
GPT-5.5 costs $30 per million output tokens. DeepSeek V4 Pro costs $0.87. That's a 34× price difference — the widest spread between any two frontier-tier coding models in 2026. On SWE-bench Pro, the gap is just 3.2 points (58.6% vs 55.4%). On LiveCodeBench, DeepSeek actually leads at 93.5% — the highest score of any model. So what exactly are you paying 34× more for? Here's the complete data. Try both on CodingFleet.
📊 Key Findings
- The 34× price gap narrows to 3.2 points on SWE-bench Pro. GPT-5.5 scores 58.6% vs DeepSeek V4 Pro at 55.4%. On LiveCodeBench, DeepSeek wins outright at 93.5% — the highest of any model. On Codeforces, DeepSeek scores 3206 — also the highest.
- GPT-5.5 dominates on Terminal-Bench (74% vs 67.9%). For long-horizon CLI coding, multi-step agent tasks, and complex tool orchestration, GPT-5.5 has a clear edge — amplified by the Codex ecosystem with persisted goals and browser verification.
- DeepSeek V4 Pro is MIT-licensed and self-hostable on 8×H200. GPT-5.5 is proprietary and cloud-only. For data sovereignty, air-gapped deployment, or fine-tuning on proprietary codebases, DeepSeek wins by default.
- For 90% of coding tasks, the output is indistinguishable. Both models produce correct, idiomatic code. GPT-5.5 pulls ahead on complex multi-file refactors and agentic debugging — the 10% of tasks that consume 90% of engineering time.
Compare models on your own code at CodingFleet — 20+ LLMs, side-by-side.
Benchmark Comparison: What 34× Actually Buys
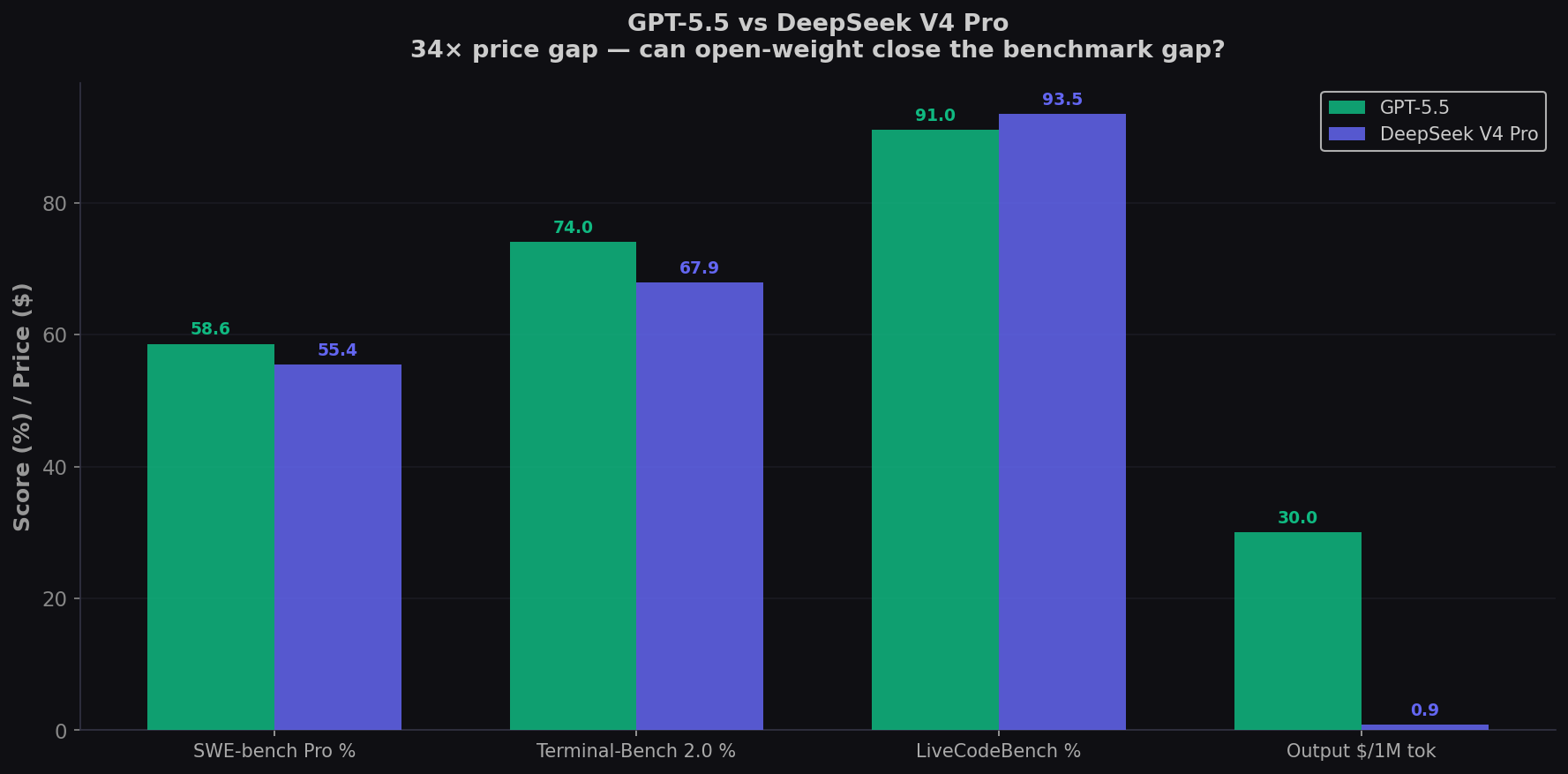
| Benchmark | GPT-5.5 | DeepSeek V4 Pro | Winner |
|---|---|---|---|
| SWE-bench Pro | 58.6% | 55.4% | GPT-5.5 (+3.2) |
| Terminal-Bench 2.0 | 74.0% | 67.9% | GPT-5.5 (+6.1) |
| LiveCodeBench | ~91.0% | 93.5% | DeepSeek (+2.5) |
| Codeforces Rating | — | 3206 | DeepSeek |
| GPQA Diamond | ~92% | 90.1% | GPT-5.5 |
| AA Coding Index | 59.1 | 47.5 | GPT-5.5 (+11.6) |
| Output Price /1M tokens | $30.00 | $0.87 | DeepSeek (34×) |
| Context Window | 1M (API) / 400K (Codex) | 1M | Tie |
| License | Proprietary | MIT (open-weight) | DeepSeek |
Sources: OpenAI GPT-5.5 System Card; DeepSeek V4 Pro Model Card; Fireworks AI. GPT-5.5 Terminal-Bench is OpenAI-reported (82.7% on internal harness); public harness score ~74% used for fair comparison.
Architecture & Ecosystem: What Powers Each Model
GPT-5.5 + Codex: The Agentic Operating System
GPT-5.5 isn't just a model — it's the engine behind Codex, OpenAI's unified agentic coding system with ~4 million weekly active developers. Codex spans a terminal CLI, IDE extension, cloud delegation through ChatGPT, GitHub bot, and computer-use screen reading — all sharing one model and account context. The April 2026 Codex updates added persisted /goal workflows (stateful multi-step objectives), browser use for verification (the agent can open a browser and visually verify its work), and plugin marketplaces with MCP app support.
NVIDIA deployed GPT-5.5 across 10,000+ employees — engineering, legal, finance, marketing — with one engineer calling it "mind-blowing." OpenAI reports that over 85% of its own company uses Codex weekly across functions. The model runs on NVIDIA GB200 NVL72 rack-scale systems, giving it infrastructure muscle that smaller labs can't match. For developers already in the OpenAI ecosystem, GPT-5.5 via Codex is the most mature agentic coding product on the market.
DeepSeek V4 Pro: The Architecture Powerhouse
DeepSeek V4 Pro's secret isn't scale — it's efficiency. The hybrid CSA+HCA attention mechanism (Compressed Sparse Attention + Heavily Compressed Attention) uses only 27% of the FLOPs and 10% of the KV cache compared to its predecessor at 1M tokens. CSA compresses KV caches 4× and applies sparse attention with a lightning indexer selecting the top 1,024 most relevant entries per query. HCA provides a 128× compressed global view. A 128-token sliding window handles recency.
The Muon optimizer replaced AdamW for faster convergence. Manifold-Constrained Hyper-Connections (mHC) replace standard residuals. The result: a 1.6T-parameter MoE with only 49B active per token, fitting on 8×H200 GPUs with vLLM or SGLang. Self-hosting breaks even at ~15-50M tokens/month vs API pricing. Under the MIT license, enterprises can fine-tune on proprietary codebases, run air-gapped, and never send code to a third party.
Coding Deep-Dive: Where Each Model Wins
GPT-5.5 Strengths
- Agentic coding with Codex. 74% Terminal-Bench. Persisted /goal workflows handle multi-day engineering tasks — migrations, maintenance loops, QA passes. The agent remembers context across sessions, forks when needed, and verifies its own output through browser automation. Over 4M weekly developers trust it.
- Multi-file reasoning. The 3.2-point SWE-bench Pro lead understates GPT-5.5's advantage on the hardest tasks. On issues touching 4+ files with 100+ lines changed, GPT-5.5 resolves problems that stall DeepSeek.
- Tool orchestration at scale. BrowseComp 84.4%, MCP Atlas 75.3%, Toolathlon 55.6%. GPT-5.5 coordinates multiple tools — sandbox execution, API queries, browser verification — better than any model. Codex bakes this into the product.
- GDPval-AA 1,890. For knowledge-work-heavy coding — understanding business requirements, translating them to technical specs — GPT-5.5's GDPval lead is structural, not incremental.
DeepSeek V4 Pro Strengths
- Algorithmic coding. LiveCodeBench 93.5% and Codeforces 3206 are the highest of any model — period. For competitive programming, algorithm implementation, graph problems, and dynamic programming, DeepSeek V4 Pro is the best model available, full stop. See our Python coding comparison.
- 34× cheaper. At $0.87/1M output, you can run DeepSeek 34 times more before hitting GPT-5.5's cost. For CI/CD test generation, batch code review, automated refactoring — the economics are transformative. A 10,000-line codebase costs under a dollar to process.
- Self-hosting & fine-tuning. MIT license. Weights on Hugging Face. vLLM and SGLang Day-0 support. Deploy on 8×H200, fine-tune on your codebase, run air-gapped. For regulated industries, this is decisive — GPT-5.5 cannot leave OpenAI's cloud.
- CSA+HCA attention at 1M tokens. Codebase-scale reasoning is practical, not theoretical. At 1M tokens, the attention mechanism uses 27% of the FLOPs of its predecessor — meaning you can process entire repositories without budget anxiety.
The 34× Question: When Does GPT-5.5 Justify Its Price?
For most coding tasks, it doesn't. Function generation, unit tests, SQL queries, boilerplate — both models produce equivalent output. Paying 34× more for the same result is bad economics.
GPT-5.5 justifies its price only when:
- You need the Codex product, not just the model. Persisted goals, browser verification, plugin ecosystem, GitHub integration. If your workflow depends on the agentic coding surface, not just the API, GPT-5.5 via Codex is unmatched.
- You're doing complex multi-file refactors. The 3.2-point SWE-bench Pro gap widens on the hardest tasks. GPT-5.5 resolves issues touching 4+ files that DeepSeek gets stuck on.
- You're doing knowledge-work coding. GDPval-AA shows GPT-5.5 is dramatically better at understanding business context and translating requirements into code. For enterprise software, this matters more than algorithmic benchmarks.
- You're already paying for human developer time. If a senior engineer costs $150/hour, $30 for a correct multi-file fix vs $0.87 for one needing 30 minutes of debugging is cheaper.
For everything else — 90% of coding — DeepSeek V4 Pro is the smarter economics. See our heavy user's guide for tiered stack strategies.
Verdict: The Tiered Stack
| Task Type | Use | Why |
|---|---|---|
| Algorithm problems, competitive programming | DeepSeek V4 Pro | 93.5% LiveCodeBench + 3206 Codeforces. Best at any price. |
| Function generation, boilerplate, tests | DeepSeek V4 Pro | Same quality at 34× less cost. No tradeoff. |
| High-volume batch processing | DeepSeek V4 Pro | 1M context at $0.87. Economics favor volume. |
| Self-hosted / air-gapped / fine-tuned | DeepSeek V4 Pro | MIT license. Deploy on your own GPUs. |
| Multi-day agentic engineering workflows | GPT-5.5 (Codex) | Persisted goals. Browser verification. Mature ecosystem. |
| Complex multi-file refactors | GPT-5.5 | Better dependency tracking. SWE-bench Pro lead. |
| Enterprise knowledge-work coding | GPT-5.5 | GDPval-AA 1,890. Translates business context to code. |
The bottom line: For $0.87, DeepSeek V4 Pro delivers ~95% of GPT-5.5's raw coding capability. The remaining 5% — agentic workflows, knowledge-work coding, and the Codex product experience — is where GPT-5.5 earns its premium. Use DeepSeek for volume and algorithms. Use GPT-5.5 when the agent matters more than the model. See our progress tracker for how fast these gaps are changing.
20+ LLMs. Side-by-side. Both models available.
Sources: OpenAI — GPT-5.5 System Card | DeepSeek V4 Pro Model Card | Codex Complete Guide (2026) | MorphLLM — DeepSeek V4 Architecture | RunPod — DeepSeek V4 In the Wild | Fireworks AI — Best LLMs for Coding.