
Two Chinese open-weight models. Two very different philosophies. GLM-5.2 is Z.ai's MIT-licensed text-only powerhouse — 62.1% SWE-bench Pro, 81.0% Terminal-Bench 2.1, Anthropic API compatible. MiniMax M3 is the world's first open-weight model to combine frontier coding with native video, image, and desktop computer operation — 59.0% Pro, 66.0% TB 2.1, 83.5% BrowseComp. GLM leads every shared benchmark by 3-15 points. But M3 is 3.7× cheaper, natively multimodal, and capable of 24-hour autonomous kernel optimization. Which open-weight model deserves your API key? Full comparison backed by VentureBeat, Lushbinary, and community testing. Both available on CodingFleet.
TL;DR — Key Findings
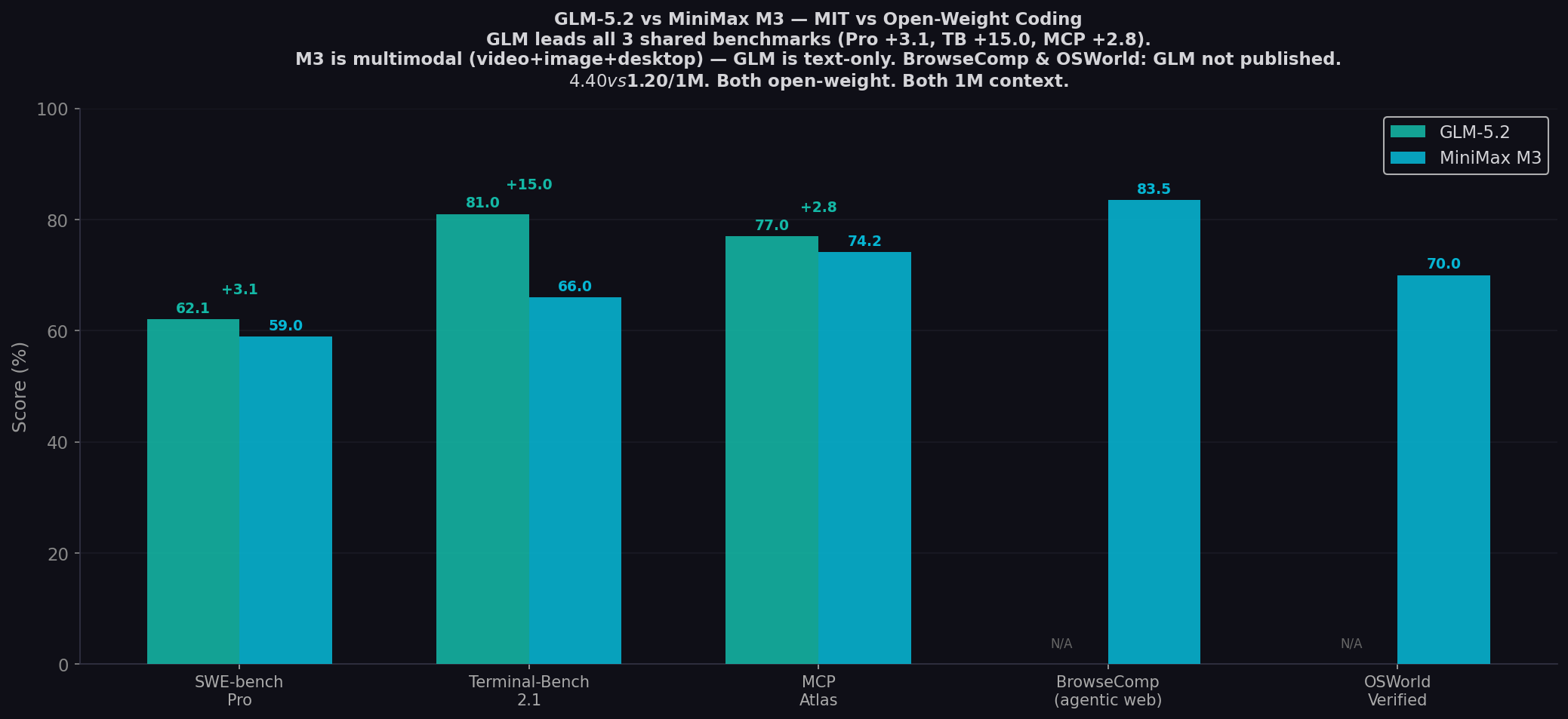
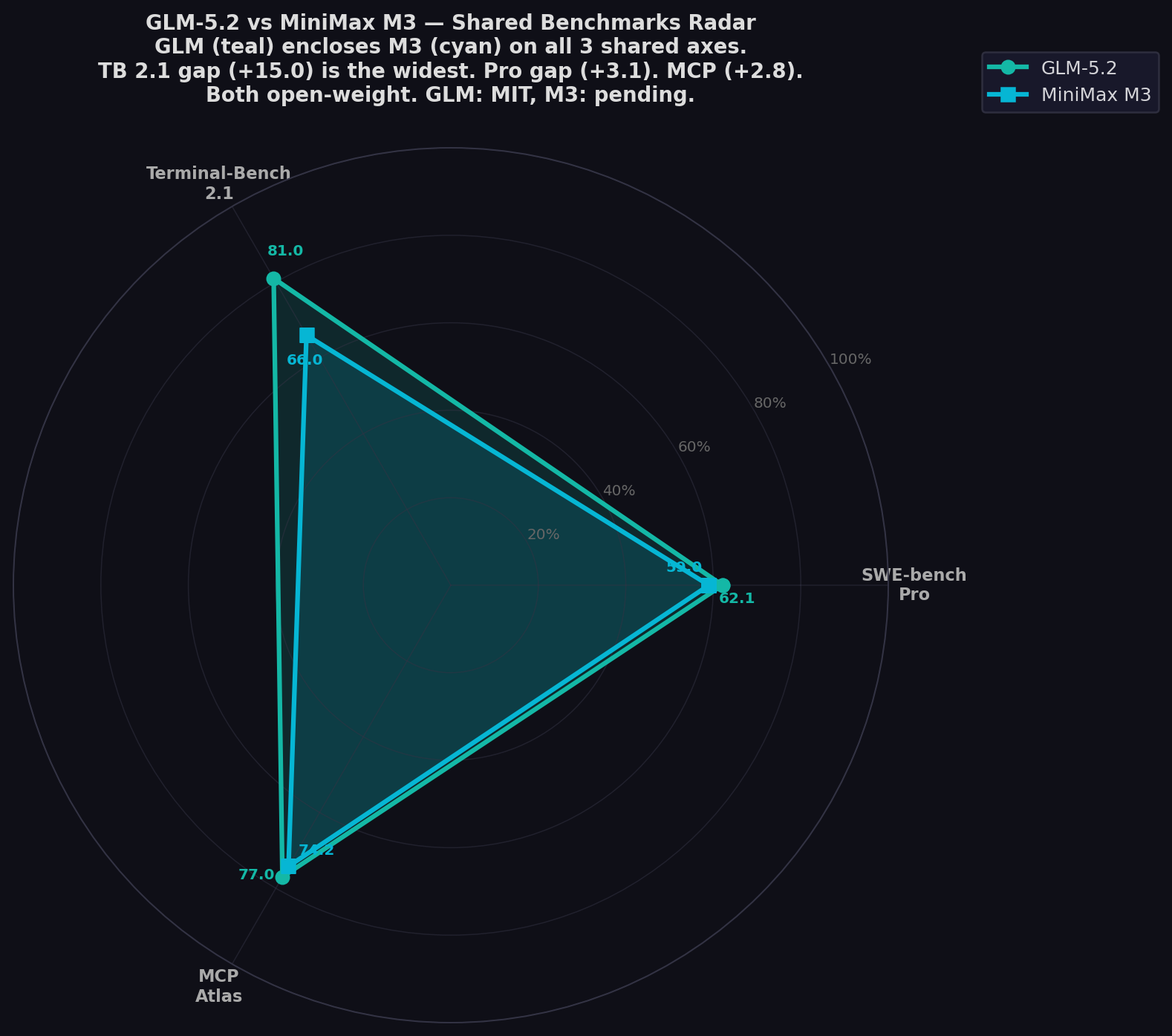
- GLM-5.2 leads all 3 shared benchmarks: Pro (+3.1), TB 2.1 (+15.0 — widest gap), MCP Atlas (+2.8).
- M3 is 3.7× cheaper: $1.20/1M output (promo) vs GLM's $4.40. At 100M output: M3 $120 vs GLM $440.
- M3 is natively multimodal: Video, image, and desktop computer operation. GLM is text-only.
- GLM has full MIT license: Weights already on HuggingFace. M3 weights promised "within 10 days" of June 1 launch (still pending).
- M3 leads BrowseComp (83.5%) and OSWorld (70.0%): GLM hasn't published scores on either — web browsing and GUI tasks favor M3.
- Both have 1M context: GLM uses full attention. M3 uses MSA (MiniMax Sparse Attention) — 9.7× prefill, 15.6× decode speedup.
Try both models on CodingFleet
Benchmark Comparison
| Benchmark | GLM-5.2 | MiniMax M3 | Winner |
|---|---|---|---|
| SWE-bench Pro ★ | 62.1% | 59.0% | GLM (+3.1) |
| Terminal-Bench 2.1 | 81.0% | 66.0% | GLM (+15.0) |
| MCP Atlas | 77.0% | 74.2% | GLM (+2.8) |
| HLE (with tools) | 54.7% | — (not published) | GLM |
| FrontierSWE | 74.4% | — (not published) | GLM |
| BrowseComp | — (not published) | 83.5% | M3 |
| OSWorld-Verified | — (not published) | 70.0% | M3 |
| SVG-Bench | — | Surpasses Opus 4.7 | M3 |
| Output Price /1M tok | $4.40 | $1.20 (promo) | M3 (3.7× cheaper) |
| Input Price /1M tok | $1.40 | $0.30 (promo) | M3 (4.7× cheaper) |
Sources: GLM-5.2 scores from Z.AI cross-model table via VentureBeat | MiniMax M3 from Lushbinary & VentureBeat M3 analysis. All scores vendor-reported. M3 weights still pending as of June 17.
Terminal-Bench: The 15-Point CLI Chasm
The defining gap. GLM-5.2 at 81.0% vs MiniMax M3 at 66.0% on Terminal-Bench 2.1 — the benchmark for real command-line agentic tasks. A 15-point gap is not marginal. It's the difference between a model that can reliably automate package management, build systems, git workflows, and server configuration versus one that needs human babysitting. VentureBeat noted M3's TB 2.1 score "runs neck-and-neck with the previous-generation Opus 4.7 baseline of 66.1%." GLM-5.2 at 81.0% is playing in a different league — it's competitive with GPT-5.5 (84.0%) and Opus 4.8 (85.0%). For CLI-first developers, GLM is the clear winner.
SWE-bench Pro: 3.1 Points — Real, Not Decisive
GLM at 62.1% vs M3 at 59.0%. Both models beat GPT-5.5 (58.6%). The 3.1-point gap is real — GLM is the stronger coder on multi-file GitHub issue resolution. But the margin is within harness variation. Both are frontier-class. Both are open-weight. The 3.7× price gap may matter more than 3.1 benchmark points for teams routing volume coding tasks.
BrowseComp: M3's Multimodal Advantage
MiniMax M3 at 83.5% on BrowseComp — surpassing Claude Opus 4.7 (79.3%) and competitive with GPT-5.5 (84.4%) on autonomous web browsing. GLM hasn't published a BrowseComp score. For web-connected agentic workflows — search, navigate, synthesize — M3 has a published capability that GLM can't claim. Combined with native video/image input and desktop computer operation, M3 is the more versatile model for real-world agentic work.
Architecture & Ecosystem
| Feature | GLM-5.2 | MiniMax M3 |
|---|---|---|
| Release Date | June 13, 2026 | June 1, 2026 |
| Developer | Z.ai (Beijing) | MiniMax |
| Context Window | 1,000,000 tokens | 1,000,000 tokens |
| Attention | Full Attention | MSA (9.7× prefill, 15.6× decode at 1M) |
| Modalities | Text only | Text, Image, Video, Desktop |
| License | MIT (weights live) | Open-weight* (weights pending) |
| API Compat | Anthropic API (Claude Code native) | MiniMax Code, REST API |
| Max Output | 131,072 tokens | Not disclosed |
| Thinking Modes | High, Max | Standard only |
| Best at | CLI agents, long-horizon SWE, reasoning | Multimodal coding, web browsing, desktop ops |
Why GLM-5.2 Wins: Pure Coding Power
GLM-5.2 leads every shared benchmark — often by significant margins. The 81.0% Terminal-Bench score puts it in the same tier as GPT-5.5 and Claude Opus 4.8. FrontierSWE at 74.4% (0.7 pts behind Opus). HLE w/tools at 54.7%. Full MIT license with weights already on HuggingFace. Native Claude Code compatibility — swap the base URL and you're running. For teams where raw coding and CLI performance matter most, GLM-5.2 is the strongest open-weight model available.
Why MiniMax M3 Wins: Multimodal Versatility
MiniMax M3 is the broader model — native video input, image understanding, desktop computer operation, and BrowseComp at 83.5%. The MSA sparse attention architecture makes 1M-context processing dramatically cheaper (15.6× decode speedup). At $1.20/1M output, it's 3.7× cheaper than GLM-5.2. And the 24-hour autonomous kernel optimization demo — 147 benchmark submissions, 1,959 tool calls, zero human intervention, improving Hopper FP8 utilization from 7.6% to 71.3% — demonstrates real-world long-horizon capability that benchmarks don't fully capture. Independent testing by Ivan Fioravanti ranked GLM-5.2 #1 in a Lunar Lander coding contest, with MiniMax M3 #2 and Kimi K2.7 #3 — confirming the benchmark hierarchy in practice.
Which Model Should You Use?
| Use Case | Winner | Why |
|---|---|---|
| CLI / terminal agents | GLM ✅ | +15.0 TB 2.1. Different league for CLI work |
| Multi-file bug fixing | GLM ✅ | +3.1 Pro. Better at real GitHub issues |
| Deep reasoning / HLE | GLM ✅ | 54.7% HLE w/tools. M3 not published |
| Web browsing agents | M3 ✅ | 83.5% BrowseComp. GLM not published |
| Video/image coding | M3 ✅ | Native multimodal input. GLM is text-only |
| Desktop automation | M3 ✅ | 70.0% OSWorld. GLM not published |
| Budget / high-volume | M3 ✅ | 3.7× cheaper. $120 vs $440 at 100M output |
| Claude Code drop-in | GLM ✅ | Anthropic API native. Zero config switch |
Conclusion: The Coder vs The Multitool
GLM-5.2 is the better coding model — it leads every shared benchmark, dominates Terminal-Bench, and pushes into Opus 4.8 territory on FrontierSWE. With a full MIT license and Claude Code compatibility, it's the strongest open-weight coding model in existence. Pick GLM-5.2 when raw coding power, CLI performance, and deployment freedom are your priorities.
MiniMax M3 is the more versatile model — native video, image, desktop computer operation, BrowseComp at 83.5%, and 3.7× cheaper. It sacrifices raw benchmark performance for capability breadth. Pick M3 when your agents need to see, browse, and operate — not just write code.
Sources & Links
- VentureBeat — GLM-5.2 beats GPT-5.5
- VentureBeat — MiniMax M3 analysis
- Lushbinary — MiniMax M3 developer guide
- MiniMax — M3 launch blog
- Kilo Code — best open-source coding models 2026
- Ivan Fioravanti — GLM-5.2 vs M3 vs Kimi K2.7 Lunar Lander test
Read This Next
- GLM-5.2 vs GPT-5.5 — MIT open-weight beats OpenAI on Pro
- Claude Opus 4.8 vs GLM-5.2 — 0.7 pts from the king
- SWE-bench Pro Leaderboard