1,000/month on Sonnet 4.6, expect ~$1,270–$1,420/month on Sonnet 5 for English-heavy tasks — a real cost increase of 27–42%. On the introductory $2/$10 pricing, even with inflation you're paying effective rates of ~$2.60/$13.00 — still well below the $3/$15 list. Anthropic's announcement: "We've increased rate limits across all surfaces to accommodate the higher token usage."
Safety & Alignment: Better Across the Board
The System Card's alignment assessment (Section 6) reports that Sonnet 5 improves over Sonnet 4.6 on most measures:
| Metric | Sonnet 4.6 | Sonnet 5 | Change |
|---|---|---|---|
| MASK (sycophantic lying rate) | 13.3% | 3.1% | −10.2 |
| AA-Omniscience (factuality net score) | 0.14 | 0.20 | +0.06 |
| AA-Omniscience (incorrect rate) | 35.0% | 26.5% | −8.5 |
| Malicious request refusal (Claude Code) | 76.6% | 92.4% | +15.8 |
| Prompt injection ASR (coding, with thinking) | 12.71% | 0.31% | −12.4 |
Source: Sonnet 5 System Card, Sections 5, 6. MASK = Model Alignment between Statements and Knowledge. ASR = Attack Success Rate (lower is better).
Sycophancy dropped from 13.3% to 3.1% — the lowest of any tested Claude model. Factual hallucination fell from 35.0% to 26.5%. Malicious request refusal in Claude Code jumped from 76.6% to 92.4%. And prompt injection robustness in coding environments improved dramatically — from 12.71% attack success rate to 0.31%. Mashable's coverage: "Anthropic reports Sonnet 5 shows lower rates of hallucination, sycophancy, and other undesirable behaviors."
One regression: Sonnet 5 has a slightly higher "wet blanket" rate — dismissive or discouraging responses. And its over-refusal rate on benign prompts is marginally higher (0.59% vs 0.40% on API). But overall, the safety picture is overwhelmingly positive.
Should You Upgrade from Sonnet 4.6?
| If you... | Decision |
|---|---|
| Use Claude Code daily for agentic coding | ✅ Upgrade immediately. +13.4 TB 2.1 is transformational. |
| Run knowledge work / document analysis | ✅ Upgrade. +223 GDPval. Beats Opus 4.8. |
| Need max output tokens (64K → 128K) | ✅ Upgrade. Double the output ceiling. |
| Care about sycophancy / hallucination | ✅ Upgrade. 3.1% lying rate (lowest ever). |
| Build prompt injection-resistant agents | ✅ Upgrade. 0.31% ASR vs 12.71%. |
| Are cost-sensitive at high volume | ⚖️ Measure. Tokenizer inflation = 1.0–1.35× more tokens. |
| Use extended thinking explicitly | ⚖️ Note: Sonnet 5 drops extended thinking. Adaptive only. |
| Need proven production stability | ⚖️ Stay. Sonnet 4.6 has 4+ months of hardening. |
Conclusion: The No-Brainer Upgrade (With One Asterisk)
Claude Sonnet 5 is the most decisive generation-over-generation improvement in Sonnet history. Every benchmark went up — several by double-digit margins. The gains are concentrated where they matter most: agentic coding (+13.4 TB), tool-augmented reasoning (+10.6 HLE), knowledge work (+223 GDPval), and safety (sycophancy −10.2, injection resistance −12.4). At the same list price, this is as close to a no-brainer upgrade as enterprise AI gets.
The one asterisk is the tokenizer. If you're running high-volume English workloads, the effective cost increase is 27–42% due to token inflation — not the price-per-token, but the tokens-per-request. On the introductory $2/$10 pricing through August 31, the real cost still lands below the $3/$15 list. After that, measure your specific workload before committing at scale.
Anthropic's official line: "Claude Sonnet 5 is built to be the most agentic Sonnet model yet. It can make plans, use tools like browsers and terminals, and run autonomously at a level that, just a few months ago, required larger and more expensive models." The data backs it up. Sonnet 4.6 was already the workhorse of the Claude lineup. Sonnet 5 makes it nearly obsolete — at the same price.
🔬 Side-by-Side Test
Run Claude Sonnet 5 and Sonnet 4.6 on your own code. See the +13.4 Terminal-Bench improvement in practice. Sandboxes stay alive even when you close your laptop.
🔄 Compare Side by Side →Sources & Links
- Anthropic — Claude Sonnet 5 System Card (PDF) — Table 8.1.A, all benchmark scores, safety evaluations
- Anthropic — Introducing Claude Sonnet 5 — official launch announcement, pricing, tokenizer notes
- Claude Platform Docs — Models Overview — spec comparison table
- Claude Platform Docs — What's New in Claude Sonnet 5
- Simon Willison — What's New in Claude Sonnet 5 — tokenizer analysis
- Mashable — Anthropic Finally Launches Claude Sonnet 5
- Coursiv — Claude Sonnet 5: Release Date, Pricing, API & Benchmarks
- Handy AI — Model Drop: Claude Sonnet 5
- Cursor — CursorBench — independent production harness evaluation
- Morphllm — Claude Benchmarks (2026) — third-party benchmark tracker
Read This Next
- Claude Sonnet 5 vs Opus 4.8 — 93% of the power at 60% of the price
- SWE-bench Pro Leaderboard 2026 — every model ranked by real coding
- Terminal-Bench Leaderboard 2026 — CLI agentic coding rankings