
Both are MIT-licensed. Both are Chinese. Both are MoE architectures targeting developers who want frontier coding without proprietary lock-in. But DeepSeek V4 Pro Max and GLM 5.1 represent two fundamentally different bets on what "open-weight value" means. V4 Pro Max (April 24, 2026): 1.6T total / 49B active, $0.87/1M output (permanent 75% discount), 93.5% LiveCodeBench — global #1. 1M context. GLM 5.1 (April 7, 2026): 754B total / 40B active MoE, $3.08/1M output, 58.4% SWE-bench Pro — briefly #1 at launch. Trained entirely on Huawei Ascend 910B chips. GLM leads the hardest coding benchmark. V4 Pro Max dominates everything else — and is 3.5× cheaper. Here's the complete data. Test both on CodingFleet.
📊 Key Findings
- GLM 5.1 leads SWE-bench Pro: 58.4% vs 55.4% (+3.0). GLM briefly held the #1 Pro spot in April 2026 — the first Chinese and first open-weight model to top the leaderboard. Also leads HLE with tools (50.4% vs 48.2%).
- V4 Pro Max dominates everything else: Terminal-Bench +4.4, GPQA +3.9, HMMT +5.8, HLE +3.0, MMLU-Pro +1.5. GLM's Pro victory is real — but it's isolated. On every other coding and reasoning benchmark, V4 Pro Max leads.
- V4 Pro Max is 3.5× cheaper: $0.87 vs $3.08 per 1M output. Both MIT-licensed. Both open-weight. But V4 Pro Max's permanent 75% discount from DeepSeek creates a chasm in total cost of ownership.
- V4 Pro Max has 5× larger context: 1M vs 200K tokens. For full-codebase analysis, long agent sessions, and multi-file refactors, V4 Pro Max's native 1M context is transformative. GLM's 200K is serviceable but constrained.
- GLM was trained entirely on Huawei Ascend 910B chips — zero NVIDIA GPUs. A geopolitical milestone. V4 Pro Max uses traditional NVIDIA clusters.
Compare models on your own code at CodingFleet. See the SWE-bench Pro and Terminal-Bench leaderboards. Also: V4 Pro vs Qwen 3.7 Max · Pricing Calculator · GPT-5.5 vs V4 Pro.
Benchmark Comparison
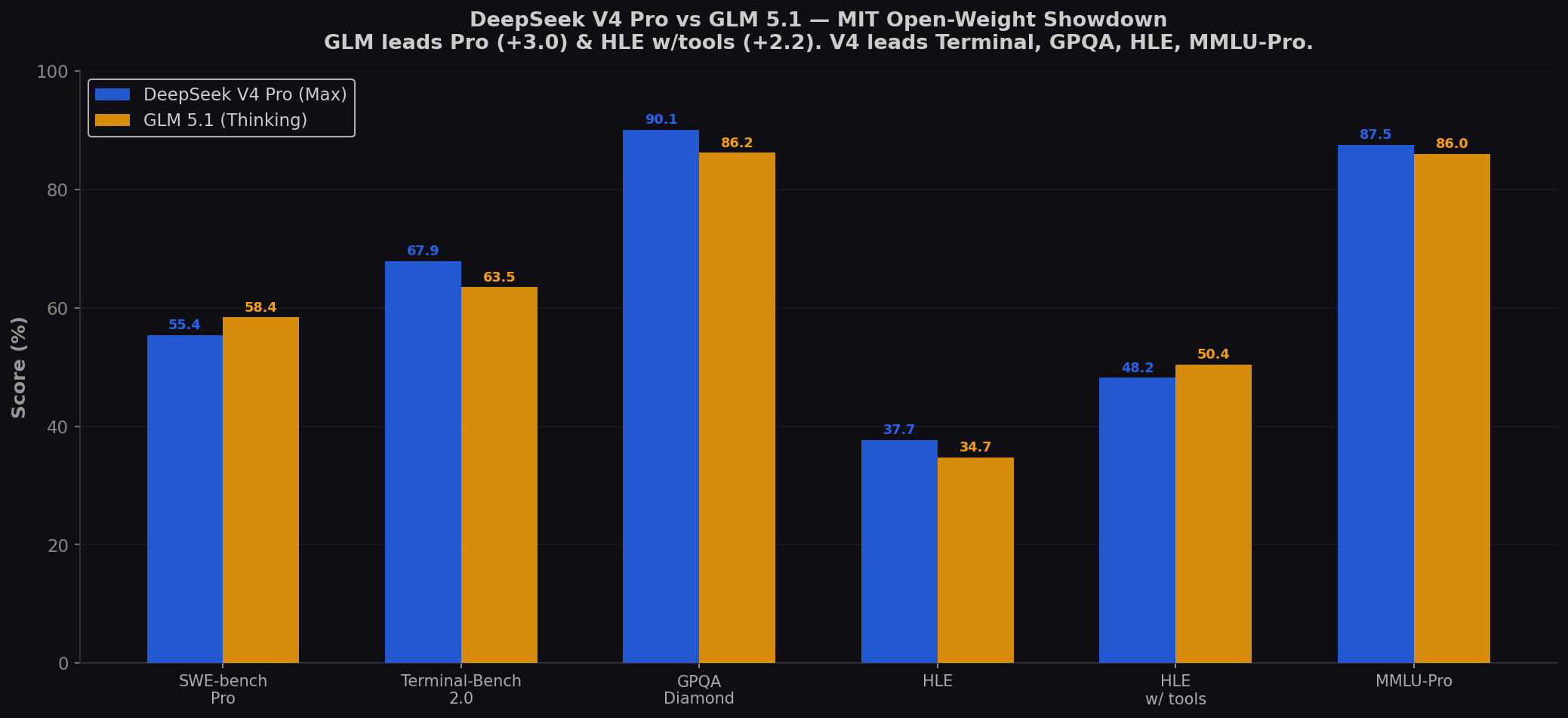
| Benchmark | DeepSeek V4 Pro Max | GLM 5.1 (Thinking) | Winner |
|---|---|---|---|
| SWE-bench Pro | 55.4% | 58.4% | GLM (+3.0) |
| SWE-bench Verified | 80.6% | 77.8%* | V4 Pro Max (+2.8) |
| Terminal-Bench 2.0 | 67.9% | 63.5% | V4 Pro Max (+4.4) |
| LiveCodeBench | 93.5% | — | V4 Pro Max |
| Codeforces Rating | 3206 | — | V4 Pro Max |
| GPQA Diamond | 90.1% | 86.2% | V4 Pro Max (+3.9) |
| HLE | 37.7% | 34.7% | V4 Pro Max (+3.0) |
| HLE w/ tools | 48.2% | 50.4% | GLM (+2.2) |
| MMLU-Pro | 87.5% | 86.0% | V4 Pro Max (+1.5) |
| HMMT Feb 2026 | 95.2% | 89.4% | V4 Pro Max (+5.8) |
| BrowseComp | 83.4% | 79.3% | V4 Pro Max (+4.1) |
| MCP Atlas | 73.6% | 71.8% | V4 Pro Max (+1.8) |
| SWE Multilingual | 76.2% | 73.3% | V4 Pro Max (+2.9) |
| Apex Shortlist | 90.2% | 72.4% | V4 Pro Max (+17.8) |
| Code Arena (Elo) | — | 1530 (#3) | GLM |
Sources: DeepSeek V4 Model Card — all V4 Pro Max and GLM-5.1 scores. Additional: Serenities AI, OpenRouter. *SWE-bench Verified: GLM-5.1 not published, shown is GLM-5 baseline. "—" means not published.
MIT Open-Weight Radar

The radar reveals the asymmetry. GLM 5.1 spikes on two axes: SWE-bench Pro and HLE with tools — its signature strengths. V4 Pro Max dominates the other four — Terminal-Bench, GPQA, MMLU-Pro, and Context Window (1M vs 200K — a 5× gap). GLM's Pro lead is real but isolated; V4 Pro Max wins on breadth.
Pricing & Architecture
| Spec | DeepSeek V4 Pro Max | GLM 5.1 | Winner |
|---|---|---|---|
| Output Price /1M tok | $0.87 | $3.08 | V4 Pro Max (3.5× cheaper) |
| Input Price /1M tok | $0.435 | $0.98 | V4 Pro Max (2.3×) |
| Cached Input /1M tok | $0.0036 | $0.05 | V4 Pro Max (13.9×) |
| Batch/Flex Discount | Permanent 75% off | 50% (Batch) | V4 Pro Max |
| Context Window | 1M tokens | 200K tokens | V4 Pro Max (5×) |
| Max Output | 384K tokens | 128K tokens | V4 Pro Max (3×) |
| Architecture | 1.6T MoE / 49B active | 754B MoE / 40B active | V4 Pro Max |
| Training Data | 32T+ tokens | 28.5T tokens | V4 Pro Max |
| Training Hardware | NVIDIA GPUs | Huawei Ascend 910B | GLM (NVIDIA-free) |
| License | MIT | MIT | Tie |
| Speed | ~33 tok/s | ~58-128 tok/s | GLM (faster) |
| Subscription Option | API only | Coding Plan from $3/month | GLM |
Where Each Model Wins
GLM 5.1 — The Pro Leader & NVIDIA-Free Pioneer
- SWE-bench Pro 58.4% — #1 at launch. The first open-weight model to top the Pro leaderboard. The 3-point lead over V4 Pro Max is genuine and independently verified from the DeepSeek model card.
- HLE with tools 50.4% — best-in-class agentic reasoning. When paired with tools, GLM 5.1 achieves the highest HLE score among open-weight models.
- 8-hour autonomous coding sessions. Purpose-built for long-horizon agentic workflows — planning, executing, and self-correcting over multi-hour sessions.
- Trained on Huawei Ascend 910B — zero NVIDIA GPUs. For organizations concerned about US chip dependency, GLM 5.1 proves frontier coding models can be built on alternative hardware.
- Faster inference: 58-128 tok/s. With 40B active parameters (vs V4's 49B), GLM achieves higher throughput. Better for interactive coding sessions.
- Code Arena Elo 1530 — highest open-source ranking. Developer preference validates the Pro benchmark. #3 overall behind only Claude Opus 4.8 and GPT-5.5.
DeepSeek V4 Pro Max — The All-Round King
- Wins 12 of 14 benchmarks. Terminal-Bench, GPQA, HLE, MMLU-Pro, HMMT, BrowseComp, MCP Atlas, SWE Multilingual, Apex Shortlist — V4 Pro Max leads every single one. GLM's Pro victory is real, but surrounded by blue.
- LiveCodeBench 93.5% — global #1. For algorithms and competitive programming, V4 Pro Max is the best model in the world — proprietary or open-weight.
- 3.5× cheaper: $0.87 vs $3.08 per 1M output. Permanent 75% discount. A 100M token/month pipeline costs $87 vs $308 — a $221 monthly difference.
- 1M native context — 5× GLM's 200K. 384K max output vs 128K. For full-codebase analysis and large-scale refactors, the context advantage is decisive.
- 1.6T total parameters — 2.1× larger. 57.9% SimpleQA-Verified vs GLM's 38.1% — a 19.8-point factual accuracy advantage for knowledge-heavy coding.
When to Use Which
| Scenario | Use | Why |
|---|---|---|
| Production bug fixing (real repos) | GLM 5.1 | 58.4% Pro vs 55.4%. +3.0 lead. |
| Agentic coding with tools (HLE) | GLM 5.1 | 50.4% vs 48.2%. +2.2 lead. |
| Claude Code compatible workflows | GLM 5.1 | 94.6% of Opus 4.6. Code Arena #3. |
| NVIDIA-free infrastructure | GLM 5.1 | 100% Huawei Ascend trained. |
| Algorithm & competitive programming | DeepSeek V4 Pro Max | 93.5% LiveCodeBench. 3206 Codeforces. |
| Cost-sensitive high-volume | DeepSeek V4 Pro Max | $0.87 vs $3.08. 3.5× cheaper. |
| Full-codebase context (1M) | DeepSeek V4 Pro Max | 1M vs 200K. 5× larger context. |
| Knowledge-heavy coding / factual accuracy | DeepSeek V4 Pro Max | SimpleQA 57.9% vs 38.1%. |
| Self-hosting / fine-tuning | DeepSeek V4 Pro Max | MIT weights on Hugging Face today. |
Conclusion: Two MIT Philosophies, Two Different Winners
GLM 5.1 is the Pro leader for a reason. The 58.4% SWE-bench Pro score is independently verified from DeepSeek's own model card comparison table. It was the first open-weight model to top the Pro leaderboard — and the first Chinese model to do so. For real GitHub issue resolution, GLM 5.1 is the strongest open-weight option. The Huawei Ascend training story adds geopolitical significance that no other model can claim.
DeepSeek V4 Pro Max is the better model for almost everything else. Terminal-Bench, GPQA, LiveCodeBench, HMMT, MMLU-Pro, BrowseComp, MCP Atlas, SWE Multilingual, Apex Shortlist — V4 Pro Max leads every single one. The 3.5× price advantage, 5× context window, and MIT weights available today make it the default choice for cost-sensitive, large-context, and algorithm-heavy workflows. The only reasons to choose GLM over V4 Pro Max are if you specifically need the highest Pro score, NVIDIA-free infrastructure, or Claude Code integration.
Both are MIT-licensed. Both are Chinese. Both prove that open-weight models compete at the frontier. The choice: GLM 5.1 for Pro supremacy and Huawei sovereignty. DeepSeek V4 Pro Max for everything else — at 3.5× lower cost.
20+ LLMs available. Side-by-side testing. Both MIT models ready.
Sources: DeepSeek V4 Model Card (all head-to-head comparison data) | Serenities AI GLM-5.1 Review | OpenRouter | BuildFastWithAI April 2026 | Spheron Deployment Guide | SWE-bench Pro Leaderboard | Terminal-Bench Leaderboard.