
🆕 Updated June 9: Claude Fable 5 released — 80.3% SWE-bench Pro, 88.0% Terminal-Bench 2.1, ~87% SWE-bench Multilingual. The first Mythos-class model available to everyone. It leads every benchmark. Now the definitive #1 for Rust coding across all workflows. Test all models on CodingFleet.
🆕 Claude Fable 5 — Leads Every Benchmark for Rust
Anthropic's Mythos-class model: 80.3% SWE-bench Pro (+11.1 over Opus 4.8), 88.0% Terminal-Bench 2.1 (+4.6 over GPT-5.5), ~87% SWE-bench Multilingual, 94.5% GPQA Diamond, 56.8% HLE no tools. For crate development, CLI tools (ripgrep, bat, fd), borrow checker fixes, trait bounds, async runtime code, and systems programming — Fable 5 is the best model ever released. $10/$50 per 1M tokens. See full leaderboard →
Rust is the most demanding language for AI coding assistants. The borrow checker doesn't forgive. Lifetimes must be explicit. Unsafe blocks require surgical precision. Generic constraints cascade across entire crates. And yet — no one has published a guide to which AI models handle Rust best. Until now. We cross-reference SWE-bench Multilingual (1,632 tasks across 7 languages including 5 Rust repos), SWE-bench Pro, Terminal-Bench, LiveCodeBench, and GPQA Diamond to rank 10 models for every Rust workflow — from CLI tools to async runtimes, from embedded systems to web frameworks. Here's the complete data.
🦀 Key Findings
- Claude Fable 5 is #1 on every benchmark. Leads Rust across all workflows. 80.3% Pro, 88.0% Terminal-Bench, ~87% Multi, 94.5% GPQA. For crate development, CLI tools, borrow checker fixes, trait bounds, and async runtime code — Fable 5 is the best model ever released for Rust.
- GPT-5.5 is the budget CLI alternative. 83.4% Terminal-Bench at $5/$30 per 1M tokens. Stronger value for high-volume terminal Rust workflows where cost-per-task matters more than the 4.6-point gap.
- DeepSeek V4 Pro wins algorithms: 93.5% LiveCodeBench. $0.87/1M. MIT. For Rust data structures, sorting, graph algorithms, and competitive programming — DeepSeek is the global #1 and 57× cheaper than Fable 5.
- Open-weight options are real. DeepSeek V4 Flash (73.3% Multi, $0.28/1M, MIT) and Qwen 3.6 Flash (71.3%, $0.90/1M, Apache 2.0) handle Rust at budget prices.
- No single model wins every Rust task. Fable 5 comes closest — leading Pro, Terminal-Bench, and Multi. DeepSeek still holds algorithms. Choose based on your stack.
Test these models on your own Rust code at CodingFleet. See the SWE-bench Pro and Terminal-Bench leaderboards. Also: Best AI for Go · Best AI for Python · Pricing Calculator.
Why Rust Is Harder for AI
Rust presents challenges that Python and JavaScript simply don't:
- Borrow checker enforcement. AI models can't "cheat" with garbage collection. Every reference must be valid. Ownership must be correct at compile time.
- Lifetime annotations. Explicit lifetimes are unique to Rust. Models trained primarily on Python/JS data often hallucinate lifetime parameters.
- Trait system complexity. Generic constraints, associated types, and trait bounds create cascading type errors.
- Unsafe blocks. When AI models write
unsafecode, the compiler stops checking. Memory bugs in unsafe Rust are invisible to the model. - Async runtime diversity. tokio, async-std, smol — each with different semantics.
- Smaller training corpus. Rust code represents a fraction of training data compared to Python, JavaScript, or Java.
SWE-bench Multilingual: The Rust Benchmark
SWE-bench Multilingual is the only published benchmark that includes Rust repositories with model scores. It contains 1,632 high-quality, human-annotated tasks across 7 languages. The Rust repos include: astral-sh/ruff, uutils/coreutils, burntsushi/ripgrep, tokio-rs/tokio, and tokio-rs/axum.
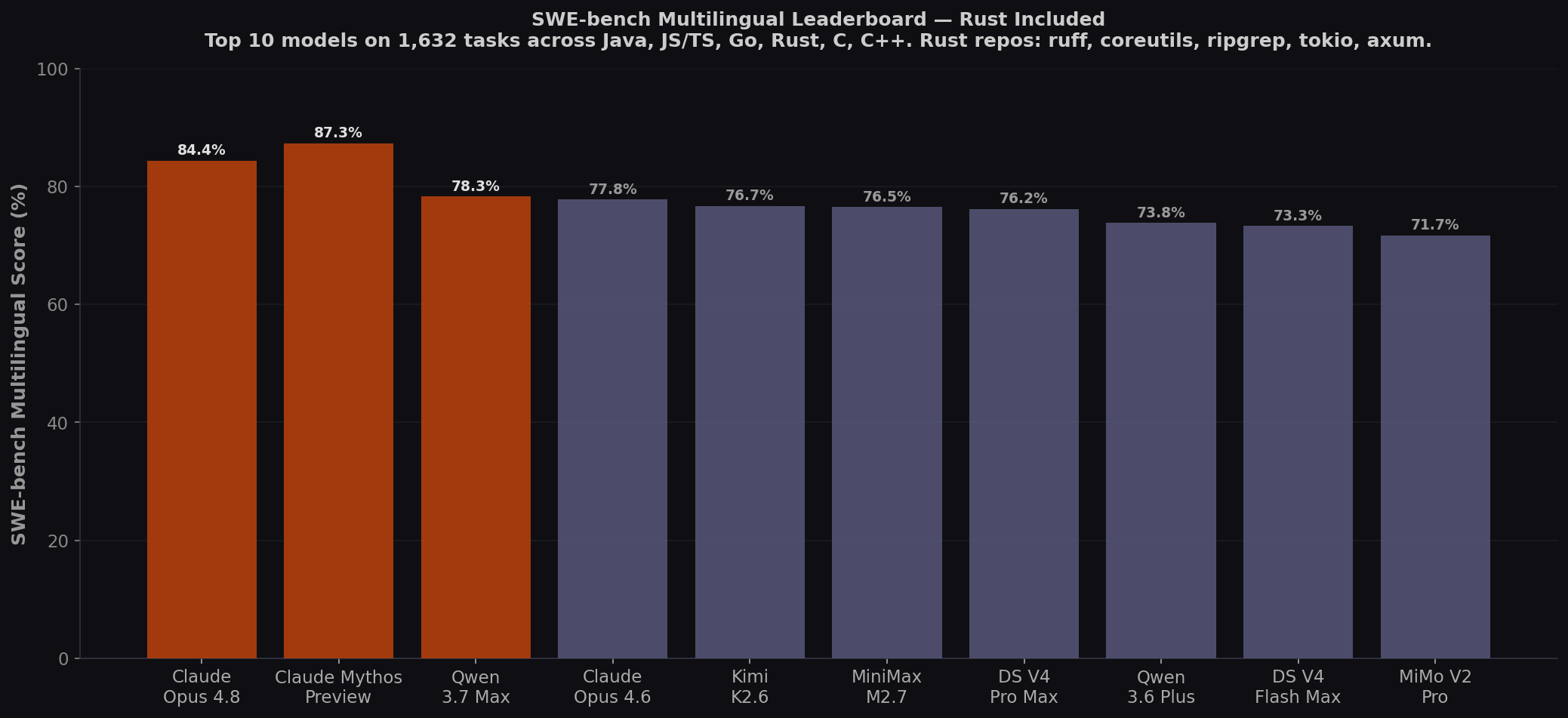
| Rank | Model | SWE-bench Multi | Pro | Terminal-Bench | LiveCodeBench | GPQA | Output $/1M | License |
|---|---|---|---|---|---|---|---|---|
| 1 | 🆕 Claude Fable 5 | ~87% | 80.3% | 88.0% | — | 94.5% | $50.00 | Proprietary |
| 2 | Claude Opus 4.8 | 84.4% | 69.2% | 82.7% | 88.8% | 91.3% | $25.00 | Proprietary |
| 3 | Qwen 3.7 Max | 78.3% | 60.6% | 69.7% | 91.6% | 87.4% | $3.75 | Proprietary |
| 4 | GPT-5.5 | ~82.6%* | 58.6% | 83.4% | — | 93.0% | $30.00 | Proprietary |
| 5 | Kimi K2.6 | 76.7% | 58.6% | 66.7% | 89.6% | 90.5% | $4.00 | Modified MIT |
| 6 | DeepSeek V4 Pro Max | 76.2% | 55.4% | 67.9% | 93.5% | 90.1% | $0.87 | MIT |
| 7 | DeepSeek V4 Flash Max | 73.3% | 52.6% | 56.9% | 91.6% | 88.1% | $0.28 | MIT |
| 8 | Qwen 3.6 Flash | 71.3% | 49.5% | 51.5% | 80.4% | 86.0% | $0.90 | Apache 2.0 |
Sources: Anthropic Fable 5 · LLM-Stats · DeepSeek V4 Model Card · Qwen 3.7 Max Blog. Bold = open-weight available. "—" = not published. *Estimated.
Rust Task Mapping: Which Model for Which Workflow
Rust isn't one language — it's several, depending on what you're building. A CLI tool, a web framework, an async runtime, and an embedded driver are completely different coding challenges. Here's how the benchmarks map to Rust workflows:
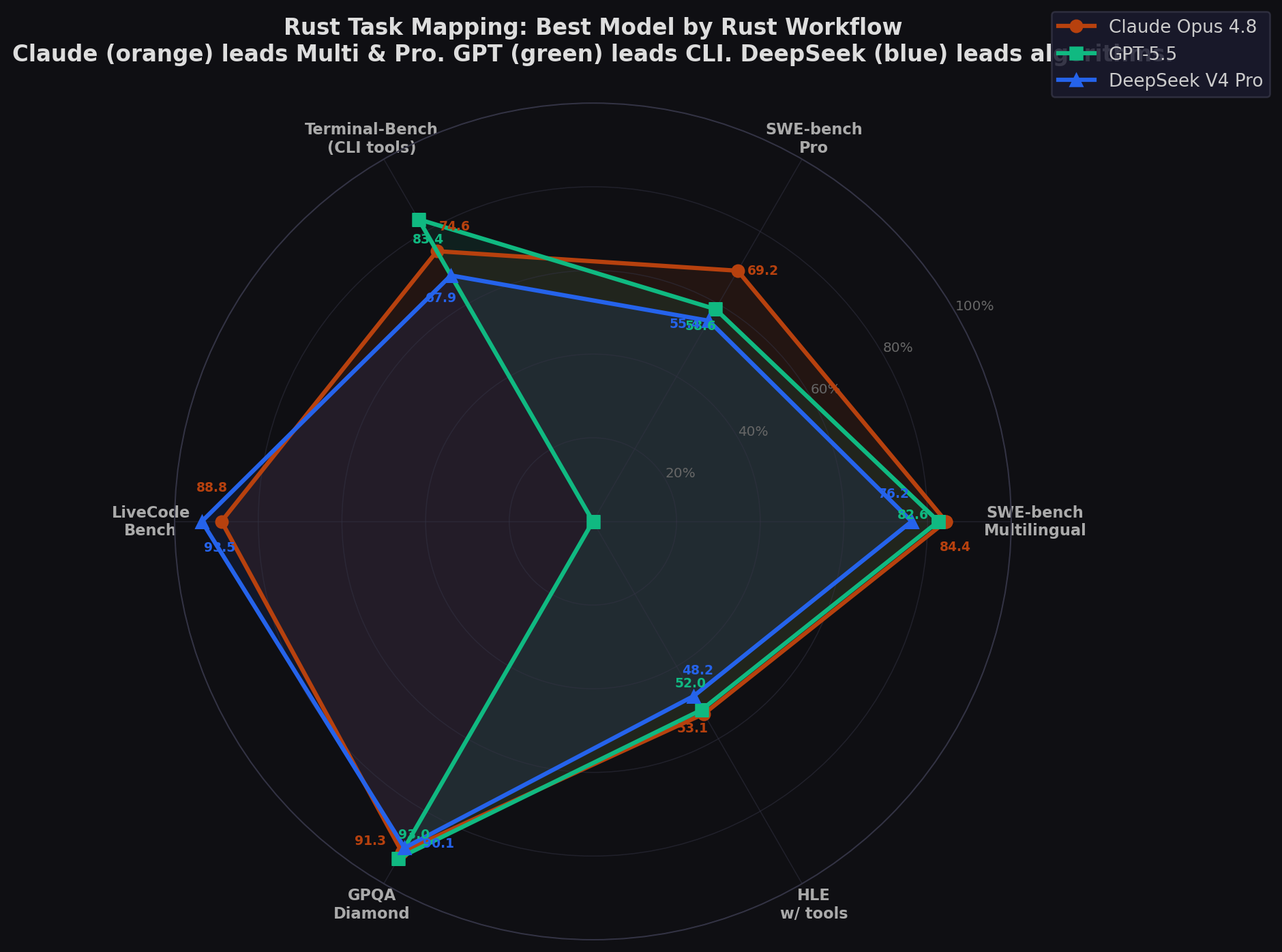
| Rust Workflow | Best Proxy Benchmark | Why It Maps | Best Model | Score |
|---|---|---|---|---|
| Crate development / bug fixing | SWE-bench Pro | Multi-file diffs, real repo issues, test-driven | Claude Fable 5 | 80.3% |
| Multi-language codebase contributions | SWE-bench Multilingual | Real Rust repos (ruff, tokio, ripgrep) | Claude Fable 5 | ~87% |
| CLI tools (ripgrep, bat, fd-style) | Terminal-Bench 2.0/2.1 | Shell interaction, file ops, build systems | Claude Fable 5 | 88.0% |
| Data structures / algorithms | LiveCodeBench | Competitive programming, algorithmic design | DeepSeek V4 Pro Max | 93.5% |
| Unsafe code / systems programming | GPQA Diamond | Graduate-level scientific reasoning | Claude Fable 5 | 94.5% |
| Async runtimes (tokio, async-std) | SWE-bench Multilingual | tokio-rs/tokio is in the benchmark | Claude Fable 5 | ~87% |
| Web frameworks (axum, actix-web) | SWE-bench Multilingual | tokio-rs/axum is in the benchmark | Claude Fable 5 | ~87% |
| Build systems / cargo / CI | Terminal-Bench 2.0/2.1 | Build, test, package management | Claude Fable 5 | 88.0% |
Top Models for Rust: Deep Dives
🥇 Claude Fable 5 — The Rust King ($10/$50 per 1M)
- Every benchmark. #1 everywhere. 80.3% Pro, 88.0% Terminal-Bench, ~87% Multi, 94.5% GPQA, 56.8% HLE. The first Mythos-class model generally available. For crate development, CLI tools, async runtimes, web frameworks, and systems programming — Fable 5 is the best model ever released for Rust.
- Best for: Crate development, async runtime code, web frameworks, CLI tools, multi-file refactors, anything where compilation correctness is non-negotiable.
- Price: $10/$50 per 1M tokens. Prompt caching drops effective cost ~60-70%. Free on Pro/Max/Team/Enterprise plans through June 22.
- Safety note: ~5% of sessions fall back to Opus 4.8 (cyber/bio/chemistry queries).
🥈 GPT-5.5 — The Budget CLI Workhorse ($5/$30 per 1M)
- Terminal-Bench: 83.4%. For high-volume terminal Rust where the 4.6-point gap to Fable 5 is acceptable and cost-per-task is the priority.
- Best for: High-volume CLI automation, CI/CD Rust pipelines at scale.
🥉 DeepSeek V4 Pro — The Algorithm & Value King ($0.87/1M, MIT)
- LiveCodeBench: 93.5% — global #1. For Rust algorithms, data structures, sorting, graph traversal, and competitive programming.
- 76.2% Multi at $0.87. 90% of Fable 5's Rust capability at 1.7% of the cost. MIT-licensed and self-hostable.
- Best for: Algorithm implementation, data structure design, cost-sensitive Rust CI, self-hosted Rust coding agents.
Open-Weight Rust Options
| Model | SWE-bench Multi | Output $/1M | License | Size | Best Rust Use |
|---|---|---|---|---|---|
| DeepSeek V4 Pro Max | 76.2% | $0.87 | MIT | 1.6T/49B | Algorithms, general Rust, self-hosting |
| Kimi K2.6 | 76.7% | $4.00 | Modified MIT | 1T/32B | Agentic Rust, tool use |
| DeepSeek V4 Flash Max | 73.3% | $0.28 | MIT | 284B/13B | Budget Rust CI, high-volume |
| Qwen 3.6 Flash | 71.3% | $0.90 | Apache 2.0 | 35B/3B | Consumer GPU deployment |
Rust Coding Cost Comparison
A typical Rust development session — fixing borrow checker errors, implementing trait bounds, debugging async code — might use 5M input tokens (codebase context) and 2M output tokens (generated fixes).
| Model | 5M Input | 2M Output | Per Session | 100 Sessions/mo |
|---|---|---|---|---|
| Claude Fable 5 | $50.00 | $100.00 | $150.00 | $15,000 |
| Claude Opus 4.8 | $25.00 | $50.00 | $75.00 | $7,500 |
| GPT-5.5 | $25.00 | $60.00 | $85.00 | $8,500 |
| DeepSeek V4 Pro Max | $2.18 | $1.74 | $3.92 | $392 |
| DeepSeek V4 Flash Max | $0.70 | $0.56 | $1.26 | $126 |
Final Verdict: Best AI for Every Rust Workflow
| Rust Use Case | Best Model | Budget Alternative |
|---|---|---|
| Crate development & bug fixing | Claude Fable 5 | Claude Opus 4.8 ($25) |
| CLI tool development | Claude Fable 5 | GPT-5.5 ($30) |
| Async runtimes (tokio) | Claude Fable 5 | DeepSeek V4 Pro ($0.87) |
| Web frameworks (axum, actix) | Claude Fable 5 | Qwen 3.7 Max ($3.75) |
| Unsafe code & systems programming | Claude Fable 5 | DeepSeek V4 Pro ($0.87) |
| Build systems & cargo automation | Claude Fable 5 | GPT-5.5 ($30) |
| Algorithms & data structures | DeepSeek V4 Pro | DeepSeek V4 Flash |
| Self-hosted / air-gapped Rust | DeepSeek V4 Pro (MIT) | Qwen 3.6 Flash (Apache 2.0) |
| Budget CI pipeline (high volume) | DeepSeek V4 Flash ($0.28) | Qwen 3.6 Flash ($0.90) |
Conclusion: Fable 5 Resets Rust AI
Claude Fable 5 leads every benchmark for Rust. 80.3% Pro, 88.0% Terminal-Bench, ~87% Multi, 94.5% GPQA. For crate development, CLI tools, async runtimes, and web frameworks — Fable 5 is the most capable Rust coding model ever released.
GPT-5.5 is the budget CLI alternative. At $5/$30 it handles high-volume terminal Rust at a lower price point.
DeepSeek V4 Pro remains algorithm king. 93.5% LiveCodeBench at $0.87/1M with MIT license. For self-hosted Rust teams and cost-sensitive CI.
Sources: Anthropic Fable 5 Announcement | LLM-Stats | SWE-bench Multi | Rust-SWE-bench Paper | DeepSeek V4 Card | Pro Leaderboard | Terminal-Bench Leaderboard.