
Two Anthropic models. One family. Different price points. Claude Opus 4.8 is the $25/1M flagship — 69.2% SWE-bench Pro, 88.6% Verified, #1 on the AA Intelligence Index. Claude Sonnet 4.6 is the $15/1M workhorse — 79.6% Verified, 59.1% Terminal-Bench, 72.5% OSWorld. Opus dominates every shared benchmark by 1 to 13 points. But Sonnet costs 1.7x less, handles 1M context at standard pricing with no long-context surcharge, and was described by Anthropic as preferred by developers over Claude Opus 4.5 itself. Here's the complete comparison backed by Anthropic's system cards, the Google DeepMind model card, Mashable, and Caylent. Try both on CodingFleet.
TL;DR — Key Findings
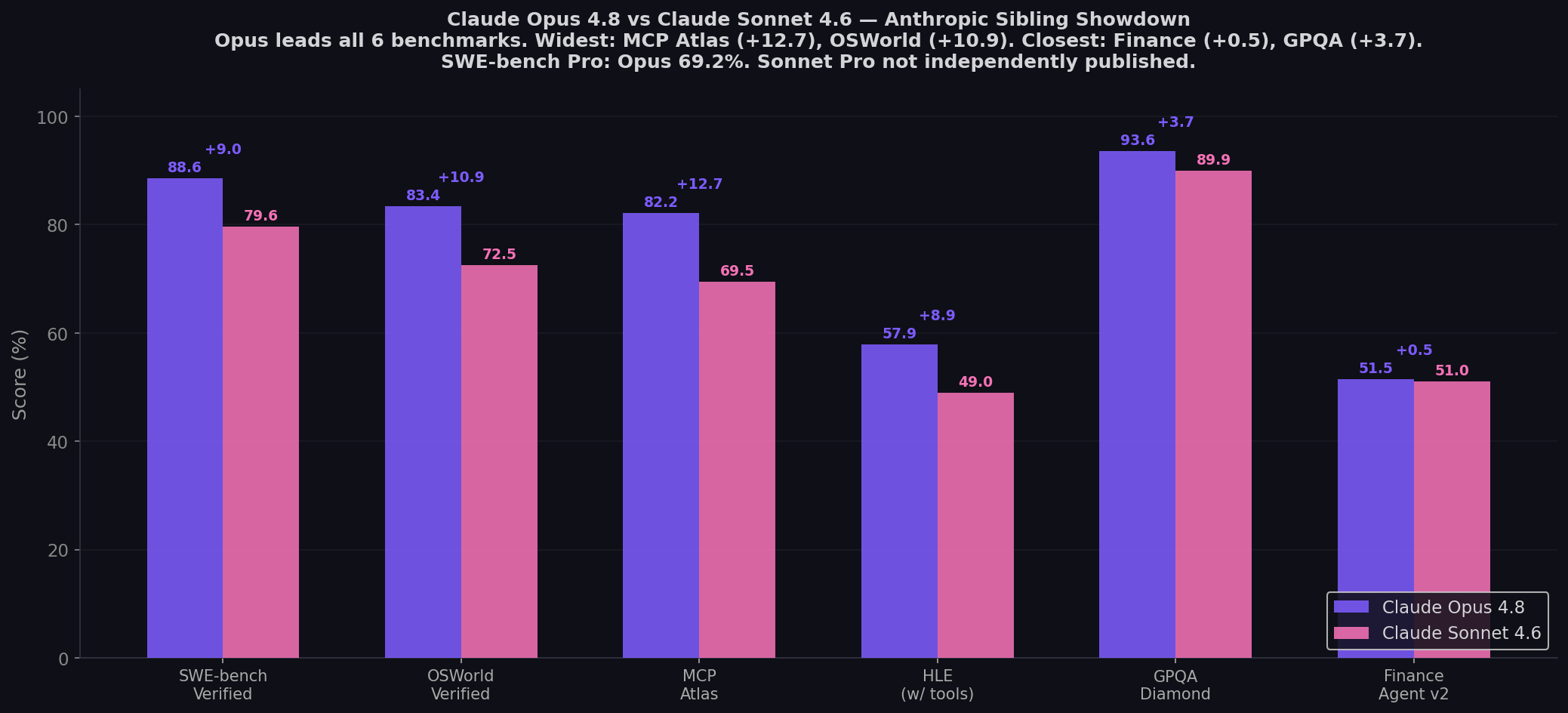
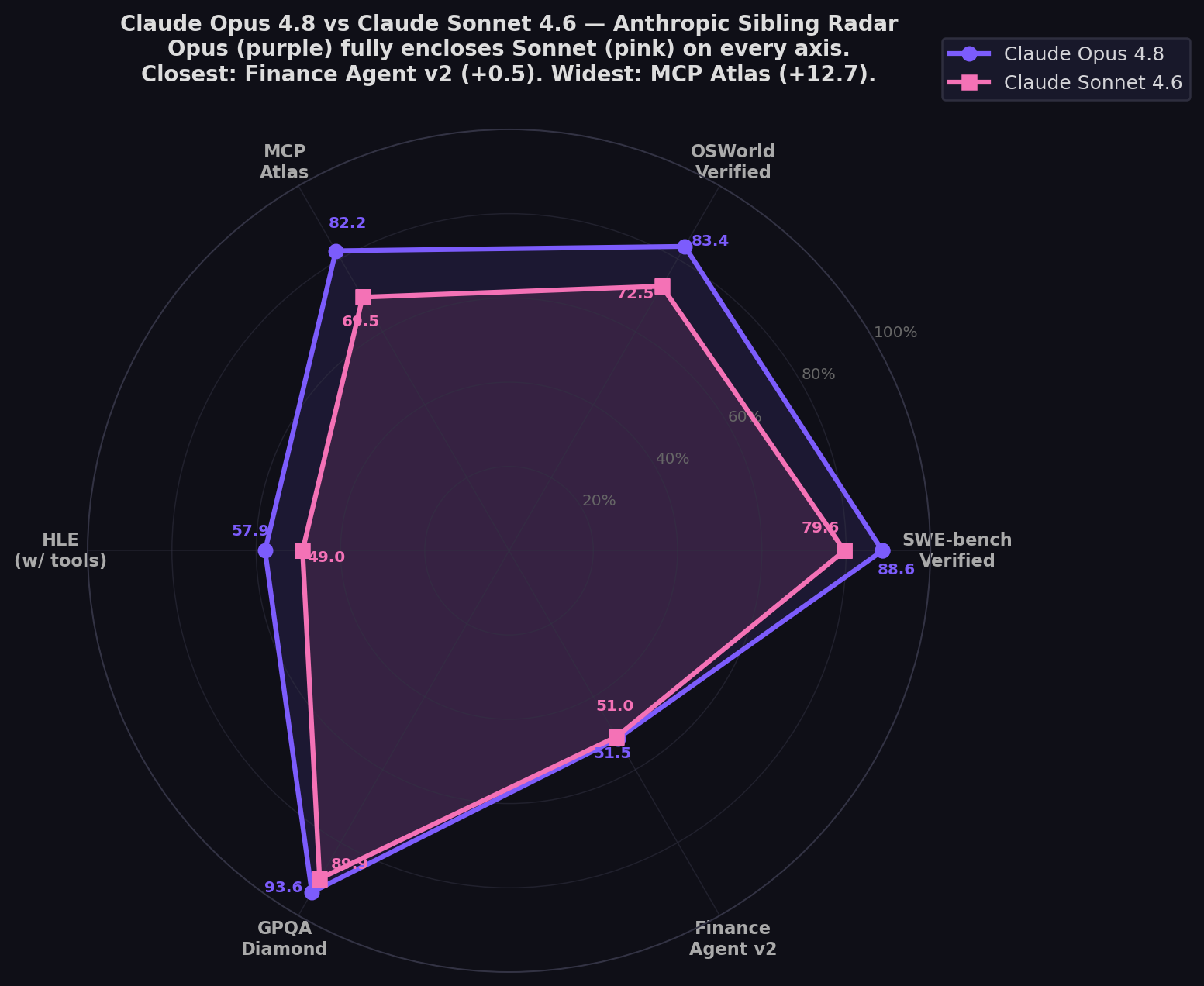
- Opus 4.8 leads all shared benchmarks: MCP Atlas (+12.7), OSWorld (+10.9), SWE-bench Verified (+9.0), HLE (+8.9), GPQA (+3.7), Finance Agent v2 (+0.5). Clean sweep.
- 1.7x price gap: Opus $5/$25 vs Sonnet $3/$15. At 100M tokens/month: Opus $2,500 vs Sonnet $1,500.
- Both have 1M context at standard pricing: Since March 2026, no long-context surcharge. Sonnet at 40% lower per-token cost is compelling for large codebases.
- Anthropic's own words: "Many developers with early access to Sonnet 4.6 preferred the model — not just to its predecessor, but also Claude Opus 4.5."
Try both models on CodingFleet
Benchmark Comparison
| Benchmark | Claude Opus 4.8 | Claude Sonnet 4.6 | Winner |
|---|---|---|---|
| SWE-bench Pro | 69.2% | — (not published) | Opus |
| SWE-bench Verified | 88.6% | 79.6% | Opus (+9.0) |
| OSWorld-Verified | 83.4% | 72.5% | Opus (+10.9) |
| MCP Atlas | 82.2% | 69.5% | Opus (+12.7) |
| Terminal-Bench (2.1 vs 2.0)* | 74.6% (2.1) | 59.1% (2.0) | Versions differ |
| GDPval-AA (Elo) | 1,890 | 1,676 | Opus (+214) |
| HLE (with tools) | 57.9% | 49.0% | Opus (+8.9) |
| GPQA Diamond | 93.6% | 89.9% | Opus (+3.7) |
| MMMU-Pro | 75.2% | 74.5% | Opus (+0.7 — near tie) |
| CharXiv Reasoning | 82.1% | 72.4% | Opus (+9.7) |
| Finance Agent v2 | 51.5% | 51.0% | Opus (+0.5 — near tie) |
| ARC-AGI-2 | — | 58.3% (60.4% high) | Sonnet — Opus not published |
| Output Price /1M tok | $25.00 | $15.00 | Sonnet (1.7x cheaper) |
Sources: Vellum — Opus 4.8 system card | Anthropic — Sonnet 4.6 announcement | Mashable — Sonnet benchmarks | Caylent — Sonnet in production | Google DeepMind model card. *TB: Opus=2.1 Terminus-2, Sonnet=2.0. Not directly comparable.
MCP Atlas: The 12.7-Point Tool Orchestration Gap
The widest gap on any shared benchmark. Opus 4.8 at 82.2% vs Sonnet 4.6 at 69.5% on multi-step MCP tool orchestration. For developers building agent pipelines with complex tool chains, the Opus premium translates directly to reliability — fewer failed tool calls, better coordination across MCP servers, and stronger multi-step planning. The gap is structural: Opus was designed for deep orchestration, while Sonnet prioritizes speed and efficiency.
Finance Agent v2: The 0.5-Point Convergence
The closest benchmark. Opus at 51.5% vs Sonnet at 51.0%. On structured financial analysis with tool use, the models are functionally identical. This is where Sonnet's adaptive thinking architecture works best — allocating reasoning budget dynamically. Anthropic's own announcement highlighted Sonnet's strategic behavior: "it invested heavily in capacity for the first ten simulated months, then pivoted sharply to profitability."
Sonnet's Secret Weapon: 1M Context at Standard Pricing
In March 2026, Anthropic made the full 1M context window GA at standard pricing for both models. At Sonnet's $3/$15 rates vs Opus's $5/$25, loading entire codebases into Sonnet costs 40% less per token. For teams working with large codebases, this compounds quickly.
Architecture & Ecosystem
| Feature | Claude Opus 4.8 | Claude Sonnet 4.6 |
|---|---|---|
| Release | May 28, 2026 | February 17, 2026 |
| Context Window | 1M tokens | 1M tokens |
| Input Price | $5.00/1M | $3.00/1M |
| Output Price | $25.00/1M | $15.00/1M |
| Cache Read | $0.50/1M | $0.30/1M |
| Batch (50% off) | $2.50/$12.50 | $1.50/$7.50 |
| Max Output Tokens | 128K | 64K |
| Thinking Mode | Max effort, deep reasoning | Adaptive — zero overhead until needed |
Pricing: 1.7x Economics
At 100M output tokens/month: Opus $2,500 vs Sonnet $1,500. With Batch: Opus $1,250 vs Sonnet $750. With prompt caching (90% off reads): the gap widens further.
Which Model Should You Use?
| Use Case | Winner | Why |
|---|---|---|
| Hard bug fixing | Opus ✅ | 69.2% Pro — most reliable non-Mythos coding model |
| MCP tool orchestration | Opus ✅ | +12.7 MCP Atlas — widest gap. Tool chains need reliability |
| Computer use / GUI | Opus ✅ | +10.9 OSWorld. Decisive for desktop automation |
| Deep reasoning | Opus ✅ | +8.9 HLE w/tools. For hard academic/research problems |
| Large codebase (budget) | Sonnet ✅ | 1M ctx at standard pricing, 40% less per token |
| High-volume coding | Sonnet ✅ | 1.7x cheaper. $750 vs $1,250/month at 100M with Batch |
| Financial analysis agents | Near Tie | Finance v2: 51.5% vs 51.0%. 0.5 pts apart |
Conclusion: Both Anthropic, Different Budgets
Claude Opus 4.8 is the stronger model — it leads every shared benchmark, often by double-digit margins. For teams where correctness, reliability, and tool orchestration precision justify the premium, Opus is the answer.
Claude Sonnet 4.6 is the smarter value — 1.7x cheaper, adaptive thinking that saves tokens without sacrificing depth, and strong enough to have been preferred by developers over Opus 4.5. For high-volume coding and budget-constrained teams, Sonnet is the optimal choice.
Anthropic's own guidance: "Opus 4.6 remains the strongest option for tasks that demand the deepest reasoning. Sonnet 4.6 offers strong performance at any thinking effort, even with extended thinking off."
20+ LLMs available. Test Opus 4.8 and Sonnet 4.6 side-by-side.
Sources & Links
- Vellum — Claude Opus 4.8 Benchmarks Explained
- Anthropic — Introducing Claude Sonnet 4.6
- MorphLLM — Claude Benchmarks 2026
- Mashable — Sonnet 4.6 benchmarks
- Caylent — Sonnet 4.6 in Production
- Rootly — Sonnet 4.6 SRE benchmarks
- Google DeepMind model card — cross-model comparison
- OpenRouter — Sonnet 4.6 pricing & specs