
Two Chinese open-weight models. Two radically different philosophies. Kimi K2.6: 1 trillion parameters, 32 billion active, the #1 open-weight model on Artificial Analysis' Intelligence Index. MiniMax M2.7: 229 billion total, just 10 billion active — 4.3% of its parameters fire per token. One is a supercar. The other is a motorcycle that somehow keeps up. The SWE-bench Pro gap — 58.6% vs 56.22% — is just 2.38 points. But MiniMax achieves that at 70% lower cost per output token. This isn't just another model comparison. It's a referendum on whether raw parameters still matter in 2026.
📊 Key Findings
- Kimi K2.6 wins on raw performance. Leads on SWE-bench Pro (+2.38), Terminal-Bench (+9.7), HLE with tools (+18.8), Toolathon (+3.7), and AA Intelligence Index (+4 points).
- MiniMax M2.7 wins on cost-efficiency — decisively. 3.3× cheaper output ($1.20 vs $4.00), 3.2× cheaper input ($0.30 vs $0.95). Only 10B active parameters vs 32B.
- MiniMax has the most extreme MoE sparsity of any frontier model. 4.3% activation rate — 229B total, 256 experts, only 8 fire per token. This is how it achieves 94% of Kimi's coding score at a third of the cost.
- Kimi K2.6 has vision; MiniMax doesn't. Image input is built into Kimi. For UI-to-code, design-to-implementation, or screenshot debugging, Kimi is the only choice between the two.
- Kimi sustained 4,000+ tool calls over 13 hours. Published benchmark shows uninterrupted agentic operation. MiniMax hasn't published comparable long-horizon stability data.
- MiniMax has a unique "self-evolving" capability. M2.7 can build its own agent harnesses for complex tasks. It scored 55.6% on VIBE-Pro (end-to-end project delivery) — a benchmark Kimi hasn't been tested on.
Both models are available on CodingFleet. Test them side-by-side →
Two Philosophies: Parameter Rich vs Compute Efficient
Kimi K2.6 and MiniMax M2.7 represent opposite bets about the future of AI:
| Design Philosophy | Kimi K2.6 | MiniMax M2.7 |
|---|---|---|
| Total Parameters | 1T | 229B |
| Active Parameters | 32B | 10B |
| Activation Rate | 3.2% | 4.3% |
| MoE Experts | Not disclosed | 256 (8 active/token) |
| Layers | Not disclosed | 62 |
| Training Data | Not disclosed | Not disclosed |
| AA Intelligence Index | 54 (#1 open-weight) | 50 |
| Inference Cost (AA Index) | ~$371 | ~$176 |
| Output Tokens (AA Index) | ~89M | ~87M (more efficient) |
MiniMax M2.7 cost $176 to run the entire Artificial Analysis Intelligence Index — less than half of GLM-5 ($547) and less than Kimi K2.5 ($371). It used 87M output tokens vs Kimi K2.5's 89M at equivalent intelligence. This is the efficiency story in a single data point: fewer parameters, less cost, same intelligence.
Head-to-Head: Every Benchmark
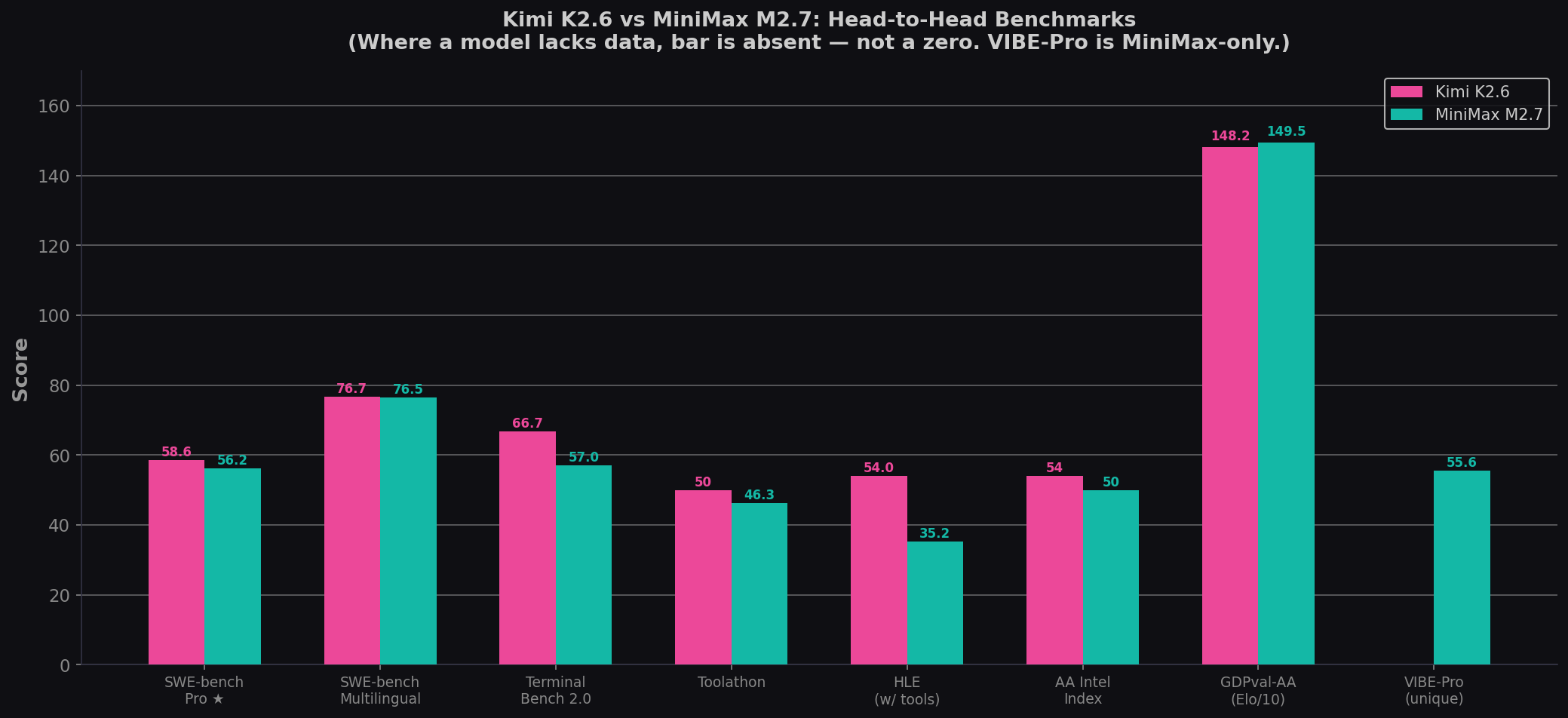
| Benchmark | Kimi K2.6 | MiniMax M2.7 | Winner | Gap |
|---|---|---|---|---|
| SWE-bench Pro ★ | 58.6% | 56.22% | Kimi | +2.38 |
| SWE-bench Multilingual | 76.7% | 76.5% | Kimi | +0.2 |
| Multi-SWE-Bench | — | 52.7% | MiniMax | Unique |
| Terminal-Bench 2.0 | 66.7% | 57.0% | Kimi | +9.7 |
| Toolathon | 50.0% | 46.3% | Kimi | +3.7 |
| HLE (w/ tools) | 54.0% | 35.2% | Kimi | +18.8 |
| VIBE-Pro | — | 55.6% | MiniMax | Unique |
| AA Intelligence Index | 54 | 50 | Kimi | +4 |
| GDPval-AA (Elo) | 1482 | 1495 | MiniMax | +13 |
| AIME 2026 | 96.4% | — | Kimi | Not tested |
| LiveCodeBench v6 | 89.6% | — | Kimi | Not tested |
| SciCode | 52.2% | — | Kimi | Not tested |
Sources: Kimi K2.6 tech blog; MiniMax M2 GitHub; OpenRouter MiniMax M2.7; Artificial Analysis M2.7 analysis; Atlas Cloud comparison.
Kimi K2.6 leads on 8 of 10 comparable benchmarks. The two MiniMax wins are GDPval-AA (+13 Elo, essentially tied) and two unique benchmarks (Multi-SWE-Bench, VIBE-Pro) that Kimi hasn't published. The biggest gaps: Terminal-Bench (+9.7 — Kimi's CLI automation is significantly better) and HLE with tools (+18.8 — Kimi's academic reasoning is in a different tier).
The Efficiency Paradox: How 10B Params Matches 32B
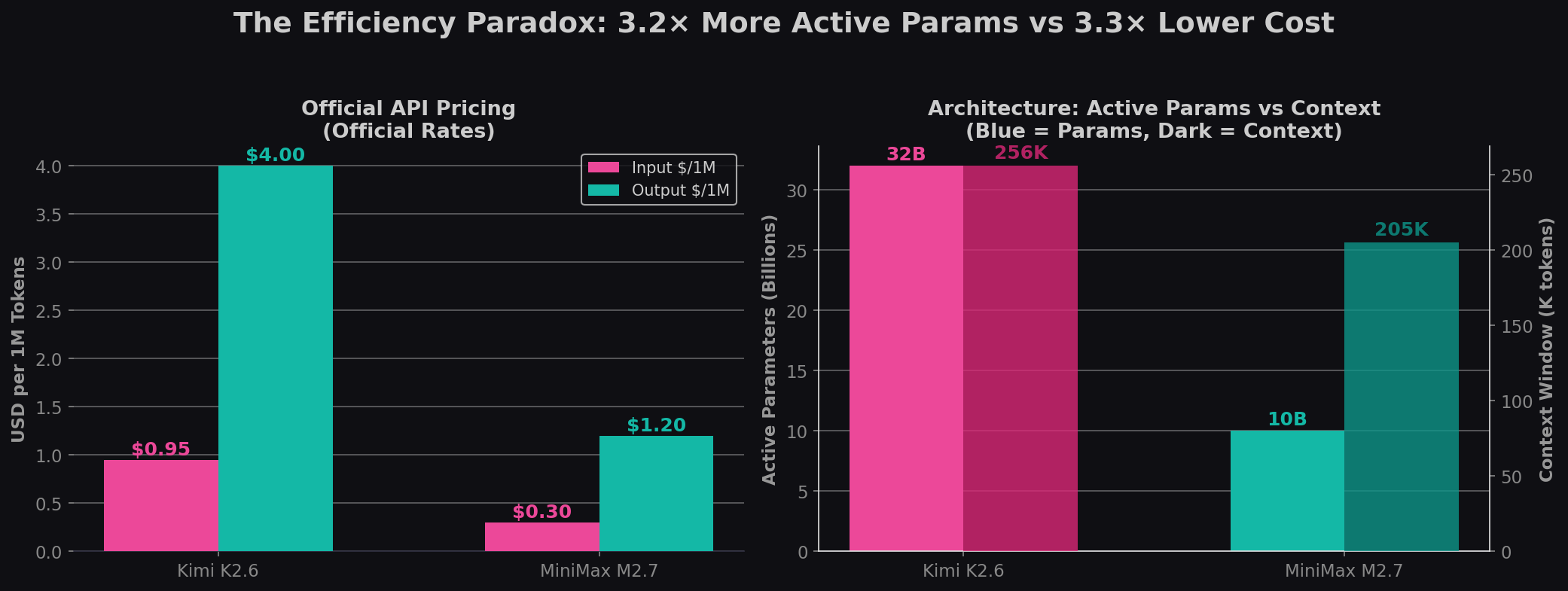
MiniMax M2.7 achieves 94% of Kimi K2.6's SWE-bench Pro score with 69% fewer active parameters (10B vs 32B) and 70% lower output cost ($1.20 vs $4.00). This is the most extreme efficiency ratio of any frontier model pair in 2026.
The secret is MiniMax's MoE architecture: 256 specialized experts, only 8 activated per token. Each expert specializes in a narrow domain — one for Python syntax, another for Django patterns, a third for algorithmic logic — and the router picks the right combination for each token. The result is near-frontier coding performance without the compute cost of running 32B parameters.
As Artificial Analysis noted: "MiniMax-M2.7 scores 50 on the Intelligence Index... equivalent to GLM-5 (Reasoning, 50) while using 20% fewer output tokens and costing less than a third as much to run." Kimi K2.6 at 54 is 4 points higher — but costs proportionally more.
Why Kimi K2.6 Wins on Performance
🏆 Where Kimi K2.6 Is Decisively Better
- Terminal/CLI automation: 66.7% vs 57.0% — a 9.7-point lead. If your coding workflow involves build systems, package management, or DevOps, Kimi is significantly stronger.
- Academic/HLE reasoning: 54.0% vs 35.2% — an 18.8-point chasm. For research coding, algorithm design, or complex problem-solving, Kimi is in a different tier.
- Vision/image input: Kimi has it. MiniMax doesn't. UI-to-code, screenshot debugging, design file interpretation — only Kimi handles these.
- Long-horizon agent stability: Kimi sustained 4,000+ tool calls over 13 hours in published benchmarks — the highest stability ceiling of any open-weight model. If you're building autonomous coding agents that run overnight, this is the most important metric in the comparison.
- Agent Swarm: Native parallel sub-agent orchestration (up to 100 agents). For distributed codebase tasks — monorepo migrations, cross-service refactoring — Kimi can parallelize natively.
- Benchmark completeness: Kimi has published scores on 13+ benchmarks. MiniMax has published on ~8. Kimi is more thoroughly evaluated, which means fewer unknown risks.
Why MiniMax M2.7 Is the Efficiency Champion
💎 Where MiniMax M2.7 Punches Above Its Weight
- Cost per coding point: MiniMax delivers a SWE-bench Pro point for $0.021 (output cost ÷ score). Kimi: $0.068. MiniMax is 3.2× more cost-efficient per unit of coding capability.
- Real-world agentic work: GDPval-AA 1495 Elo (edges Kimi at 1482). For actual professional tasks — not coding benchmarks but real job simulations — MiniMax is competitive or better.
- VIBE-Pro 55.6%: End-to-end project delivery — generating complete repositories from specifications. A unique benchmark Kimi hasn't tested. MiniMax was built for autonomous productivity workflows, not just code generation.
- Self-evolving capability: MiniMax M2.7 can build its own agent harnesses to accomplish complex tasks. This "meta-agent" capability — the model improving its own tooling — is unique among open-weight models.
- Hallucination rate: OpenCode developers report MiniMax M2.7 has a "fairly low hallucination rate" in real-world use. The M2.5 predecessor scored 9.1% on Vectara HHEM — competitive with GPT-5.5 (9.3%).
- Real-world coding gap is smaller than benchmarks suggest: Kilo Blog ran both through 3 real coding tasks. M2.7 scored 86/100 vs Claude Opus at 91/100 — a 5-point real-world gap. Benchmarks overstate the difference.
Real-World Developer Experience
OpenCode CLI developers on Reddit have tested both models extensively. The consensus: Kimi K2.6 is "around Sonnet level capability" — the highest praise an open-weight model has received. One developer reported "shockingly well" results after implementing a custom plugin. MiniMax M2.7 was described as "feels fine in use, no real complaints, but doesn't score super well in the eval."
Atlas Cloud's practical recommendation: "If you are building an autonomous coding agent that runs for hours without intervention: Kimi K2.6. If cost per token is the constraint: MiniMax M2.7 at $0.30/M input scores 56.22% on SWE-Bench Pro with only 10B activated parameters — 94% of GLM-5.1's performance at roughly one-fifth the cost."
Which One Should You Use?
| Use Case | Winner | Why |
|---|---|---|
| Maximum coding performance | Kimi K2.6 | Leads 8/10 comparable benchmarks; +2.38 SWE-bench Pro |
| Cost-sensitive production at scale | MiniMax M2.7 | $0.021 per SWE-bench Pro point — 3.2× cheaper than Kimi |
| Terminal/CLI/DevOps automation | Kimi K2.6 | +9.7 Terminal-Bench — significant automation gap |
| UI-to-code / design-to-implementation | Kimi K2.6 | Only model with vision/image input support |
| Long-horizon autonomous agents | Kimi K2.6 | 4,000+ tool calls over 13 hours — proven stability |
| Budget batch processing / high volume | MiniMax M2.7 | $0.30/$1.20 per 1M — 3.3× cheaper than Kimi |
| Self-hosted / local deployment | MiniMax M2.7 | 10B active params fits on consumer GPUs; 229B total needs ~4× A100 |
| Research / HLE-level problem solving | Kimi K2.6 | +18.8 HLE with tools — different reasoning tier |
| End-to-end project generation | MiniMax M2.7 | 55.6% VIBE-Pro — unique autonomous project delivery |
The Bottom Line
- Kimi K2.6 is the better model — on benchmarks and in real-world use. It leads on 8/10 comparable metrics, has vision, has published 13+ benchmarks, and sustains the longest autonomous coding sessions of any open-weight model. If you want the best open-weight coding model available today, Kimi K2.6 is still the answer.
- MiniMax M2.7 is the efficiency miracle. 10B active parameters achieving 94% of Kimi's coding score at 30% of the cost is an architectural achievement. For budget-constrained teams, high-volume pipelines, or anyone optimizing for cost-per-coding-point, MiniMax is the smarter economic choice.
- Parameter count is losing relevance. The 32B vs 10B active parameter gap should produce a much larger performance difference than 2.38 SWE-bench Pro points. MiniMax's extreme MoE sparsity (4.3% activation, 256 experts) proves that architecture matters more than raw scale in 2026.
- The right answer depends on your bottleneck. If your bottleneck is model intelligence (hard bugs, complex reasoning) → Kimi. If your bottleneck is budget (high volume, cost constraints) → MiniMax. If your bottleneck is agent stability (long-running autonomous tasks) → Kimi. If your bottleneck is GPU memory (local deployment) → MiniMax.
This comparison isn't about which model is "better." It's about which bet on the future of AI you're making: more parameters (Kimi) or smarter architecture (MiniMax). Both are winning bets. They just win differently.
Sources: Kimi K2.6 Tech Blog (official benchmark table) | MiniMax M2 GitHub (M2.7 benchmarks) | Artificial Analysis — M2.7 Analysis (Intelligence Index: 50, cost: $176) | OpenRouter — MiniMax M2.7 | Atlas Cloud — 4-Model Coding Comparison | Shareuhack — M2.7 Architecture Deep-Dive | DocsBot — Kimi vs MiniMax | Reddit r/opencodeCLI (developer experiences). All benchmark scores vendor-reported unless noted. AA Intelligence Index from Artificial Analysis independent evaluation.