
Two Chinese AI labs. Two completely different bets on the future of coding. DeepSeek V4 Pro (April 24, 2026): 1.6T-parameter MoE, MIT-licensed, self-hostable, 93.5% LiveCodeBench — the highest of any model. 3206 Codeforces Rating. $0.87/1M output (permanent 75% discount). Qwen 3.7 Max (May 19, 2026): proprietary "Agent Frontier," 60.6% SWE-bench Pro — the highest proprietary score. 35-hour autonomous runs. 96% Kernel Bench win rate. $7.50/1M output. One is the open-weight algorithmic specialist that costs less than a dollar per million tokens. The other is the proprietary agent powerhouse that runs autonomously while you sleep. Here's the complete data. Test both on CodingFleet.
📊 Key Findings
- Qwen leads 5 of 6 major coding/reasoning benchmarks. SWE-bench Pro (+5.2), Terminal-Bench (+1.8), GPQA Diamond (+2.3), HLE (+3.7), Apex Math (+6.2). For production bug fixing and reasoning-heavy coding, Qwen is measurably better.
- DeepSeek dominates algorithmic coding. LiveCodeBench 93.5% (#1 globally). Codeforces 3206 (#1 globally). For competitive programming, algorithm implementation, and math-heavy code, DeepSeek is the best model at any price.
- DeepSeek is 8.6× cheaper: $0.87 vs $7.50 per 1M output. This is a permanent 75% discount — not a promotion. Cache hit input: $0.003625/1M (99.2% discount). Self-hosting breaks even at even lower volumes.
- DeepSeek is MIT-licensed and self-hostable. Qwen is proprietary API-only. Weights on Hugging Face. Deploy on your GPUs. Fine-tune on your codebase. Qwen requires Alibaba Cloud.
Compare models on your own code at CodingFleet — 20+ LLMs, side-by-side.
Benchmark Comparison
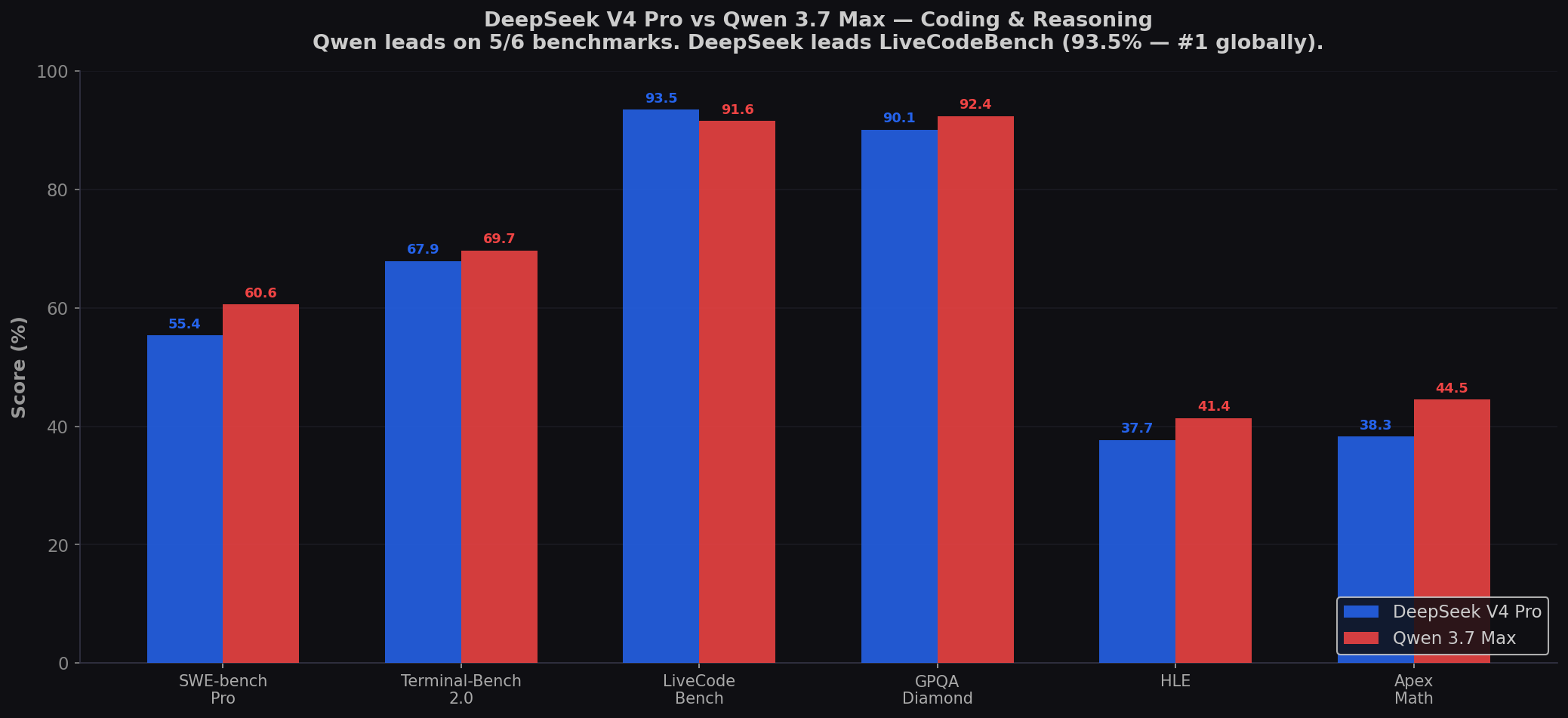
| Benchmark | DeepSeek V4 Pro | Qwen 3.7 Max | Winner |
|---|---|---|---|
| SWE-bench Pro | 55.4% | 60.6% | Qwen (+5.2) |
| SWE-bench Verified | 80.6% | 80.4% | Tie (+0.2 DeepSeek) |
| Terminal-Bench 2.0 | 67.9% | 69.7% | Qwen (+1.8) |
| LiveCodeBench | 93.5% | 91.6% | DeepSeek (+1.9) |
| Codeforces Rating | 3206 | — | DeepSeek |
| GPQA Diamond | 90.1% | 92.4% | Qwen (+2.3) |
| HLE | 37.7% | 41.4% | Qwen (+3.7) |
| HMMT 2026 Feb | 95.2% | 97.1% | Qwen (+1.9) |
| Apex Math Reasoning | 38.3 | 44.5 | Qwen (+6.2) |
| IMOAnswerBench | 89.8 | 90.0 | Qwen (+0.2) |
| MMLU-Pro | 87.5 | 89.6 | Qwen (+2.1) |
| Kernel Bench L3 (win rate) | 54% | 96% | Qwen (+42) |
| MCP-Atlas (tool use) | 73.6% | 76.4% | Qwen (+2.8) |
| AA Intelligence Index | 52.0 | 56.6 | Qwen (+4.6) |
| Output Price /1M tok | $0.87 | $7.50 | DeepSeek (8.6× cheaper) |
| Input Price /1M tok (cache miss) | $0.435 | $2.50 | DeepSeek (5.7× cheaper) |
| Input Price /1M tok (cache hit) | $0.003625 | $0.25 | DeepSeek (69× cheaper) |
| Context Window | 1M | 1M | Tie |
| Max Output | 384K | 65K | DeepSeek (5.9×) |
| License | MIT (open-weight) | Proprietary (API-only) | DeepSeek |
| Self-hosting | Yes (8×H200) | No | DeepSeek |
Sources: DeepSeek V4 Pro Model Card; DeepSeek Official Pricing (permanent 75% discount); Yotta Labs — Qwen 3.7 Max; Qwen Official — 3.7 Blog; MorphLLM — V4 Architecture; Artificial Analysis. Qwen scores vendor-published vs Opus 4.6 and DeepSeek V4 Pro. DeepSeek scores from Hugging Face model card. Pricing from official API docs as of June 2026.
Agentic Coding Radar
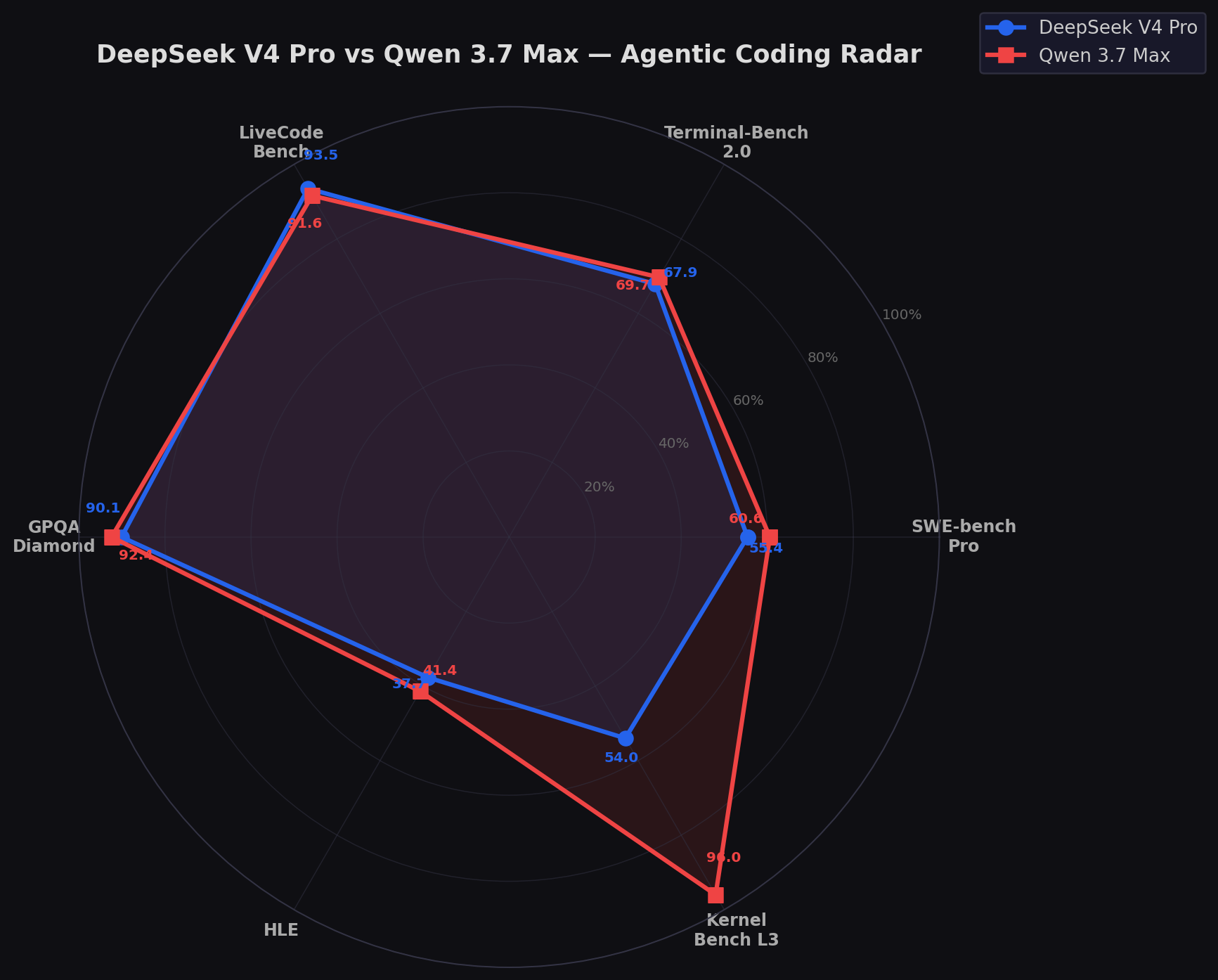
The radar reveals the fundamental asymmetry. Qwen's red ring encircles DeepSeek's blue on nearly every axis — Pro, Terminal-Bench, GPQA, HLE. But DeepSeek spikes dramatically on LiveCodeBench (93.5%) and Kernel Bench. This isn't a better/worse comparison. It's two models optimized for different definitions of coding excellence.
Architecture & Philosophy
DeepSeek V4 Pro: The Open-Weight Algorithm Specialist
Released April 24, 2026 under the MIT license. A 1.6-trillion parameter MoE with 49B active per token, 1M context window, 384K max output, and a revolutionary hybrid CSA+HCA attention mechanism using 27% of the FLOPs and 10% of the KV cache of its predecessor. The Muon optimizer replaced AdamW. MoE experts use FP4 precision with FP8 for other parameters. Three reasoning modes: Non-Think, Think High, Think Max. Supports both OpenAI and Anthropic API formats.
The result: 93.5% LiveCodeBench and 3206 Codeforces — both #1 globally. For algorithm implementation and competitive programming, DeepSeek V4 Pro is unmatched. Weights on Hugging Face. Self-host on 8×H200 GPUs via vLLM or SGLang. Available across 14 providers on OpenRouter. Serves 4.86T tokens/month — 14× more than Qwen 3.7 Max. See our DeepSeek V4 Flash review.
Qwen 3.7 Max: The Proprietary Agent Frontier
Launched May 19, 2026. Proprietary API-only model built for long-horizon autonomous execution: up to 35 hours continuous operation, 1,000+ sequential tool calls. "Cross-harness generalization" — working across diverse agent frameworks without framework-specific tuning. Native Anthropic API protocol support at the endpoint level — drop Qwen into Claude Code with zero migration. Also supports OpenAI spec.
On Kernel Bench L3: 96% win rate (vs DeepSeek's 54%). Achieved 10.0× kernel speedup on unseen hardware. 60.6% SWE-bench Pro — highest proprietary score, ahead of GPT-5.5 (58.6%). 1M context, 65K max output. AA Intelligence Index: 56.6 (#5 globally, #1 Chinese model). See our GPT-5.5 vs Qwen comparison.
Where Each Model Wins at Coding
DeepSeek V4 Pro — The Algorithm King
- LiveCodeBench 93.5% — #1 globally. Codeforces 3206 — #1 globally. For competitive programming, algorithm design, data structures, and math-heavy code, DeepSeek is unmatched at any price.
- 8.6× cheaper output ($0.87 vs $7.50). Permanent 75% discount. Input cache hit: $0.003625/1M (99.2% off). A full-codebase analysis costs $0.87 instead of $7.50. Self-hosting breaks even at even lower volumes given these rates.
- MIT license = self-hosting freedom. Deploy on your GPUs. Fine-tune on proprietary codebases. Air-gapped deployment. For regulated industries, this is the only option between these two.
- 384K max output — 5.9× Qwen's 65K. For generating entire files, documentation suites, or test harnesses in a single pass.
Qwen 3.7 Max — The Bug Fixer & Agent Operator
- SWE-bench Pro 60.6% vs 55.4% (+5.2 points). For real-world GitHub issue resolution — multi-file changes, production repos — Qwen is measurably better.
- 96% Kernel Bench L3 win rate vs DeepSeek's 54%. For GPU kernel optimization and hardware-specific code generation, Qwen is in a different league. 1.98× median speedup on unseen hardware.
- Anthropic API compatibility — drop into Claude Code. For teams in the Claude ecosystem, Qwen is a drop-in upgrade. Dual OpenAI + Anthropic compatibility. See our Opus 4.8 vs Qwen.
- 35-hour autonomous runs, 1,000+ tool calls. GPQA Diamond 92.4% (+2.3 over DeepSeek). Apex Math 44.5 (+6.2). The stronger STEM model.
Pricing: The 8.6× Reality
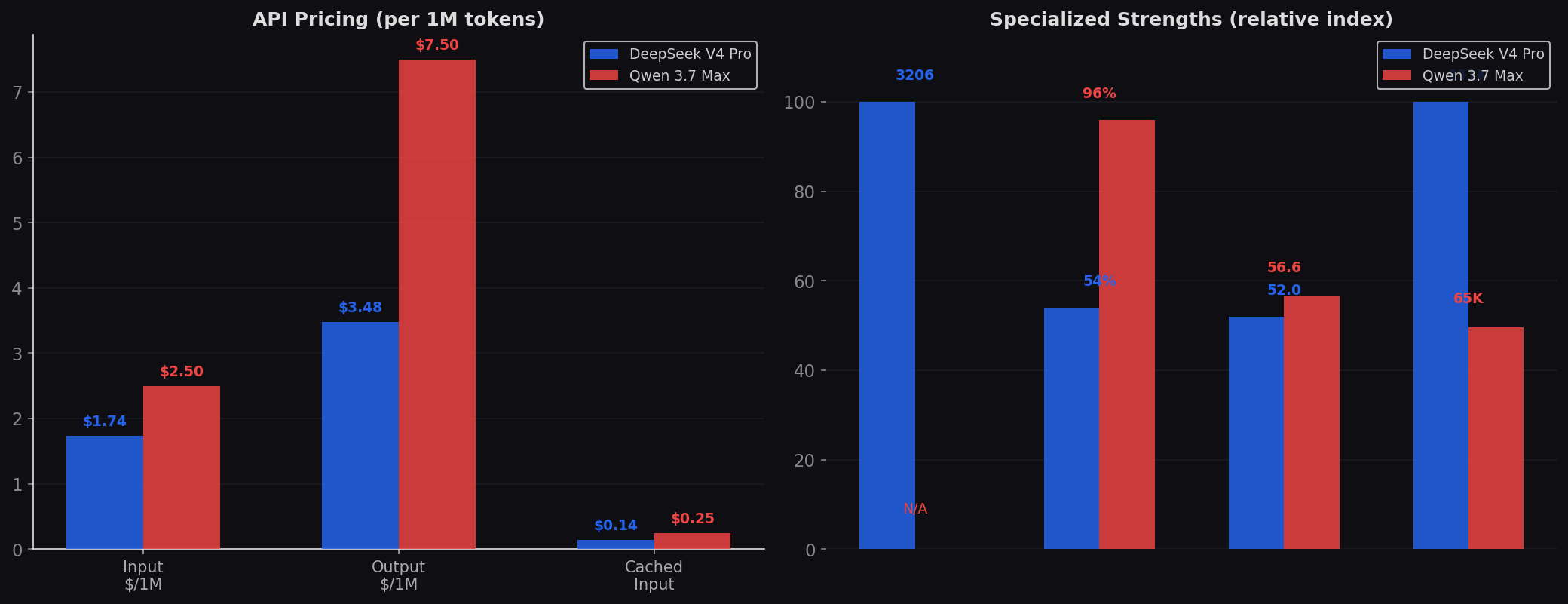
| Detail | DeepSeek V4 Pro | Qwen 3.7 Max |
|---|---|---|
| Input (cache miss) | $0.435 / 1M | $2.50 / 1M |
| Input (cache hit) | $0.003625 / 1M | $0.25 / 1M |
| Output | $0.87 / 1M | $7.50 / 1M |
| Discount type | Permanent 75% off | Promo 50% off (thru June 22) |
| Promo output | $0.87 (always) | $3.75 / 1M (temporary) |
| Self-hosting | Yes (MIT, 8×H200) | No (proprietary) |
| OpenRouter activity (30d) | 4.86T tokens | 349B tokens |
| Providers | 14+ | Alibaba Cloud + OpenRouter |
Sources: DeepSeek Official API Pricing (June 2026); OpenRouter — Qwen 3.7 Max. DeepSeek's 75% discount is permanent. Qwen's 50% discount expires June 22, 2026.
The economic reality: DeepSeek V4 Pro costs 8.6× less on output, 5.7× less on input, and 69× less on cached input ($0.003625 vs $0.25). These are permanent rates — not promotional. For high-volume coding pipelines, the savings are measured in hundreds of dollars per day. Plus MIT self-hosting means you can break free of per-token pricing entirely. Qwen's June promo narrows the output gap to 4.3×, but only temporarily. For long-term production deployments, the economic case for DeepSeek is overwhelming.
When to Use Which
| Scenario | Use | Why |
|---|---|---|
| Production bug fixing (real repos) | Qwen 3.7 Max | 60.6% Pro vs 55.4%. +5.2 point lead. |
| GPU kernel optimization | Qwen 3.7 Max | 96% WR vs 54%. 1.98× speedup. |
| Claude Code / Aider users | Qwen 3.7 Max | Drop-in Anthropic API replacement. |
| Multi-day autonomous agents | Qwen 3.7 Max | 35-hour runs. 1,000+ tool calls. |
| STEM / math-heavy coding | Qwen 3.7 Max | 92.4% GPQA. 44.5 Apex (+6.2). |
| Algorithm & data structures | DeepSeek V4 Pro | 93.5% LiveCodeBench. 3206 Codeforces. |
| Cost-sensitive high-volume | DeepSeek V4 Pro | $0.87 vs $7.50. 8.6× cheaper. Permanent. |
| Self-hosting / data sovereignty | DeepSeek V4 Pro | MIT license. Runs on your GPUs. |
| Large output generation | DeepSeek V4 Pro | 384K vs 65K max output. 5.9× headroom. |
| Fine-tuning on proprietary code | DeepSeek V4 Pro | MIT weights. Fine-tune freely. |
Conclusion: The Specialist vs The Generalist
Qwen 3.7 Max wins on general coding benchmarks. The 5.2-point Pro lead, 96% Kernel Bench win rate, and 35-hour autonomous capability make it the stronger choice for production bug fixing, GPU optimization, and unattended agent workflows. It's the proprietary agent powerhouse — at $7.50/1M.
DeepSeek V4 Pro wins on algorithmic coding, deployment freedom, and economics. The 93.5% LiveCodeBench, 3206 Codeforces, MIT license, self-hosting, and 8.6× lower cost ($0.87 vs $7.50) make it the right choice for algorithm-heavy work, regulated industries, and cost-sensitive high-volume pipelines. At these prices — $0.87 permanent — DeepSeek isn't just cheaper. It makes AI coding free.
The models are complementary: Qwen for the 60% of tasks that look like real GitHub issues. DeepSeek for the 40% that look like competitive programming problems. At $0.87/1M, DeepSeek is the default for everything else.
20+ LLMs available. Side-by-side testing. Both models ready.
Sources: DeepSeek V4 Pro Model Card | DeepSeek Official API Pricing | MorphLLM — V4 Architecture | Yotta Labs — Qwen 3.7 Max | Qwen Official — 3.7 Blog | OpenRouter — Qwen 3.7 Max | Fireworks AI — Best LLMs | Artificial Analysis.