
📊 TL;DR — Key Findings
- Opus 4.8 dominates 5 of 6 shared benchmarks: Pro (+10.6), OSWorld (+10.3), TB (+7.9), HLE (+3.9), GPQA (+3.1). Kimi wins BrowseComp (-3.9).
- 6.25× price gap: Opus $25/1M output vs Kimi $4/1M. At 100M tokens/month: Opus $2,500 vs Kimi $400.
- Kimi is faster + lower latency: 71 tok/s vs 55 tok/s. 0.42s latency vs 1.62s (OpenRouter p50).
- Opus has 4× larger context: 1M vs 262K tokens — decisive for full-codebase work.
- Kimi is open-weight: Weights on HuggingFace (Modified MIT). Self-host, fine-tune, air-gap. Opus is proprietary.
- Composio real-world test: Kimi solved a Minetest mod at $0.39 (vs Opus $3.59) but failed a Google Sheets integration that Opus completed.
Try both models side-by-side on your own code at CodingFleet →
Benchmark Comparison
| Benchmark | Claude Opus 4.8 | Kimi K2.6 | Winner |
|---|---|---|---|
| SWE-bench Pro ★ | 69.2% | 58.6% | Opus (+10.6) |
| SWE-bench Verified ⚠️ | 88.6% | 80.2% | Opus (+8.4) |
| Terminal-Bench (2.1 vs 2.0)* | 74.6% (2.1) | 66.7% (2.0) | ⚠️ Different versions |
| OSWorld-Verified | 83.4% | 73.1% | Opus (+10.3) |
| HLE (with tools) | 57.9% | 54.0% | Opus (+3.9) |
| BrowseComp | 79.3% | 83.2% | Kimi (+3.9) |
| BrowseComp (Agent Swarm) | — (no swarm) | 86.3% | Kimi — unique capability |
| DeepSearchQA (F1) | 91.3% | 92.5% | Kimi (+1.2) |
| GPQA Diamond | 93.6% | 90.5% | Opus (+3.1) |
| LiveCodeBench v6 | 88.8% | 89.6% | Kimi (+0.8 — near tie) |
| AA Intelligence Index | 61.4 (#1) | ~54 | Opus (+7.4) |
| Output Price /1M tok | $25.00 | $4.00 | Kimi (6.25× cheaper) |
| Speed (tok/s, OpenRouter p50) | 55 tok/s | 71 tok/s | Kimi (1.3× faster) |
| Latency (OpenRouter p50) | 1.62s | 0.42s | Kimi (3.9× lower) |
| Context Window | 1M tokens | 262K tokens | Opus (4× larger) |
Sources: Vellum — Opus 4.8 benchmarks | Kimi K2.6 official tech blog | OpenRouter comparison | Lushbinary Kimi guide | Composio real-world test. *TB: Opus=2.1 (Terminus-2), Kimi=2.0 (Terminus-2). Not directly comparable — TB 2.1 is harder.
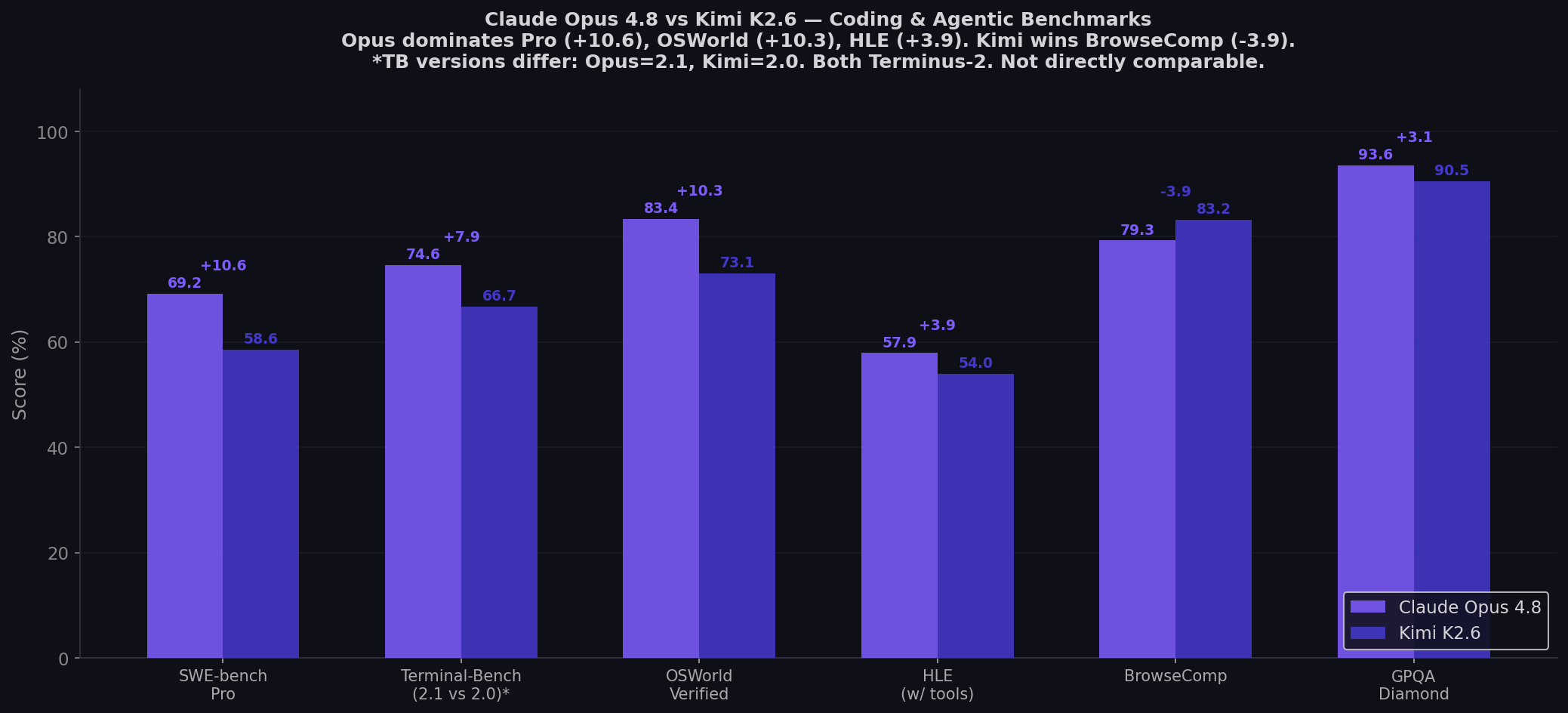

SWE-bench Pro: The 10.6-Point Reliability Gap
The defining number. Opus 4.8 at 69.2% vs Kimi K2.6 at 58.6%. A 10.6-point gap on the benchmark that most directly tests what developers care about: solving real GitHub issues across Django, Flask, scikit-learn, and other production repos. Vellum's analysis captures the dynamic: "The harder the variant, the bigger the gap." On SWE-bench Verified (the easier, contaminated variant), the gap is 8.4 points. On Pro (harder, multi-file, contamination-resistant), it's 10.6. Opus 4.8's advantage widens with task complexity — a pattern that holds across every comparison.
The Composio Real-World Test: $0.39 vs $3.59
Composio tested Kimi K2.6 against Claude Opus 4.7 on two real coding tasks. The results are illuminating — and map directly to the Opus 4.8 comparison. On a Minetest mod (local bounty board), Kimi succeeded at $0.39 vs Opus at $3.59 — a 9× cost advantage with working code. But on a Google Sheets integration (cross-service, authentication, external APIs), Kimi burned 135K+ tokens, cost $5.03, and "still did not really get any closer." Opus completed it. The pattern: Kimi is excellent for bounded coding tasks where the cost savings compound. Opus is necessary for complex integrations where reliability matters more than cost.
BrowseComp: Kimi's Signature Win
The single shared benchmark where Kimi beats Opus 4.8 — 83.2% vs 79.3%. And with Agent Swarm, it jumps to 86.3% — a capability Opus doesn't have at all. For web-connected agentic workflows — search, navigate, synthesize across multiple pages — Kimi's architecture provides a genuine advantage. Cole Medin's mixed-provider benchmark (209K subscribers, 4,364 views) tested the exact pairing: "Opus for deep reasoning, Kimi as the workhorse for everything else. It works — the factory shipped its first mixed-provider PR cleanly."
Architecture & Ecosystem
| Feature | Claude Opus 4.8 | Kimi K2.6 |
|---|---|---|
| Developer | Anthropic | Moonshot AI (Beijing) |
| Release Date | May 28, 2026 | April 20, 2026 |
| Model Class | Proprietary Frontier | Open-Weight (Modified MIT) |
| Context Window | 1M tokens | 262K tokens |
| Speed (tok/s, p50) | 55 tok/s | 71 tok/s |
| Latency (p50) | 1.62s | 0.42s |
| Input Modalities | Text, Image, Computer Use | Text, Image |
| Agent Architecture | Claude Code, MCP native, Dynamic Workflows | Agent Swarm: 300 sub-agents, 4,000 steps |
| Max Output Tokens | 128K | 262K |
| Quantization | Unknown | INT4 |
| Weights Available | No | Yes — HuggingFace |
| Providers (OpenRouter) | 3 | 21 |
Why Opus 4.8 Wins: The Reliability Premium
Opus 4.8 leads on every shared benchmark except BrowseComp — often by double-digit margins. The 35.9% hallucination rate is the lowest among all frontier models — for agentic coding where a single fabricated API call breaks an entire workflow, this compounds across thousands of steps. The native Claude Code + MCP ecosystem, Dynamic Workflows with adversarial verification, and mid-conversation system messages give Opus infrastructure maturity that Kimi's younger ecosystem can't match.
Why Kimi K2.6 Wins: The Freedom + Orchestration Premium
Kimi K2.6's Agent Swarm architecture (300 parallel sub-agents, 4,000 steps, BrowseComp Swarm 86.3%) addresses a fundamentally different need. Open-weight (HuggingFace, Modified MIT), INT4 quantization, 21 OpenRouter providers, 71 tok/s with 0.42s latency — Kimi is faster, cheaper, and more deployable. For teams that need coding capability at 6.25× lower cost, with agentic orchestration that Opus can't match, Kimi is the clear choice.
Which Model Should You Use?
| Use Case | Winner | Why |
|---|---|---|
| Multi-file bug fixing | Opus ✅ | +10.6 Pro — most reliable coding model below Mythos |
| Computer use / GUI | Opus ✅ | +10.3 OSWorld — widest gap on any benchmark |
| Academic reasoning | Opus ✅ | +3.9 HLE, +3.1 GPQA — consistent reasoning edge |
| Full-codebase work | Opus ✅ | 1M context vs 262K — 4× more codebase in memory |
| Web browsing agents | Kimi ✅ | 83.2% BrowseComp, 86.3% Swarm — unique architecture |
| Self-hosting / air-gapped | Kimi ✅ | Open-weight, INT4, 21 providers. Opus is proprietary only |
| High-volume / budget | Kimi ✅ | 6.25× cheaper, 1.3× faster, 3.9× lower latency |
| Mixed-provider stack | Both ✅ | Opus for planning + Kimi for building — Cole Medin tested |
Conclusion: The King and The Orchestrator
Claude Opus 4.8 is the better coding model. It leads on every shared benchmark except BrowseComp, with double-digit margins on the tests that matter most for production coding agents. For teams where correctness and reliability justify the premium, Opus 4.8 is the safe choice.
Kimi K2.6 is the better agentic orchestrator — and at 6.25× lower cost, it makes high-volume AI coding accessible. The Composio test ($0.39 vs $3.59) demonstrates what this means in practice: Kimi can solve real coding tasks at a fraction of the cost, but stumbles on complex integrations where Opus's reliability premium pays off.
The practical answer: use both. Opus for hard reasoning, architecture, and reliability-critical tasks. Kimi for volume, agentic orchestration, and budget-constrained workflows. The mixed-provider stack is not a compromise — it's the optimal allocation of capability per dollar.
20+ LLMs available on CodingFleet. Test Claude Opus 4.8 and Kimi K2.6 side-by-side on your own code.
📚 Sources & Links
- Vellum — Claude Opus 4.8 Benchmarks Explained
- Kimi K2.6 Official Tech Blog — published comparison table
- OpenRouter — Opus 4.8 vs Kimi K2.6 comparison — pricing, speed, latency
- Lushbinary — Kimi K2.6 Developer Guide
- Composio — Kimi K2.6 vs Opus 4.7 real-world test
- Cole Medin (209K) — Mixed-provider benchmark: Opus + Kimi
- Verdent AI — K2.6 vs Opus 4.6 vs GPT-5.4
- Artificial Analysis — Opus 4.8 vs Kimi K2.6
📖 Read This Next
- GPT-5.5 vs Kimi K2.6 — tied on Pro, separated by everything else
- Kimi K2.6 vs MiniMax M3 — the open-weight crown (0.4 pts apart)
- Claude Opus 4.8 vs MiniMax M3 — king vs open-weight challenger
- SWE-bench Pro Live Leaderboard — every model ranked