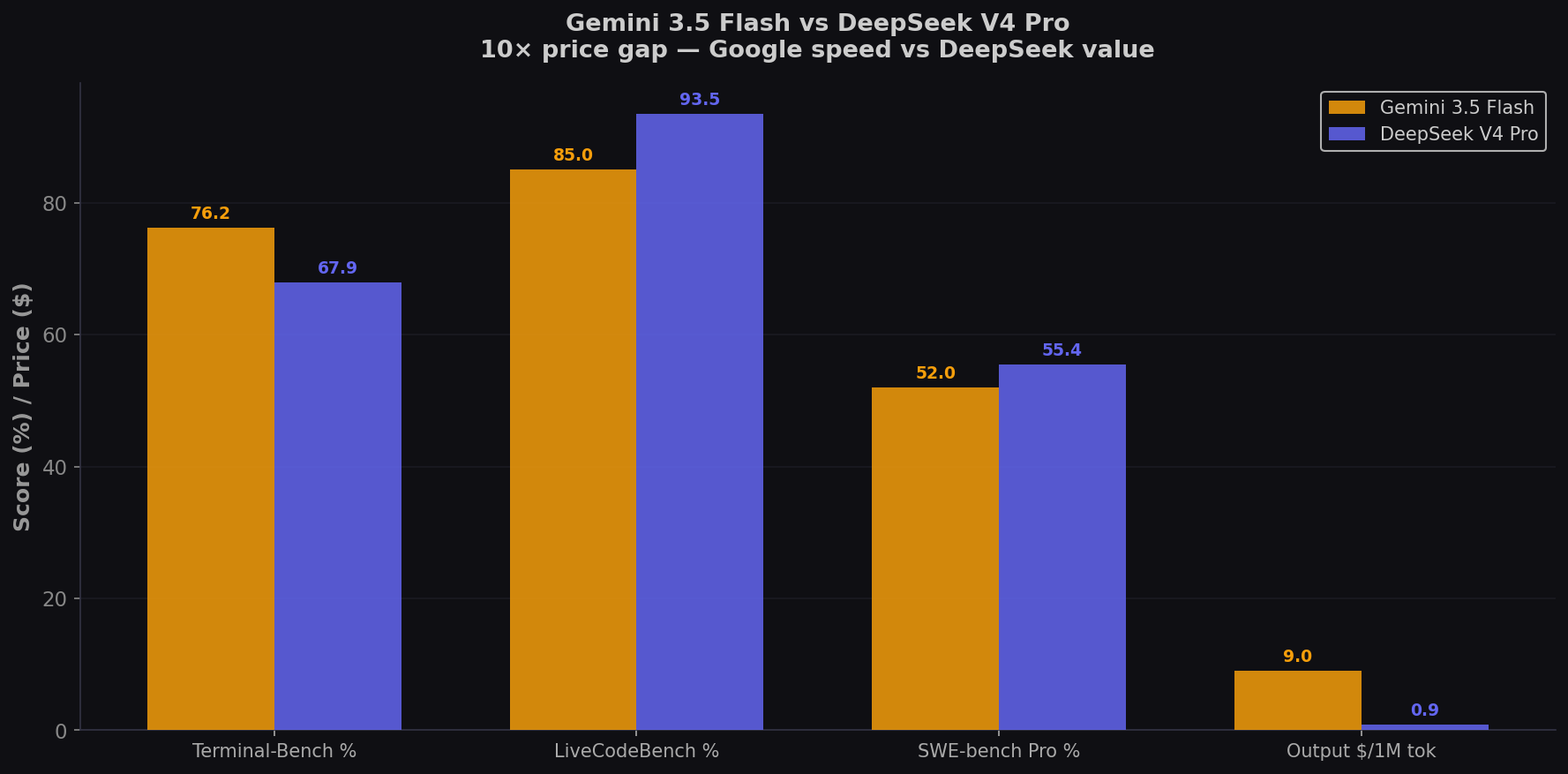
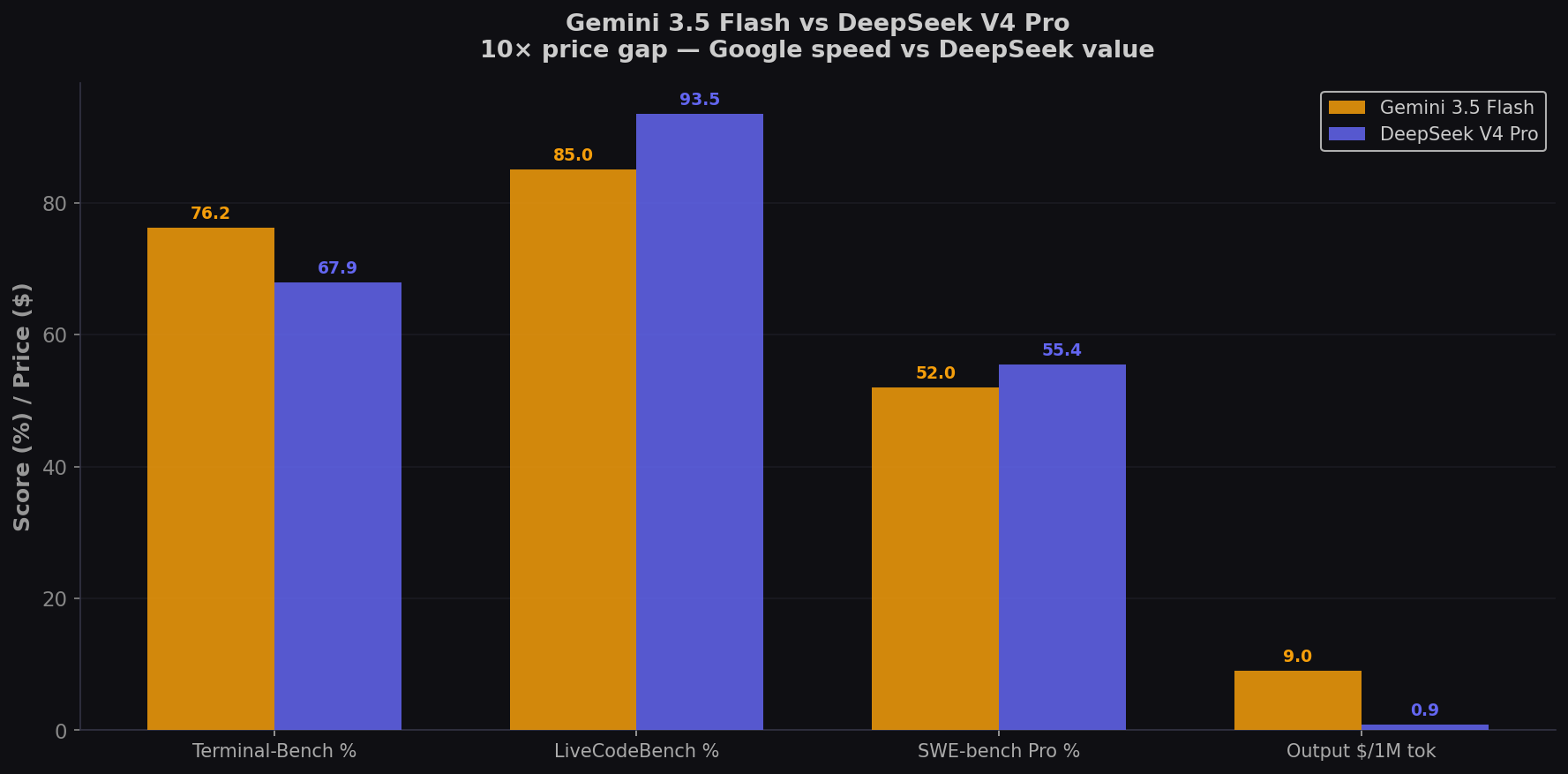
Gemini 3.5 Flash is 4× faster than comparable frontier models and scores 76.2% on Terminal-Bench 2.1 — the best of any Flash-tier model. DeepSeek V4 Pro is 10× cheaper ($0.87 vs $9.00) and scores 93.5% on LiveCodeBench — the highest of any model. They represent completely different philosophies: speed-at-a-premium via Google's planet-scale infrastructure vs depth-for-pennies via MIT-licensed self-hosting. Here's which one fits your coding workflow. Compare on CodingFleet.
📊 Key Findings
- DeepSeek V4 Pro wins on algorithmic benchmarks (93.5% LiveCodeBench vs ~85%). For competitive programming, algorithm implementation, and math-heavy coding, DeepSeek is the best model — at any price.
- Flash wins on agentic CLI coding (76.2% Terminal-Bench vs 67.9%). When coding requires multi-step tool use, environment interaction, and iterative debugging, Flash's 4× speed advantage means 4× more repair cycles per minute.
- 10× price gap. DeepSeek $0.87 vs Flash $9.00 per 1M output. For high-volume coding, DeepSeek is an order of magnitude cheaper. Flash's speed premium matters most for latency-sensitive and agentic workflows.
- DeepSeek is MIT-licensed. Flash runs on Google's infrastructure. Self-hosting freedom vs planet-scale reliability — the deployment decision that shapes everything else.
Compare models on your own code at CodingFleet — 20+ LLMs, side-by-side.
Benchmark Comparison
| Benchmark | Gemini 3.5 Flash | DeepSeek V4 Pro | Winner |
|---|---|---|---|
| Terminal-Bench 2.1 | 76.2% | 67.9% | Flash (+8.3) |
| LiveCodeBench | ~85% | 93.5% | DeepSeek (+8.5) |
| SWE-bench Pro | ~52%* | 55.4% | DeepSeek (+3.4) |
| MCP Atlas | 83.6% | 73.6% | Flash (+10.0) |
| Codeforces Rating | — | 3206 | DeepSeek |
| Output Price /1M tok | $9.00 | $0.87 | DeepSeek (10.3×) |
| Context Window | 1M | 1M | Tie |
| Speed (relative) | 4× faster than frontier | ~33 tok/s | Flash |
| Thinking Levels | 4 (minimal→high) | 3 (Non-Think→Max) | Flash |
| License | Proprietary | MIT (open-weight) | DeepSeek |
| Multimodal | Text + Image + Audio + Video | Text only | Flash |
*Flash SWE-bench Pro estimated. Sources: LLM Stats; DeepSeek V4 Pro Model Card.
Architecture & Ecosystem
Gemini 3.5 Flash: Google's Speed + Platform
Flash lands in the top-right quadrant of the Artificial Analysis Intelligence Index — frontier intelligence at Flash latency. The model supports four thinking levels (minimal, low, medium, high) for granular quality-speed-cost tradeoffs. It accepts text, images, audio, and video files with a 1M-token context window and 64K output limit. Flash is available across Google's entire surface area: AI Studio, Antigravity (agent-first development platform), Enterprise Agent Platform, Android Studio, the Gemini app, and AI Mode in Search.
Antigravity is the differentiator. It provides the orchestration harness for long-horizon agentic tasks — Managed Agents for cloud-hosted execution, Spark for background Workspace agents, and Search integration for generating custom interfaces. For teams already on Google Cloud, Flash integrates natively with existing infrastructure, IAM, and enterprise SLAs. Google is positioning 3.5 Flash as the center of gravity for its entire agentic strategy — not just a model, but an agent runtime disguised as infrastructure.
DeepSeek V4 Pro: Algorithmic Depth, MIT Freedom
CSA+HCA attention uses 27% of the FLOPs and 10% of the KV cache of its predecessor at 1M tokens. The Muon optimizer and mHC residual connections maximize efficiency. LiveCodeBench 93.5% and Codeforces 3206 make it the best algorithmic coding model available. Under MIT license, it can be self-hosted on 8×H200 GPUs via vLLM or SGLang — fine-tuned on proprietary codebases, deployed air-gapped, never sending code to third parties.
For enterprises with data sovereignty requirements, DeepSeek is the only option. Flash requires sending code to Google's cloud. For regulated industries — defense, finance, healthcare — this distinction overrides every benchmark comparison. The self-hosting economics also favor DeepSeek for high-volume use: break-even vs API pricing at ~15-50M tokens/month.
Coding Deep-Dive
Gemini 3.5 Flash — Speed as Capability
- Agentic CLI coding leader. 76.2% Terminal-Bench 2.1, 83.6% MCP Atlas. For autonomous coding agents that read repos, run tests, interpret output, and iterate — Flash's 4× speed means it completes 4 repair cycles in the time other models do one.
- Google's agent platform. Antigravity + Managed Agents + Spark + Search. Flash isn't just an API — it's the reasoning engine for Google's entire agentic ecosystem. For teams building on Google Cloud, the infrastructure is already provisioned.
- Thinking level granularity. Four modes let you optimize per-task. Use 'high' for complex debugging, 'low' for boilerplate generation. This makes Flash cost-effective across a wider spectrum than binary thinking on/off.
- Multimodal input. Text, images, audio, and video files as input. While not generating video code like M3, Flash can process video for analysis and summarization — useful for code review of recorded demos or bug reports.
DeepSeek V4 Pro — Depth for Pennies
- Algorithm champion. 93.5% LiveCodeBench, 3206 Codeforces. For algorithm implementation, competitive programming, graph problems, dynamic programming — DeepSeek is the best model available at any price.
- 10× cheaper. $0.87 vs $9.00 per 1M output. A full-codebase analysis costs $0.87 instead of $9.00. Across a team running dozens of analyses daily, the savings are transformative.
- MIT license = self-hosting. Deploy on your GPUs. Fine-tune on your codebase. Never send code to a third party. For regulated industries, this is the only option. Flash requires Google's cloud.
- CSA+HCA attention at 1M tokens. Codebase-scale reasoning without budget anxiety. The efficient attention mechanism makes 1M-token context practical, not just advertised.
When to Use Which
| Scenario | Use | Why |
|---|---|---|
| Autonomous agent loops | Gemini 3.5 Flash | 76.2% Terminal-Bench. 4× speed. |
| Google Cloud / Antigravity native | Gemini 3.5 Flash | Infrastructure integration. Enterprise SLA. |
| Latency-sensitive IDE copilot | Gemini 3.5 Flash | 4× faster. Near-instant. |
| Algorithm implementation | DeepSeek V4 Pro | 93.5% LiveCodeBench. Best at any price. |
| High-volume code generation | DeepSeek V4 Pro | $0.87 vs $9.00. 10× cheaper. |
| Self-hosted / data sovereignty | DeepSeek V4 Pro | MIT license. Runs on your hardware. |
Bottom line: These models are complements. Flash for speed-critical agent loops, Google-native infrastructure, and latency-sensitive UX. DeepSeek for algorithmic depth, cost-sensitive volume, and self-hosted sovereignty. At 10× price difference, you can afford to use both.
20+ LLMs available. Side-by-side testing.
Sources: LLM Stats — Gemini 3.5 Flash | Google — Gemini 3.5 Launch | Google Cloud — I/O 2026 | DeepSeek V4 Pro Model Card | MorphLLM — DeepSeek V4.