
Two budget-tier models. Two completely different bets on value. DeepSeek V4 Flash (April 24, 2026): 284B MoE, 13B active, MIT-licensed, self-hostable, $0.28/1M output. 91.6% LiveCodeBench. 1M context. GPT-5.4 Mini (March 17, 2026): proprietary, image-capable, $4.50/1M output. 54.4% SWE-bench Pro. 60.0% Terminal-Bench. One is 16× cheaper, open-weight, and leads algorithmic coding. The other leads real-world bug fixing and terminal tasks, with multimodal input. For the first time, the budget tier is genuinely interesting. Here's the complete data. Test both on CodingFleet.
📊 Key Findings
- Mini leads coding benchmarks: Pro +1.8, Terminal +3.1. For real-world GitHub issues and CLI tasks, Mini is measurably better. Flash trails but at a fraction of the cost.
- Flash dominates algorithmic coding: LiveCodeBench 91.6%. For algorithms, data structures, and competitive programming, Flash is in a different league. Mini has not published a LiveCodeBench score — a significant omission for a coding model.
- Flash is 16× cheaper: $0.28 vs $4.50 per 1M output. MIT-licensed with weights on Hugging Face. Self-host on your own GPUs. Mini is proprietary API-only. The economics are not close.
- Flash wins reasoning: HLE +3.6 (with tools), +6.6 (without). For research-heavy coding and deep reasoning, Flash is the stronger model despite being cheaper. GPQA Diamond is tied at ~88%.
- Mini has multimodal input. Flash does not. For coding from screenshots, design references, or documentation, Mini is the only option.
Compare models on your own code at CodingFleet — 20+ LLMs, side-by-side. See the SWE-bench Pro leaderboard and Terminal-Bench leaderboard for full rankings.
Benchmark Comparison
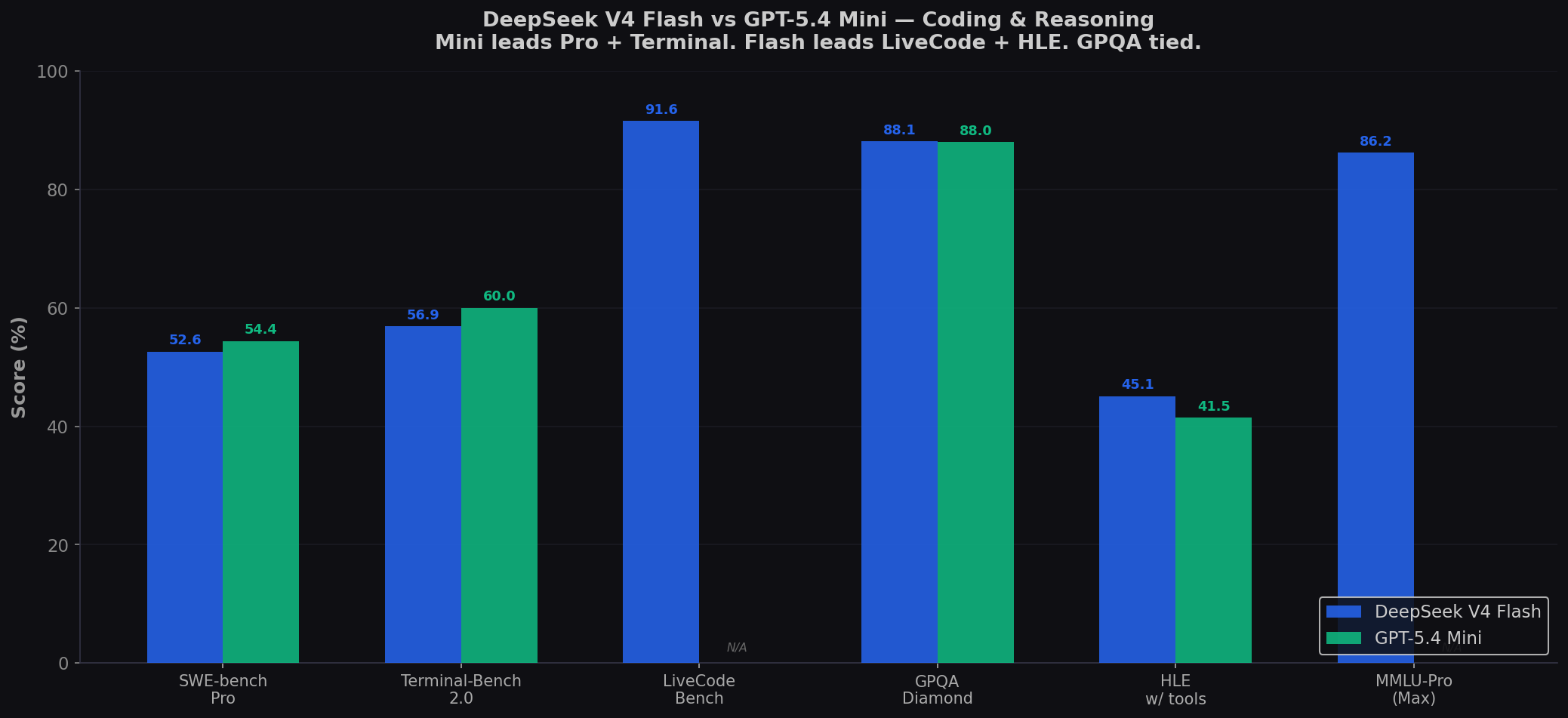
| Benchmark | DeepSeek V4 Flash | GPT-5.4 Mini | Winner |
|---|---|---|---|
| SWE-bench Pro | 52.6% | 54.4% | Mini (+1.8) |
| SWE-bench Verified | 79.0% | — | Flash |
| Terminal-Bench 2.0 | 56.9% | 60.0% | Mini (+3.1) |
| LiveCodeBench | 91.6% | — | Flash |
| Codeforces Rating | 3052 | — | Flash |
| GPQA Diamond | 88.1% | 88.0% | Tie (+0.1 Flash) |
| HLE (no tools) | 34.8% | 28.2% | Flash (+6.6) |
| HLE (with tools) | 45.1% | 41.5% | Flash (+3.6) |
| MMLU-Pro | 86.2% | — | Flash |
| HMMT 2026 Feb | 94.8% | — | Flash |
| OSWorld-Verified | — | 72.1% | Mini |
| Toolathlon | 47.8% | 42.9% | Flash (+4.9) |
| MCP Atlas | 69.0% | 57.7% | Flash (+11.3) |
| BrowseComp | 73.2% | — | Flash |
| Output Price /1M tok | $0.28 | $4.50 | Flash (16× cheaper) |
| Input Price /1M tok | $0.14 | $0.75 | Flash (5.4× cheaper) |
| Context Window | 1M | 400K | Flash (2.5× larger) |
| Max Output | 384K | 128K | Flash (3×) |
| License | MIT (open-weight) | Proprietary | Flash |
| Multimodal Input | No | Yes (text+image) | Mini |
Sources: DeepSeek V4 Model Card — all Flash scores (Max reasoning) · OpenAI GPT-5.4 Mini Announcement — Mini scores (xhigh) · OpenAI GPT-5.4 Release. "—" means not published by vendor. GPQA Diamond: essentially tied at 88%.
Budget Coding Radar
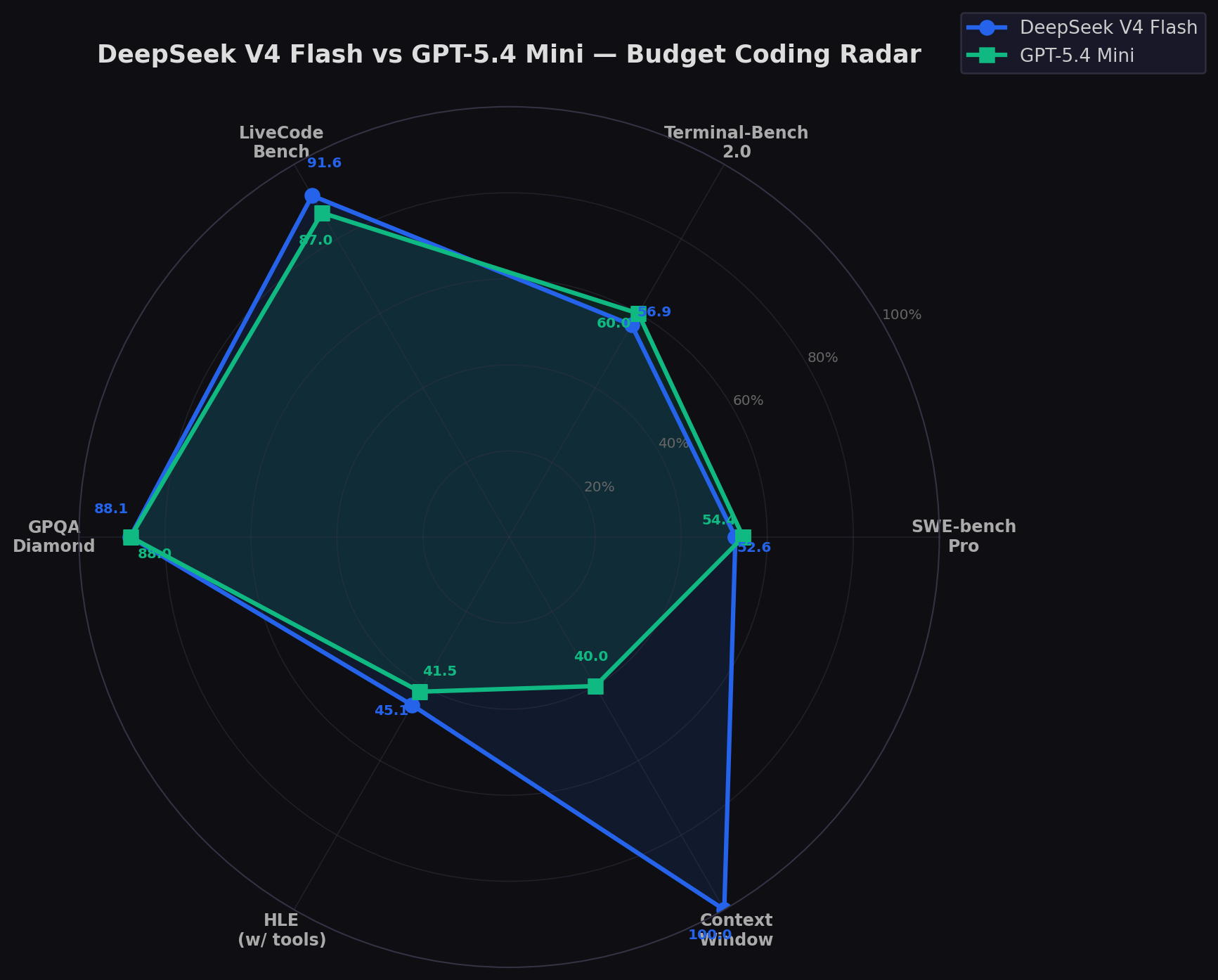
The radar reveals classic budget-tier tradeoffs. Mini's green ring leads on SWE-bench Pro and Terminal-Bench — practical coding tasks. Flash's blue ring spikes on LiveCodeBench and HLE — algorithmic and research reasoning. Context window is a blowout: 1M vs 400K. The models are complementary: Mini for bug fixing and CLI tasks, Flash for algorithm work and research-heavy coding.
Where Each Model Wins at Coding
DeepSeek V4 Flash — The Algorithm & Value King
- LiveCodeBench 91.6% — elite algorithmic coding. For competitive programming, algorithm design, data structures, and math-heavy code, Flash is in the top tier of all models. Mini has no published LiveCodeBench score — likely much lower.
- 16× cheaper: $0.28 vs $4.50 per 1M output. At scale, this is transformative. A CI/CD pipeline generating code for every commit costs pennies with Flash. The same pipeline with Mini costs dollars. Over a month of heavy coding agent usage, Flash saves hundreds.
- MIT license = full freedom. Weights on Hugging Face. Self-host on your GPUs. Fine-tune on proprietary codebases. Deploy air-gapped. For regulated industries, Flash is the only viable budget option.
- 1M context — 2.5× Mini's 400K. Full-codebase analysis in a single session. Process entire repositories without chunking. Flash makes large-context coding practical at budget prices.
- 384K max output — 3× Mini's 128K. Generate entire files, test suites, and documentation in a single pass.
- HLE +6.6 (no tools), HLE +3.6 (with tools). For research-heavy coding that requires deep reasoning, Flash is the stronger model by a meaningful margin — despite being 16× cheaper.
- MCP Atlas 69.0% vs 57.7% — dominant tool use. Flash is 11.3 points ahead on multi-step MCP tool workflows. For agentic coding with tools, Flash is clearly better.
GPT-5.4 Mini — The Practical Coder
- SWE-bench Pro 54.4% — leads by 1.8 points. For real-world GitHub issue resolution, Mini is the more reliable model. The Pro lead, while modest, is consistent with Mini's broader strength on practical coding tasks.
- Terminal-Bench 2.0 60.0% — leads by 3.1 points. For CLI agent tasks — git operations, build systems, shell scripting — Mini is measurably better. This is Mini's strongest relative advantage.
- Multimodal input (text + image). For coding from screenshots, design mockups, UI references, and visual documentation, Mini is the only option. Flash is text-only.
- OSWorld-Verified 72.1% — computer use. Mini can operate desktop applications, navigate GUIs, and interact with software. Flash has no published OSWorld score.
- OpenAI ecosystem integration. Native support in ChatGPT, Codex CLI, and 14+ API providers. For teams already invested in OpenAI tooling, Mini slots in seamlessly.
- GPQA Diamond 88.0% — essentially tied with Flash. For scientific computing and graduate-level reasoning, both models are equally capable.
When to Use Which
| Scenario | Use | Why |
|---|---|---|
| Production bug fixing (real repos) | GPT-5.4 Mini | 54.4% Pro vs 52.6%. +1.8 lead. |
| Terminal / CLI / DevOps tasks | GPT-5.4 Mini | 60.0% vs 56.9%. +3.1 lead. |
| Code from images / screenshots | GPT-5.4 Mini | Only one with multimodal input. |
| Desktop GUI automation | GPT-5.4 Mini | 72.1% OSWorld. Verified computer use. |
| Algorithm & data structures | DeepSeek V4 Flash | 91.6% LiveCodeBench. 3052 Codeforces. |
| Cost-sensitive high-volume | DeepSeek V4 Flash | $0.28 vs $4.50. 16× cheaper. |
| Self-hosting / data sovereignty | DeepSeek V4 Flash | MIT license. Runs on your GPUs. |
| Research-heavy coding (tool use) | DeepSeek V4 Flash | 45.1% HLE w/tools. MCP Atlas +11.3. |
| Full-codebase context (1M) | DeepSeek V4 Flash | 1M vs 400K context. 2.5× larger. |
| Fine-tuning on proprietary code | DeepSeek V4 Flash | MIT weights. Fine-tune freely. |
Pricing: The 16× Reality
| Detail | DeepSeek V4 Flash | GPT-5.4 Mini |
|---|---|---|
| Input (cache miss) | $0.14 / 1M | $0.75 / 1M |
| Input (cache hit) | $0.0028 / 1M | $0.075 / 1M |
| Output | $0.28 / 1M | $4.50 / 1M |
| Batch/Flex discount | Permanent 75% off | 50% off (Batch/Flex) |
| 10M tokens cost (90% in) | $1.54 | $24.75 |
| 100M tokens cost (90% in) | $15.40 | $247.50 |
| Speed | ~60-84 tok/s | ~2× GPT-5.4 speed |
At 10M tokens/month with 90% input: Flash costs $1.54 vs Mini's $24.75. At 100M tokens: $15.40 vs $247.50. The savings compound dramatically at scale.
Conclusion: The Budget Tier Has Never Been This Interesting
GPT-5.4 Mini is the better practical coder. The 1.8-point Pro lead and 3.1-point Terminal-Bench lead are real. If your primary workflow is fixing bugs in GitHub repos and running terminal commands, Mini delivers better results. The multimodal input and computer use capabilities add flexibility that Flash cannot match.
DeepSeek V4 Flash is the better algorithmic thinker and the massively better value. The 91.6% LiveCodeBench, 16× lower cost, MIT license, 1M context, and stronger reasoning scores make a compelling case. For algorithm implementation, research-heavy coding, agentic tool use, self-hosting, and cost-sensitive high-volume pipelines, Flash is the clear winner.
The budget tier in June 2026 is genuinely competitive with the flagship tier from six months ago. Both models beat GPT-5.2 on most benchmarks. The choice is workflow-dependent: Mini for practical bug fixing and CLI tasks, Flash for algorithms and value. At $0.28 vs $4.50, you can afford both.
20+ LLMs available. Side-by-side testing. Both models ready.
Sources: DeepSeek V4 Model Card | OpenAI GPT-5.4 Mini Announcement | OpenAI GPT-5.4 Release | Lightning AI V4 Review | DocsBot Comparison | LLM Reference | SWE-bench Pro Leaderboard | Terminal-Bench Leaderboard.