
🆕 Updated June 9: Claude Fable 5 released — 80.3% SWE-bench Pro, 88.0% Terminal-Bench 2.1, ~87% SWE-bench Multilingual. The first Mythos-class model available to everyone. It leads every benchmark. Now the definitive #1 for Go coding. Test all models on CodingFleet.
🆕 Claude Fable 5 — Leads Every Benchmark
Anthropic released Claude Fable 5 on June 9, 2026 — the first publicly available Mythos-class model. 80.3% SWE-bench Pro (+11.1 over Opus 4.8), 88.0% Terminal-Bench 2.1 (+4.6 over GPT-5.5), ~87% SWE-bench Multilingual, 56.8% HLE no tools (+7.0 over Opus 4.8), 94.5% GPQA Diamond, 85.0% OSWorld-Verified, 86.9% BrowseComp. Fable 5 is #1 on every benchmark that matters. $10/$50 per 1M tokens. Available everywhere. See full leaderboard →
Go has a different relationship with AI than Rust or Python. It's simpler (no borrow checker, no lifetimes, no GC pauses). It's more uniform (gofmt, standard library conventions). But it powers the world's most performance-critical infrastructure — Kubernetes, Docker, Prometheus, Terraform, every major cloud platform. When an AI model writes bad Go, production pipelines break. We cross-reference SWE-bench Multilingual (1,632 tasks across 7 languages including 5 Go repos), SWE-bench Pro, Terminal-Bench, LiveCodeBench to rank top models for every Go workflow — from microservices to CLI tools, from Kubernetes operators to data pipelines. Here's the complete data. Test all models on CodingFleet.
🔵 Key Findings
- Claude Fable 5 is #1 on every benchmark. Leads Go across all workflows. 80.3% Pro, 88.0% Terminal-Bench, ~87% Multi, 94.5% GPQA. For web services, CLI tools, Kubernetes operators, and concurrent goroutine code — Fable 5 is the best model ever released.
- GPT-5.5 is the budget CLI alternative. 83.4% Terminal-Bench at $5/$30 per 1M tokens. Stronger value for high-volume terminal workflows where the 4.6-point gap is acceptable and cost-per-task is the priority.
- DeepSeek V4 Pro Max wins on algorithms + self-hosting. 93.5% LiveCodeBench, $0.87/1M, MIT. For Go data pipelines, algorithmic work, and air-gapped deployment at 1/57th Fable 5's price.
- Go is easier for AI than Rust. No borrow checker, no lifetimes, standard formatting. Models transfer their Python/JS training more effectively. Open-weight models achieve 90%+ of Fable 5's performance at 3% of the cost.
- SWE-bench Multilingual is the only benchmark with Go repos. Includes caddy, hugo, prometheus, gin, terraform — real Go infrastructure. Every model's score includes these repos.
Test these models on your own Go code at CodingFleet. See the SWE-bench Pro and Terminal-Bench leaderboards. Also: Best AI for Rust · Best AI for Python · Pricing Calculator.
Why Go Is Different for AI
Go presents a simpler challenge than Rust, but with its own nuances:
- No borrow checker. Go uses garbage collection. AI models trained on Python/JS can transfer their memory-management intuition directly.
- Goroutines and channels. Go's concurrency model is unique. Models must understand goroutine lifecycle, channel blocking, select statements, and subtle deadlock patterns that don't exist in other languages.
- Interface-based design. Go's implicit interface satisfaction is elegant but can confuse models. A struct that accidentally satisfies an interface produces bugs the compiler won't catch.
- Error handling.
if err != nilis simple but tedious. Models often forget error handling, especially in complex goroutine orchestration. Missing error checks are the #1 Go coding issue for AI. - Infrastructure context. Go code rarely exists in isolation. Models must understand Kubernetes, Docker, gRPC, protobuf, and cloud APIs. Terminal-Bench maps directly here.
- Large standard library. Models must know when to use
net/httpvsgin,database/sqlvsgorm,syncvs channels. Incorrect library choices are common.
SWE-bench Multilingual: The Go Benchmark
SWE-bench Multilingual is the only published benchmark with Go repositories and model scores. It contains 1,632 high-quality tasks across 7 languages (Java, TypeScript, JavaScript, Go, Rust, C, C++). The Go repos include: caddyserver/caddy (web server), gohugoio/hugo (static site generator), prometheus/prometheus (monitoring), gin-gonic/gin (web framework), hashicorp/terraform (infrastructure as code).
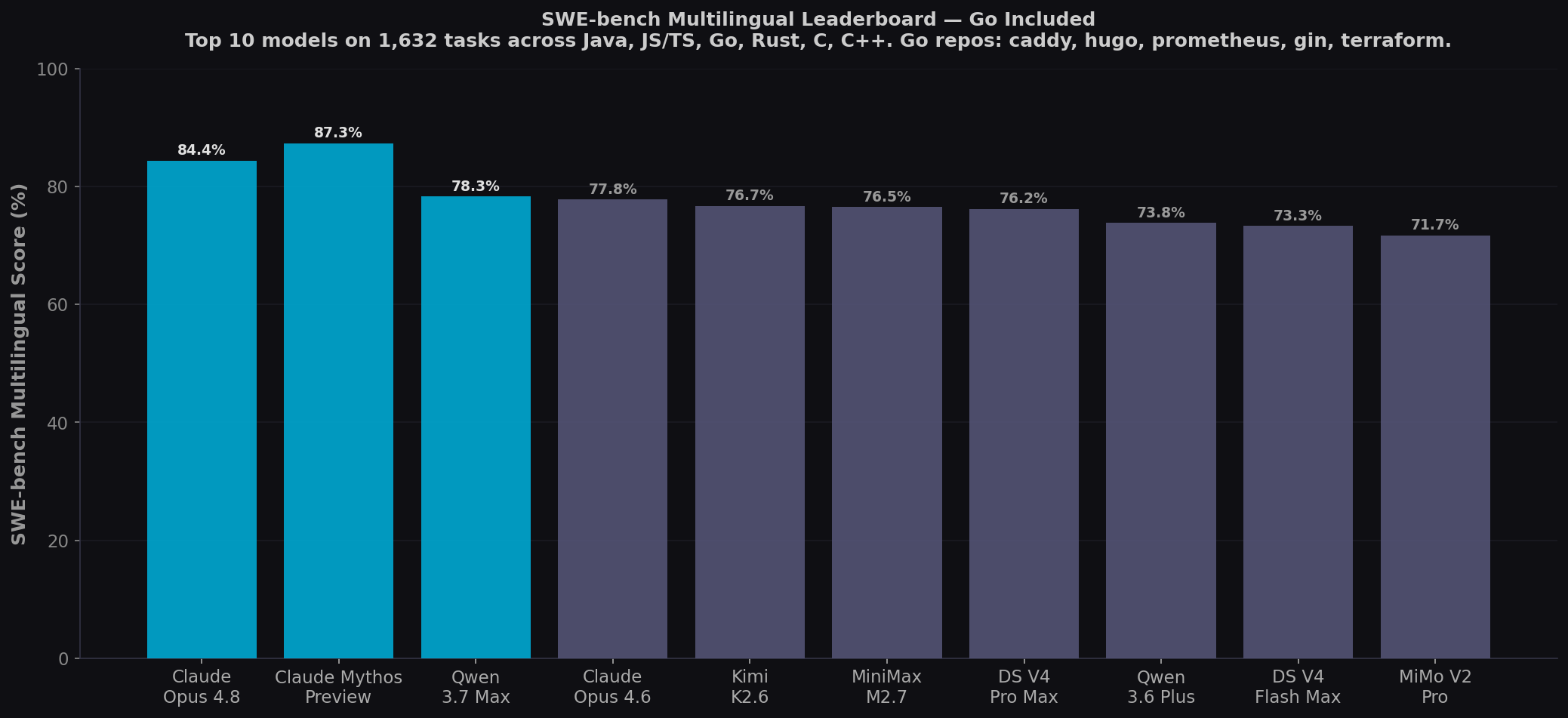
| Rank | Model | SWE-bench Multi | Pro | Terminal-Bench | LiveCodeBench | GPQA | Output $/1M | License |
|---|---|---|---|---|---|---|---|---|
| 1 | 🆕 Claude Fable 5 | ~87% | 80.3% | 88.0% | — | 94.5% | $50.00 | Proprietary |
| 2 | Claude Opus 4.8 | 84.4% | 69.2% | 82.7% | 88.8% | 91.3% | $25.00 | Proprietary |
| 3 | Qwen 3.7 Max | 78.3% | 60.6% | 69.7% | 91.6% | 87.4% | $3.75 | Proprietary |
| 4 | GPT-5.5 | ~82.6%* | 58.6% | 83.4% | — | 93.0% | $30.00 | Proprietary |
| 5 | DeepSeek V4 Pro Max | 76.2% | 55.4% | 67.9% | 93.5% | 90.1% | $0.87 | MIT |
| 6 | DeepSeek V4 Flash Max | 73.3% | 52.6% | 56.9% | 91.6% | 88.1% | $0.28 | MIT |
| 7 | Qwen 3.6 Flash | 71.3% | 49.5% | 51.5% | 80.4% | 86.0% | $0.90 | Apache 2.0 |
Sources: Anthropic Fable 5 Announcement · LLM-Stats · DeepSeek V4 Model Card. GPT-5.5 Multi score estimated from Verified (82.6%) — not officially published. Bold = open-weight. "—" = not published.
Go Task Mapping: Which Model for Which Workflow
Go spans microservices, CLI tools, infrastructure, DevOps, and data pipelines. Each maps to a different benchmark:
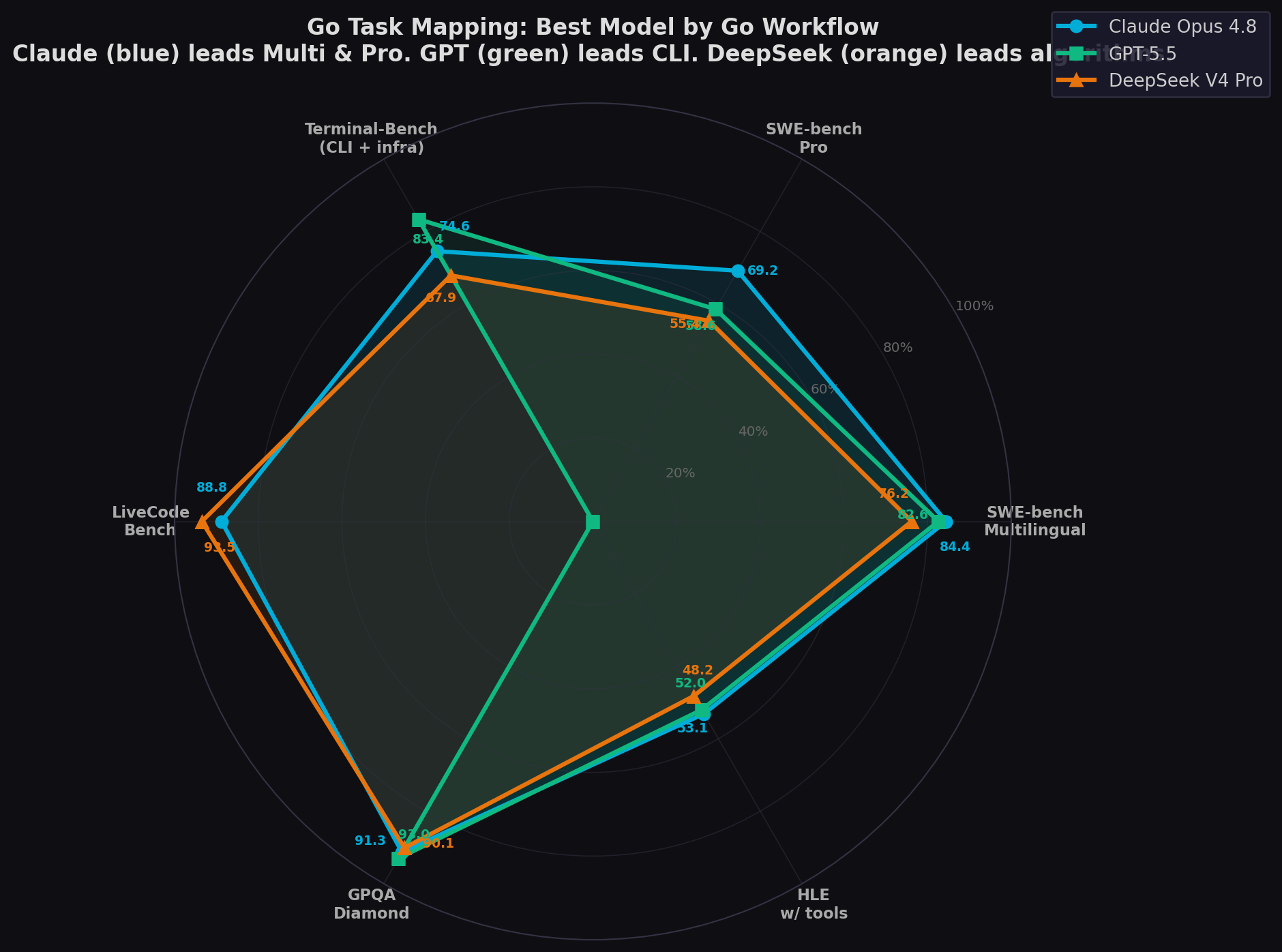
| Go Workflow | Best Proxy Benchmark | Why It Maps | Best Model | Score |
|---|---|---|---|---|
| Web services / API development | SWE-bench Pro | Multi-file, HTTP handlers, routing, middleware | Claude Fable 5 | 80.3% |
| Multi-language infrastructure code | SWE-bench Multilingual | Real Go repos (caddy, hugo, prometheus, gin, terraform) | Claude Fable 5 | ~87% |
| CLI tools (cobra, bubbletea) | Terminal-Bench 2.0/2.1 | Shell interaction, build systems, config management | Claude Fable 5 | 88.0% |
| Data pipelines / algorithms | LiveCodeBench | Data processing, sorting, graph algorithms | DeepSeek V4 Pro Max | 93.5% |
| Kubernetes operators / controllers | Terminal-Bench + Pro | CLI + infrastructure code + complex state | Claude Fable 5 | 80.3% |
| CI/CD / build automation | Terminal-Bench 2.0/2.1 | Build, test, deploy, package management | Claude Fable 5 | 88.0% |
| Concurrent / goroutine orchestration | SWE-bench Multilingual | Go repos in benchmark use goroutines extensively | Claude Fable 5 | ~87% |
Top Models for Go: Deep Dives
🥇 Claude Fable 5 — The Go King ($10/$50 per 1M)
- Every benchmark. #1 everywhere. 80.3% Pro, 88.0% Terminal-Bench, ~87% Multi, 94.5% GPQA, 56.8% HLE, 85.0% OSWorld. The first Mythos-class model generally available. For Go web services, CLI tools, Kubernetes operators, and concurrent code — Fable 5 is the best model ever released.
- Best for: Web services, Kubernetes operators, microservices, CLI tools, gRPC services, general Go infrastructure, concurrent code.
- Price: $10/$50 per 1M tokens. Prompt caching drops effective cost ~60-70% for iterative Go debugging. Free on Pro/Max/Team/Enterprise plans through June 22.
- Safety note: Queries on cybersecurity, biology, chemistry, or distillation topics fall back to Opus 4.8 (~5% of sessions).
- Also see: SWE-bench Pro Leaderboard · Terminal-Bench Leaderboard
🥈 GPT-5.5 — The Budget CLI Workhorse ($5/$30 per 1M)
- Terminal-Bench: 83.4%. Go's domain is infrastructure — and infrastructure is CLI-first. GPT-5.5 handles shell, build, and deploy workflows at a lower price point. For high-volume terminal Go where the 4.6-point gap to Fable 5 is acceptable.
- Best for: High-volume CLI automation, CI/CD pipelines where cost-per-task matters more than peak quality, Kubernetes tooling at scale.
- Also see: GPT-5.5 vs DeepSeek V4 Pro · GPT-5.5 vs Qwen 3.7 Max
🥉 DeepSeek V4 Pro Max — The Algorithm & Value King ($0.87/1M, MIT)
- LiveCodeBench: 93.5% — global #1. For Go data pipelines, sorting algorithms, concurrent processing, and transformation logic.
- 76.2% Multi at $0.87. 90% of Fable 5's capability at 1.7% of the cost. MIT-licensed and self-hostable.
- Best for: Data pipeline development, algorithmic Go, cost-sensitive CI, self-hosted Go assistants, air-gapped environments.
- Also see: DeepSeek V4 Pro vs Qwen 3.7 Max
Open-Weight Go Options
| Model | SWE-bench Multi | Output $/1M | License | Size | Best Go Use |
|---|---|---|---|---|---|
| DeepSeek V4 Pro Max | 76.2% | $0.87 | MIT | 1.6T/49B | General Go, self-hosting, algorithms |
| Kimi K2.6 | 76.7% | $4.00 | Modified MIT | 1T/32B | Agentic Go, MCP tool use |
| DeepSeek V4 Flash Max | 73.3% | $0.28 | MIT | 284B/13B | Budget Go CI, high-volume |
| Qwen 3.6 Flash | 71.3% | $0.90 | Apache 2.0 | 35B/3B | Consumer GPU, local deployment |
Go Coding Cost Comparison
A typical Go session — implementing a new API endpoint, configuring goroutine orchestration, writing tests — might use 3M input tokens (codebase context) and 1M output tokens (generated code).
| Model | 3M Input | 1M Output | Per Session | 100 Sessions/mo |
|---|---|---|---|---|
| Claude Fable 5 | $30.00 | $50.00 | $80.00 | $8,000 |
| Claude Opus 4.8 | $15.00 | $25.00 | $40.00 | $4,000 |
| GPT-5.5 | $15.00 | $30.00 | $45.00 | $4,500 |
| Qwen 3.7 Max | $7.50 | $3.75 | $11.25 | $1,125 |
| DeepSeek V4 Pro Max | $1.31 | $0.87 | $2.18 | $218 |
| DeepSeek V4 Flash Max | $0.42 | $0.28 | $0.70 | $70 |
Final Verdict: Best AI for Every Go Workflow
| Go Use Case | Best Model | Budget Alternative |
|---|---|---|
| Web services & API development | Claude Fable 5 | Claude Opus 4.8 ($25) |
| CLI tools & infrastructure automation | Claude Fable 5 | GPT-5.5 ($30) |
| Kubernetes operators & controllers | Claude Fable 5 | DeepSeek V4 Pro ($0.87) |
| Concurrent / goroutine orchestration | Claude Fable 5 | Kimi K2.6 ($4.00) |
| gRPC & protobuf services | Claude Fable 5 | Qwen 3.7 Max ($3.75) |
| CI/CD & build system Go code | Claude Fable 5 | GPT-5.5 ($30) |
| Data pipelines & algorithm-heavy Go | DeepSeek V4 Pro Max | DeepSeek V4 Flash Max |
| Self-hosted / air-gapped Go AI | DeepSeek V4 Pro (MIT) | Qwen 3.6 Flash (Apache 2.0) |
| Budget CI pipeline (high volume) | DS V4 Flash ($0.28) | Qwen 3.6 Flash ($0.90) |
Conclusion: Fable 5 Resets the Bar
Claude Fable 5 leads every benchmark that matters for Go. 80.3% Pro, 88.0% Terminal-Bench, ~87% Multi. It's the most capable Go coding model ever released — for web services, CLI tools, Kubernetes, and concurrent code.
GPT-5.5 is the budget CLI alternative. At $5/$30 vs Fable 5's $10/$50, it's the cost-conscious choice for high-volume terminal Go where the 4.6-point gap is acceptable.
DeepSeek V4 Pro Max wins on value and algorithms. 93.5% LiveCodeBench at $0.87/1M with MIT license. For data pipelines, self-hosted Go, and cost-sensitive CI at 1/57th Fable 5's price.
Go is easier for AI than Rust. The simpler language model and larger training corpus mean models perform better on Go than Rust across the same SWE-bench Multilingual data. But no single model wins every Go task — Fable 5 comes closest.
20+ LLMs on CodingFleet. Side-by-side Go testing. Fable 5 available now.
Sources: Anthropic Fable 5 Announcement (Jun 9, 2026) | LLM-Stats SWE-bench Multilingual Leaderboard | SWE-bench Multilingual Official | DeepSeek V4 Model Card | SWE-bench Pro Leaderboard | Terminal-Bench Leaderboard.