
Anthropic's Claude Fable 5 (June 9, 2026) vs OpenAI's GPT-5.5 Pro (April 24, 2026). Two frontier models at opposite ends of the value spectrum. Fable 5: $10/$50 per 1M tokens — the first publicly available Mythos-class model. GPT-5.5 Pro: $30/$180 per 1M tokens — OpenAI's parallel test-time compute variant. Fable 5 leads all 8 coding benchmarks by an average of 11.8 points while costing 72% less per output token. GPT-5.5 Pro's parallel compute shows gains on BrowseComp (+5.7) and FrontierMath (+4.2), but OpenAI hasn't published separate Pro coding scores. Test both on CodingFleet.
🔮 Key Findings
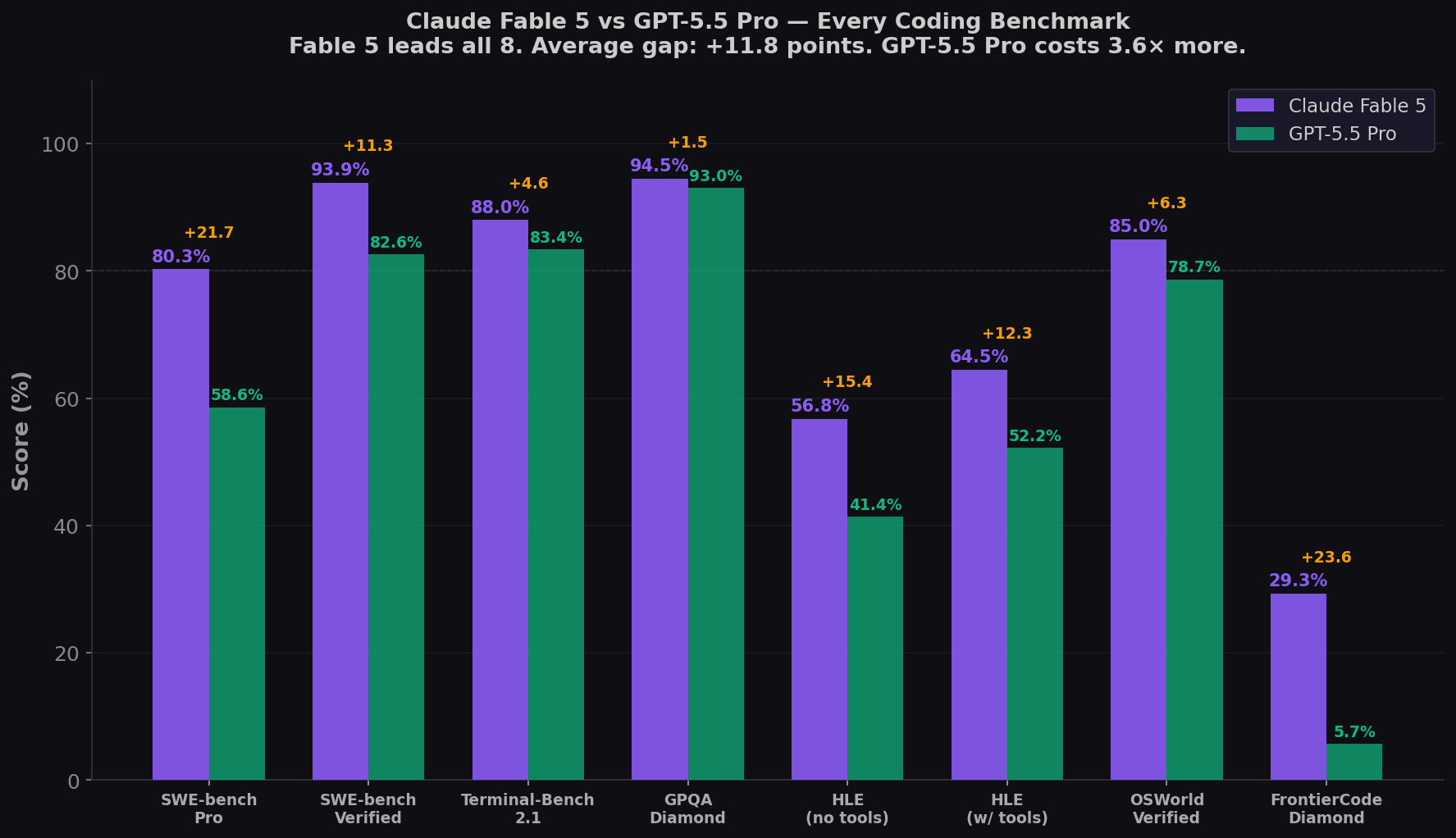
- Fable 5 leads all 8 coding benchmarks. SWE-bench Pro: +21.7. Terminal-Bench: +4.6. HLE no tools: +13.7. FrontierCode Diamond: +23.6. Average gap: +11.8 points.
- GPT-5.5 Pro shows gains on non-coding benchmarks. BrowseComp: 90.1% (+5.7 over base GPT-5.5). FrontierMath T4: 39.6% (+4.2). HLE no tools: 43.1% (+1.7). Parallel compute helps reasoning tasks — but has no published coding uplift.
- Fable 5 costs 72% less per output token. $50/1M vs $180/1M. Per Pro point: $0.62 vs $3.07 — 5× better value.
- GPT-5.5 Pro has NO published SWE-bench Pro or Terminal-Bench scores. OpenAI's benchmark table shows "—" for GPT-5.5 Pro on both coding benchmarks. The Pro variant's coding performance is entirely unknown.
- For coding, the choice is Fable 5. For browse/research/math, GPT-5.5 Pro shows real parallel compute gains. Different tools for different jobs.
See: SWE-bench Pro Leaderboard · Terminal-Bench · Pricing Calculator · Claude Opus 4.8 vs GPT-5.5.
Head-to-Head: Every Benchmark
| Benchmark | Claude Fable 5 | GPT-5.5 Pro | Gap | What It Measures |
|---|---|---|---|---|
| SWE-bench Pro | 80.3% | 58.6%* | +21.7 | Real GitHub issues, multi-file, contamination-resistant |
| SWE-bench Verified | 93.9% | 82.6%* | +11.3 | 500 Python issues (contaminated) |
| Terminal-Bench 2.1 | 88.0% | 83.4%* | +4.6 | CLI coding, shell, build systems |
| GPQA Diamond | 94.5% | 93.6%* | +0.9 | PhD-level science reasoning |
| HLE (no tools) | 56.8% | 43.1% | +13.7 | Multidisciplinary expert reasoning |
| HLE (with tools) | 64.5% | 52.2%* | +12.3 | Expert reasoning + tool orchestration |
| OSWorld-Verified | 85.0% | 78.7%* | +6.3 | Computer use, GUI navigation |
| FrontierCode Diamond | 29.3% | 5.7%* | +23.6 | High-quality production coding |
| BrowseComp | 86.9% | 90.1% | -3.2 | Web browsing research agent |
| FrontierMath T4 | — | 39.6% | — | Hardest math problems |
| GDPval-AA | 1932 | 1769* | +163 | Professional work products |
* = GPT-5.5 base score — OpenAI has NOT published a separate GPT-5.5 Pro score for this benchmark. Bold green = GPT-5.5 Pro wins. Sources: Anthropic · Vellum GPT-5.5 Benchmark Table · OpenAI Pricing. ⚠️ Verified contaminated.
What GPT-5.5 Pro Actually Improves
GPT-5.5 Pro is not a separately trained model. It's the same GPT-5.5 base model with parallel test-time compute scaling — running multiple inference paths and selecting the best result. OpenAI has published separate Pro scores for only 4 benchmarks:
| Benchmark | GPT-5.5 | GPT-5.5 Pro | Pro Uplift |
|---|---|---|---|
| BrowseComp | 84.4% | 90.1% | +5.7 |
| FrontierMath T4 | 35.4% | 39.6% | +4.2 |
| HLE (no tools) | 41.4% | 43.1% | +1.7 |
| GDPval | 84.9% | 82.3% | -2.6 |
Parallel compute helps most on research/browsing tasks (BrowseComp +5.7) and math (FrontierMath T4 +4.2). But on GDPval (professional work), Pro actually scores lower than base. And critically: OpenAI has not published any GPT-5.5 Pro scores for SWE-bench Pro or Terminal-Bench. The Pro variant's coding ability is unmeasured and unproven.
⚠️ Coding benchmarks marked with * use GPT-5.5 base scores
OpenAI's own benchmark table shows "—" for GPT-5.5 Pro on SWE-bench Pro and Terminal-Bench. The Pro variant's coding uplift — if any — is unknown. For research/browsing, the Pro gains are real and published.
Pricing: $50 vs $180 — The 3.6× Gap
| Claude Fable 5 | GPT-5.5 Pro | |
|---|---|---|
| Input $/1M | $10.00 | $30.00 |
| Output $/1M | $50.00 | $180.00 |
| Cached Input $/1M | $1.00 | — (no cache) |
| Batch/Flex discount | ✅ 50% | ✅ 50% |
| Prompt caching | ✅ 90% discount | ❌ Not available |
| Free trial | ✅ Pro/Max/Team thru Jun 22 | ❌ |
| Context window | 1M tokens | 1.05M tokens |
Verdict: Different Tools for Different Jobs
| Use Case | Winner | Why |
|---|---|---|
| Bug fixing / multi-file code | Fable 5 | +21.7 Pro points. Published, proven. |
| CLI / terminal agent coding | Fable 5 | +4.6 Terminal-Bench. Published. |
| Production-quality coding | Fable 5 | +23.6 FrontierCode. Massive gap. |
| Web browsing research | GPT-5.5 Pro | 90.1% BrowseComp. Real Pro uplift. |
| Hardest math problems | GPT-5.5 Pro | 39.6% FrontierMath T4. Pro helps. |
| Professional work products | Fable 5 | 1932 GDPval-AA vs 1769. |
| Value for money | Fable 5 | 72% cheaper, 5× better $/Pro pt. |
For coding, Fable 5 is the clear choice. For web research and math, GPT-5.5 Pro's parallel compute shows real gains on published benchmarks. The honest assessment: these models excel at different things. See also our Fable 5 vs GPT-5.5 base comparison for the non-Pro matchup.