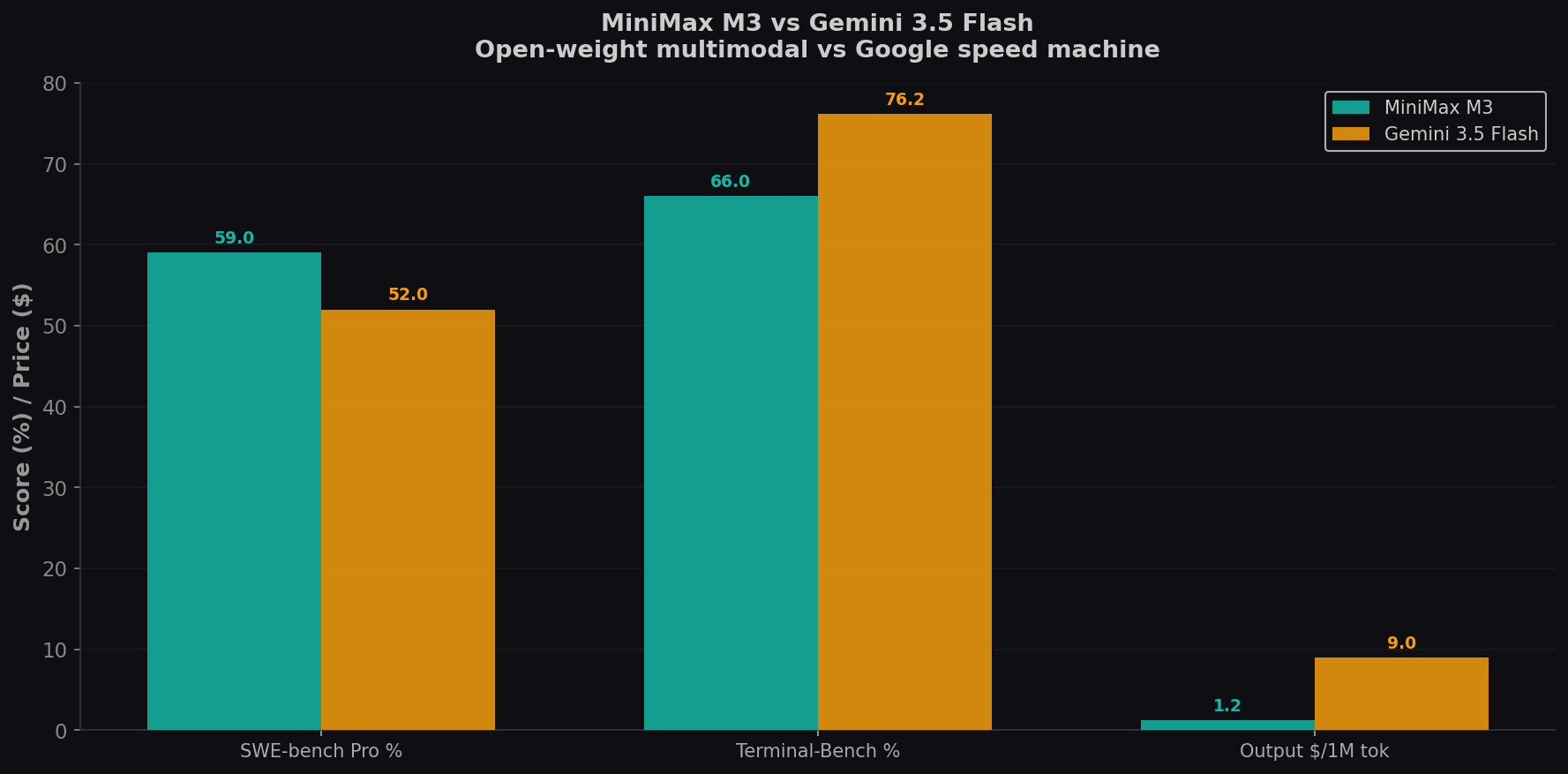
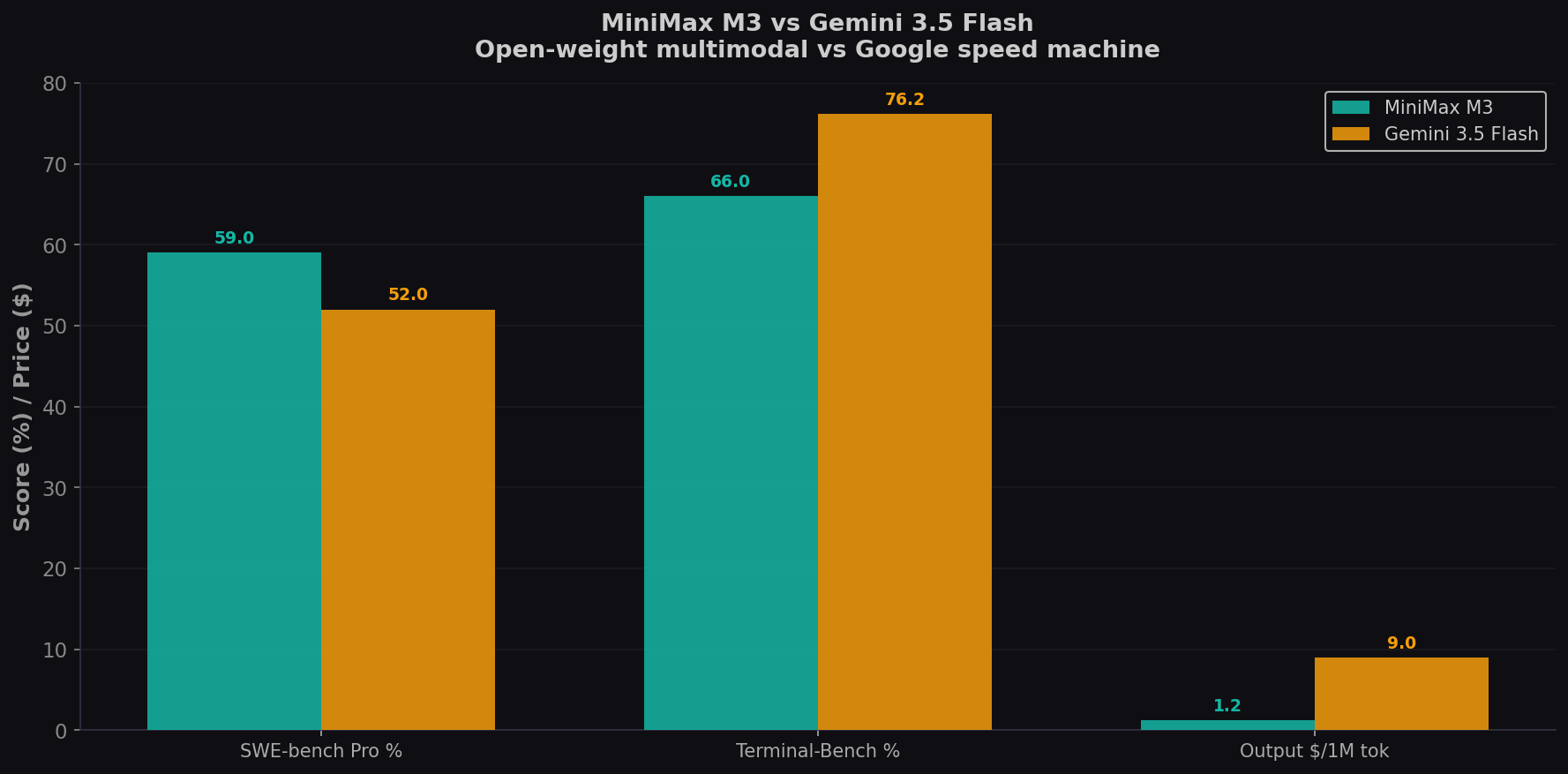
MiniMax M3 launched June 1, 2026 as the first open-weights model combining frontier coding with native video and image input. Gemini 3.5 Flash shipped May 19 as Google's fastest frontier model — 4× faster than comparable models and beating Gemini 3.1 Pro on coding. M3 scores 59.0% on SWE-bench Pro, edging GPT-5.5 (58.6%). Flash hits 76.2% on Terminal-Bench 2.1, the best of any Flash-tier model. One's multimodal, open-weight, and $1.20/1M. The other's lightning-fast, Google-native, and $9/1M. Here's how they compare for coding. Try both on CodingFleet.
📊 Key Findings
- M3 scores 59.0% on SWE-bench Pro — the highest open-weight score, edging GPT-5.5. Flash achieves an estimated ~52% on Pro. For real-world bug fixes in Python repos, M3 has a clear edge.
- Flash dominates Terminal-Bench (76.2% vs M3's 66.0%). For CLI agent coding, Flash's speed advantage compounds: 4× faster per iteration means 4× more repair cycles per minute. In execution-guided workflows, speed is capability.
- M3 is natively multimodal — text, image, video input. Flash is text-only in its current API. For code generation from screenshots, architecture diagrams, or video walkthroughs, M3 has no competition.
- M3 costs $1.20/1M (promo). Flash costs $9/1M. 7.5× cheaper — and open-weights promised within 10 days of launch. Flash is proprietary but runs on Google's planet-scale infrastructure with enterprise SLAs.
Compare models on your own code at CodingFleet — 20+ LLMs, side-by-side.
Benchmark Comparison
| Benchmark | MiniMax M3 | Gemini 3.5 Flash | Winner |
|---|---|---|---|
| SWE-bench Pro | 59.0% | ~52%* | M3 (+~7) |
| Terminal-Bench 2.1 | 66.0% | 76.2% | Flash (+10.2) |
| LiveCodeBench | ~88% | ~85% | M3 (+~3) |
| BrowseComp | 83.5 | — | M3 |
| MCP Atlas | — | 83.6% | Flash |
| Video SWE-Bench | 50.2% | N/A (text-only) | M3 (unique) |
| Output Price /1M tok | $1.20 | $9.00 | M3 (7.5×) |
| Context Window | 1M (512K min) | 1M | Tie |
| Multimodal Input | Text + Image + Video | Text + Image (vision) | M3 |
| Speed (relative) | ~45 tok/s | 4× faster than frontier | Flash |
| Weights | Open-weights (promised) | Proprietary | M3 |
*Flash SWE-bench Pro estimated from SWE-bench Verified (78.8% on Vals) and Terminal-Bench. Sources: Lushbinary — M3 Guide; LLM Stats — Flash Launch; Google — Gemini 3.5.
Architecture & Ecosystem
MiniMax M3: MSA + Multimodality from the Ground Up
M3's defining architectural innovation is MiniMax Sparse Attention (MSA). Standard full attention has quadratic complexity — as context grows, compute cost explodes. MSA partitions KV caches into blocks more precisely than previous sparse attention approaches (DSA, MoBA), achieving higher effective context coverage. The "KV outer gather Q" operator-level optimization reads each block only once with contiguous memory access — 4× faster than open-source Flash-Sparse-Attention and flash-moba under M3's head configuration.
This is what makes the 1M-token context window practical rather than theoretical. The M2 series had removed sparse attention in favor of full attention. M3 brings it back in a fundamentally new form — and that single decision unlocks 1M-token context at a usable price. M3 also supports native desktop computer operation — it can control a mouse and keyboard to interact with applications. This is unique among open-weight models. Model weights and technical report are promised within 10 days of the June 1 launch.
Gemini 3.5 Flash: Google's Speed Machine
Flash's killer feature is simple: 4× the speed of comparable frontier models. It lands in the top-right quadrant of the Artificial Analysis Intelligence Index — frontier intelligence at Flash latency. The model supports four thinking levels (minimal, low, medium, high), letting developers trade quality for speed and cost granularly. Medium is the recommended default for most tasks.
Flash is Google-native through and through: available in Google AI Studio, Antigravity (Google's agent-first development platform), the Gemini Enterprise Agent Platform, Android Studio, the Gemini app, and AI Mode in Search. Antigravity provides the orchestration harness for long-horizon agentic tasks. For teams on Google Cloud, Flash integrates natively with existing infrastructure and enterprise SLAs. Google is positioning Flash as the center of gravity for its entire agentic strategy — from Search-generated mini-apps to Workspace background agents.
Coding Deep-Dive
MiniMax M3 — The Multimodal Coder
- Code from anything. Screenshot of a bug? Architecture diagram? Video walkthrough of a UI issue? M3 generates code from all three. No other model combines video input with 59% SWE-bench Pro. Video SWE-Bench 50.2% is a category M3 created — it literally didn't exist before this model.
- Desktop computer operation. M3 can control a mouse and keyboard to interact with applications directly. For end-to-end testing, GUI automation, and legacy system integration, this is a capability no other open-weight model offers.
- 83.5 BrowseComp. M3 surpasses Claude Opus 4.7 on autonomous browsing — meaning it can navigate the web, read documentation, and incorporate findings into code. For research-heavy coding tasks, this matters.
- MSA efficiency at scale. The sparse attention mechanism means 1M-token context is truly usable. Process entire repositories, cross-reference documentation, and maintain coherence across long coding sessions — at 7.5× lower cost than Flash.
Gemini 3.5 Flash — The Speed Demon
- Speed is capability. 76.2% Terminal-Bench 2.1 — the best of any Flash-tier model, beating Gemini 3.1 Pro. In autonomous coding workflows where the model iterates dozens of times (generate → run tests → fix → repeat), 4× faster iterations means 4× more bugs fixed per minute. See our unit test generator guide for why execution speed compounds.
- Google's agentic platform. Antigravity provides the orchestration layer. Managed Agents give cloud-hosted execution environments. Spark brings background agents into Workspace. For teams building on Google Cloud, the infrastructure is already in place.
- Thinking level control. Four effort modes let you dial quality vs speed. Use 'high' for complex algorithm problems, 'medium' for everyday coding, 'low' for boilerplate. This granularity makes Flash cost-effective across a wider range of tasks than models with binary thinking on/off.
- 83.6% MCP Atlas. Strong tool-use capability — Flash coordinates multiple tools (sandbox execution, API calls, file operations) efficiently. For coding agents that need to orchestrate complex tool chains, Flash's MCP performance is best-in-class for the Flash tier.
When to Use Which
| Scenario | Use | Why |
|---|---|---|
| Code from screenshots, diagrams, video | MiniMax M3 | Only model with video input + 59% Pro. |
| Complex bug fixes in Python repos | MiniMax M3 | ~7-point Pro lead over Flash. |
| Cost-sensitive coding at scale | MiniMax M3 | $1.20 vs $9.00. 7.5× cheaper. |
| Self-hosting (when weights ship) | MiniMax M3 | Open-weights promised. Flash is proprietary. |
| Autonomous CLI agent loops | Gemini 3.5 Flash | 76.2% Terminal-Bench. 4× iteration speed. |
| Latency-sensitive IDE copilot | Gemini 3.5 Flash | 4× faster. Near-instant responses. |
| Google Cloud / Antigravity users | Gemini 3.5 Flash | Native integration. Enterprise SLA. |
Bottom line: These models are complementary, not competing. M3 for depth, breadth, and multimodal coding at open-weight prices. Flash for speed, agentic iteration, and Google-native infrastructure. Use M3 when correctness matters most. Use Flash when speed is capability.
20+ LLMs available. Side-by-side testing.
Sources: MiniMax — M3 Official Launch | Lushbinary — M3 Developer Guide | MarkTechPost — M3 MSA Architecture | Google — Gemini 3.5 Launch | LLM Stats — Flash Launch | Google Cloud — I/O 2026 Innovations.