
Anthropic's Claude Fable 5 (June 9, 2026) vs OpenAI's GPT-5.5 (April 23, 2026). The Mythos-class newcomer against the reigning base-model king. Fable 5: $10/$50 per 1M — first publicly available Mythos-class model. GPT-5.5: $5/$30 per 1M — OpenAI's current flagship. Fable 5 leads all 8 shared benchmarks by 11.8 points on average. GPT-5.5 is 40% cheaper at list price and drops to $15/1M with Batch/Flex. The comparison reveals a clear capability gap — but GPT-5.5's price advantage and mature ecosystem keep it competitive for cost-sensitive teams. Test both on CodingFleet.
🔮 Key Findings
- Fable 5 leads all 8 shared benchmarks. Pro: +21.7. Terminal-Bench: +4.6. HLE: +15.4. FrontierCode: +23.6. Average gap: +11.8 points.
- GPT-5.5 is 40% cheaper. $30/1M output vs $50. Batch/Flex drops GPT-5.5 to $15 — 3.3× cheaper than Fable 5's batch price ($25).
- Fable 5 is 5× better value per Pro point. $0.62/point vs $0.51/point. But Batch GPT-5.5 at $0.26/point narrows the gap.
- GPT-5.5 has a mature ecosystem. Codex CLI, ChatGPT integration, DALL-E, broader tooling. Fable 5 is 2 days old.
- Fable 5 is free on subscription plans through June 22. GPT-5.5 included in ChatGPT Plus ($20/mo).
Also see: Fable 5 vs GPT-5.5 Pro · Pro Leaderboard · Terminal-Bench · Pricing Calculator.
Head-to-Head: Every Shared Benchmark
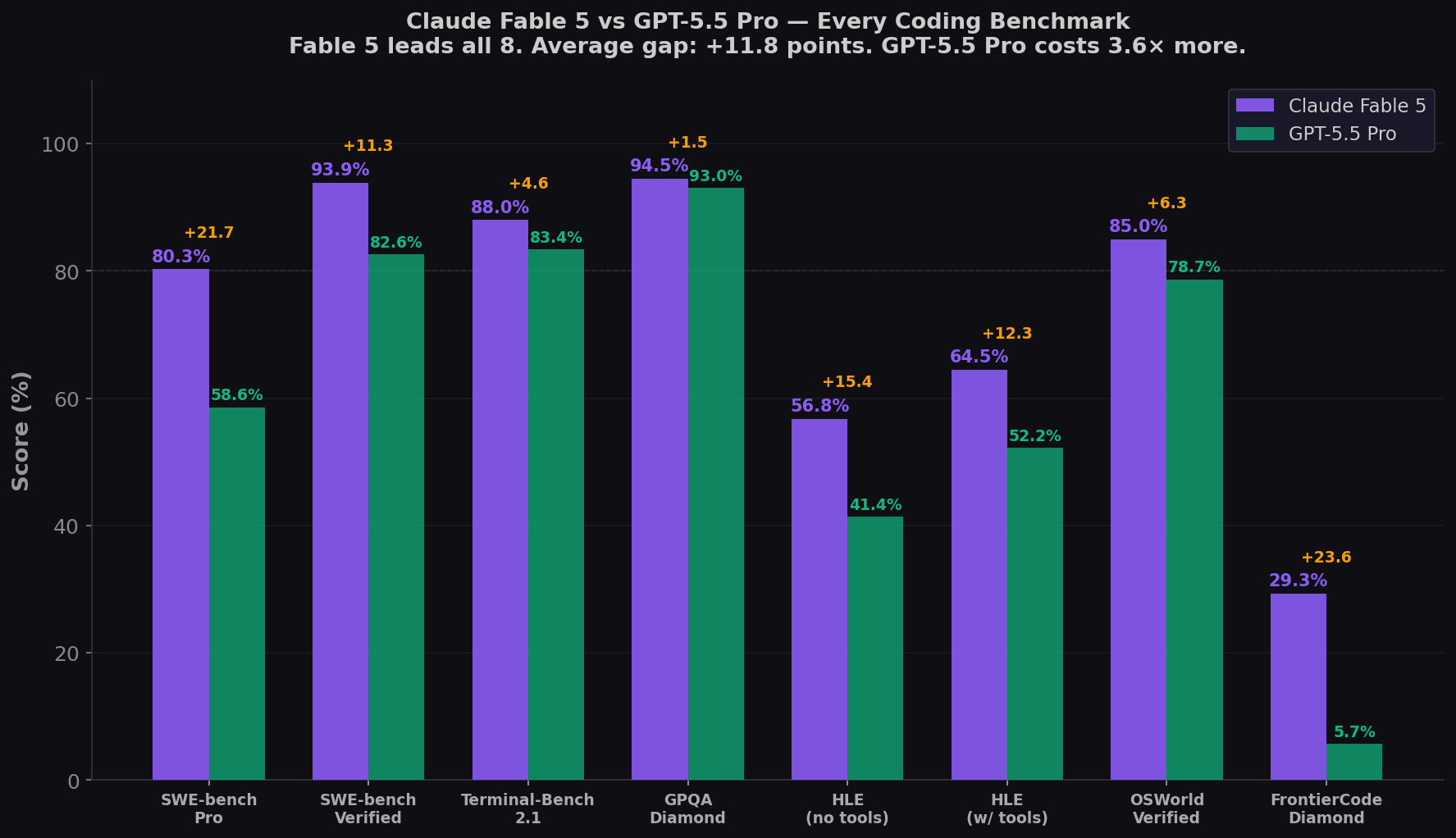
| Benchmark | Claude Fable 5 | GPT-5.5 | Gap | What It Measures |
|---|---|---|---|---|
| SWE-bench Pro | 80.3% | 58.6% | +21.7 | Real GitHub issues, multi-file, contamination-resistant |
| Terminal-Bench 2.1 | 88.0% | 83.4% | +4.6 | CLI coding, shell, build systems |
| GPQA Diamond | 94.5% | 93.0% | +1.5 | PhD-level science reasoning |
| HLE (no tools) | 56.8% | 41.4% | +15.4 | Multidisciplinary expert reasoning |
| HLE (with tools) | 64.5% | 52.2% | +12.3 | Expert reasoning + tool orchestration |
| OSWorld-Verified | 85.0% | 78.7% | +6.3 | Computer use, GUI navigation |
| FrontierCode Diamond | 29.3% | 5.7% | +23.6 | High-quality production coding |
| GDPval-AA | 1932 | 1769 | +163 | Professional work products (Elo) |
Sources: Anthropic Fable 5 · Vals.ai · OpenAI GPT-5.5 Launch Post. All scores vendor-reported.
Pricing: $50 vs $30 — Close at List, GPT-5.5 Wins on Batch
| Claude Fable 5 | GPT-5.5 | Winner | |
|---|---|---|---|
| Input $/1M | $10.00 | $5.00 | GPT-5.5 |
| Output $/1M | $50.00 | $30.00 | GPT-5.5 |
| Cached Input $/1M | $1.00 | $0.50 | GPT-5.5 |
| Batch Output $/1M | $25.00 | $15.00 | GPT-5.5 |
| Prompt caching | ✅ 90% discount | ✅ 90% discount | Tie |
| Free tier | ✅ Sub plans thru Jun 22 | ✅ ChatGPT Plus ($20/mo) | Fable 5 (free trial) |
| Context | 1M tokens | 1M tokens | Tie |
Real-World Coding Session Cost
A typical heavy coding session — 3M input + 1M output tokens:
| Model | Per Session (Standard) | Per Session (Batch) | 100 Sessions/mo (Batch) |
|---|---|---|---|
| Claude Fable 5 | $80.00 | $40.00 | $4,000 |
| GPT-5.5 | $45.00 | $22.50 | $2,250 |
At Batch pricing, GPT-5.5 costs $2,250/month for 100 sessions — 44% less than Fable 5 at $4,000. For cost-sensitive teams running high-volume batch coding, GPT-5.5 is genuinely cheaper.
Ecosystem & Maturity
| Claude Fable 5 | GPT-5.5 | |
|---|---|---|
| Age | 2 days (Jun 9, 2026) | 48 days (Apr 23, 2026) |
| CLI Agent | Claude Code | Codex CLI |
| IDE integration | Cursor, Windsurf, VS Code | Codex, GitHub Copilot, VS Code |
| Chat interface | Claude.ai | ChatGPT |
| Tool protocol | MCP (Model Context Protocol) | Function calling, GPT Actions |
| Multimodal input | Text + images | Text + images |
| Safety | Cyber/bio/chemistry classifiers → Opus 4.8 | Standard OpenAI moderation |
Verdict: Capability vs Cost
| Criterion | Winner | Margin |
|---|---|---|
| Bug fixing (Pro) | Fable 5 | +21.7 points |
| CLI coding (TB) | Fable 5 | +4.6 points |
| List price | GPT-5.5 | 40% cheaper ($30 vs $50) |
| Batch price | GPT-5.5 | 40% cheaper ($15 vs $25) |
| $ per Pro point (standard) | Fable 5 | $0.62 vs $0.51 |
| $ per Pro point (batch) | GPT-5.5 | $0.26 vs $0.31 |
| Ecosystem maturity | GPT-5.5 | 48 days of production use |
| Raw capability | Fable 5 | Leads all 8 benchmarks |
Choose Fable 5 if you need maximum coding capability — Pro +21.7, Terminal-Bench +4.6, FrontierCode +23.6. The Mythos-class reasoning gap is real. Choose GPT-5.5 if you're cost-sensitive, running batch workloads, or heavily invested in the OpenAI ecosystem. At $15/1M batch output, GPT-5.5 delivers solid coding performance at a much lower price point.
The honest truth: Fable 5 is the better coding model. GPT-5.5 is the better deal for budget-conscious teams. See also our Fable 5 vs GPT-5.5 Pro comparison for the premium variant matchup.