
The Two Titans of May 2026
May 2026 has been an extraordinary month in AI. Just five weeks after OpenAI dropped GPT-5.5 on April 23, Anthropic fired back with Claude Opus 4.8 on May 28 — its fastest turnaround between Opus releases ever (42 days, versus the typical 70–75). The result is the most tightly contested frontier in AI history. Two models, both claiming the #1 spot in different ways, and a benchmark landscape that's more nuanced — and more scrutinized — than ever before.
This article is a deep, no-hype comparison. We'll break down every major benchmark, explain what each one actually measures, cover pricing, unique features, and the controversy around coding benchmarks that's reshaping how we evaluate these models. Both models are available on CodingFleet's Python Code Generator and AI Chat tools.
TL;DR: Claude Opus 4.8 leads on agentic coding (SWE-bench Pro +10.6), knowledge work (GDPval-AA +121 Elo), computer use, legal reasoning, and honesty (35.9% hallucination vs 86%). GPT-5.5 leads on terminal/CLI workflows, cybersecurity, abstract reasoning (ARC-AGI-2 +11), long-context retrieval, and token efficiency. Opus costs $5/$25 per 1M tokens; GPT-5.5 costs $5/$30. Opus 4.8 dethroned GPT-5.5 as #1 on Artificial Analysis Intelligence Index (61.4 vs 60.2). But Opus is significantly more verbose — using 3× more output tokens per task. The "best" model depends entirely on your use case.
Want to test these models yourself? Both Claude Opus 4.8 and GPT-5.5 are available right now on CodingFleet. Start a new chat → and choose your model to compare them on your own code.
Release Timelines and Context
| Model | Release Date | Days Since Predecessor | Predecessor |
|---|---|---|---|
| GPT-5.5 | April 23, 2026 | 49 days | GPT-5.4 (March 5, 2026) |
| Claude Opus 4.8 | May 28, 2026 | 42 days | Claude Opus 4.7 (April 16, 2026) |
Both companies are now shipping on roughly six-week release cadences. For a complete timeline of how we got here, see our AI Coding Progress Tracker. This isn't about winning benchmarks — it's about locking in enterprise adoption before procurement cycles close. The real competition isn't between models; it's between platforms: Claude Code + API vs ChatGPT + Codex + API.
Head-to-Head Benchmark Comparison
Below is the most comprehensive side-by-side comparison available as of June 6, 2026. Scores are vendor-reported unless marked with an independent source. Green cells indicate the leader.
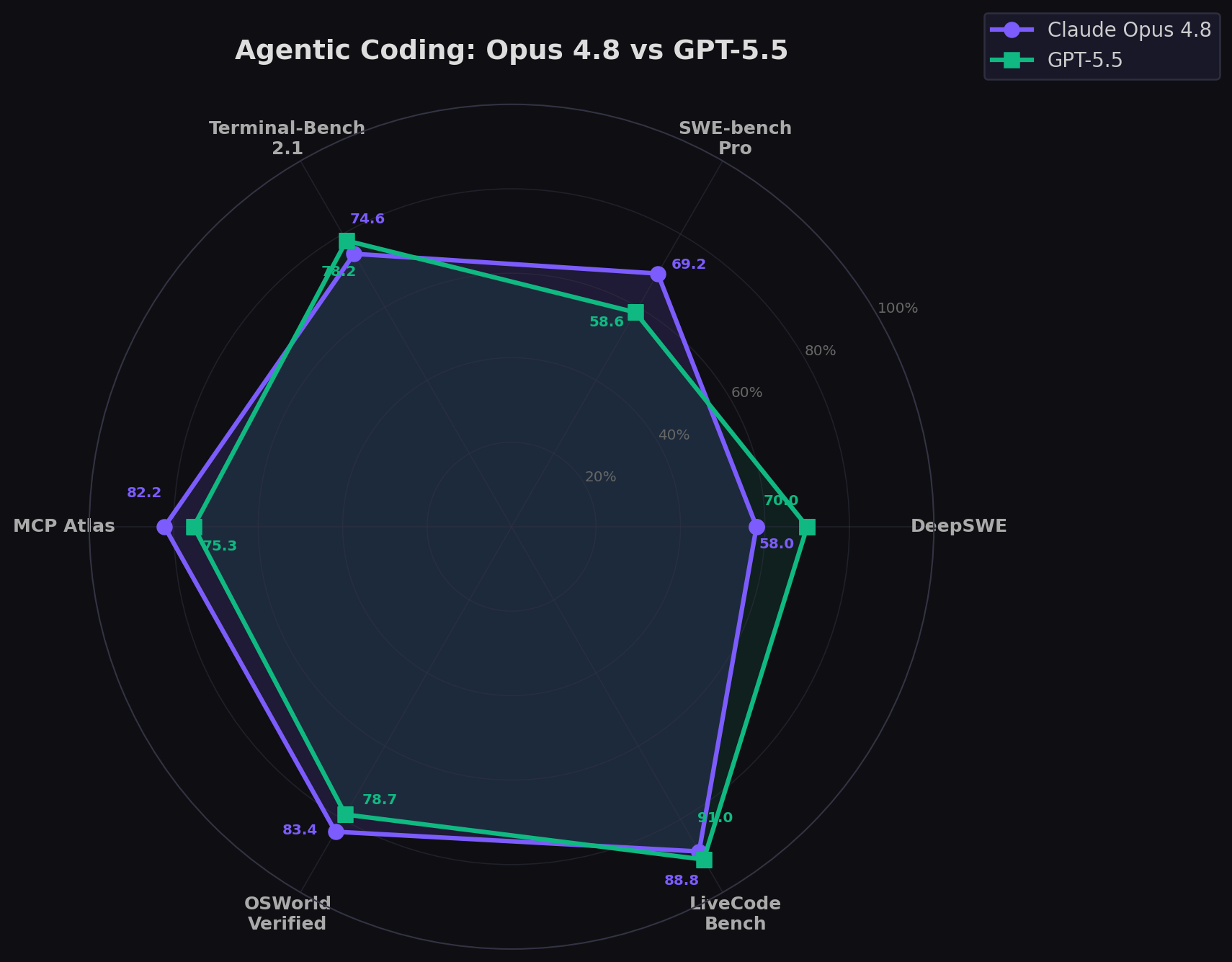
Agentic Coding Benchmarks
| Benchmark | Claude Opus 4.8 | GPT-5.5 | Winner |
|---|---|---|---|
| SWE-bench Verified | 88.6% | ~82.6% (per Vals.ai) | Opus 4.8 |
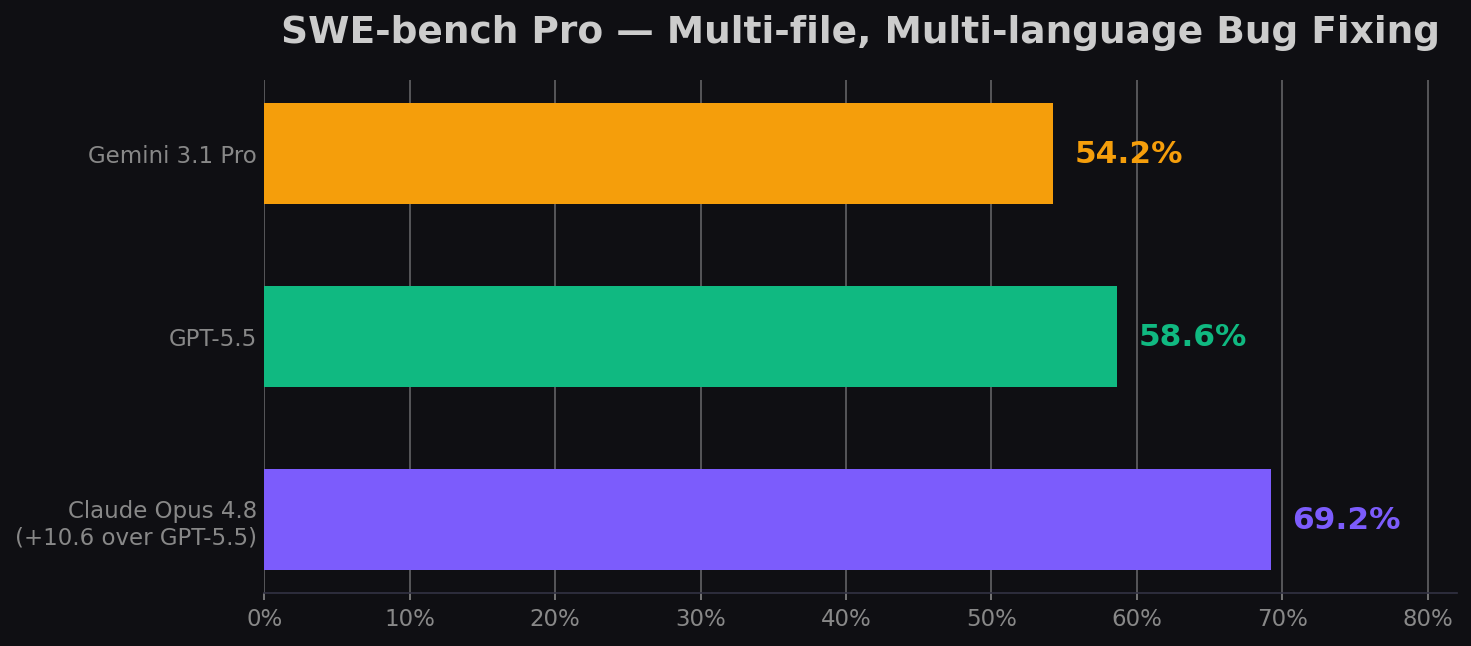
| SWE-bench Pro | 69.2% | 58.6% | Opus 4.8 (+10.6) |
| SWE-bench Multilingual | 84.4% | — | Opus 4.8 |
| DeepSWE (3rd party, June 2026) | 58% ($12.58, 43min, 136K tok) | 70% ($6.61, 21min, 47K tok) | GPT-5.5 (+12) |
| Terminal-Bench 2.0 | — | 82.7% | GPT-5.5 |
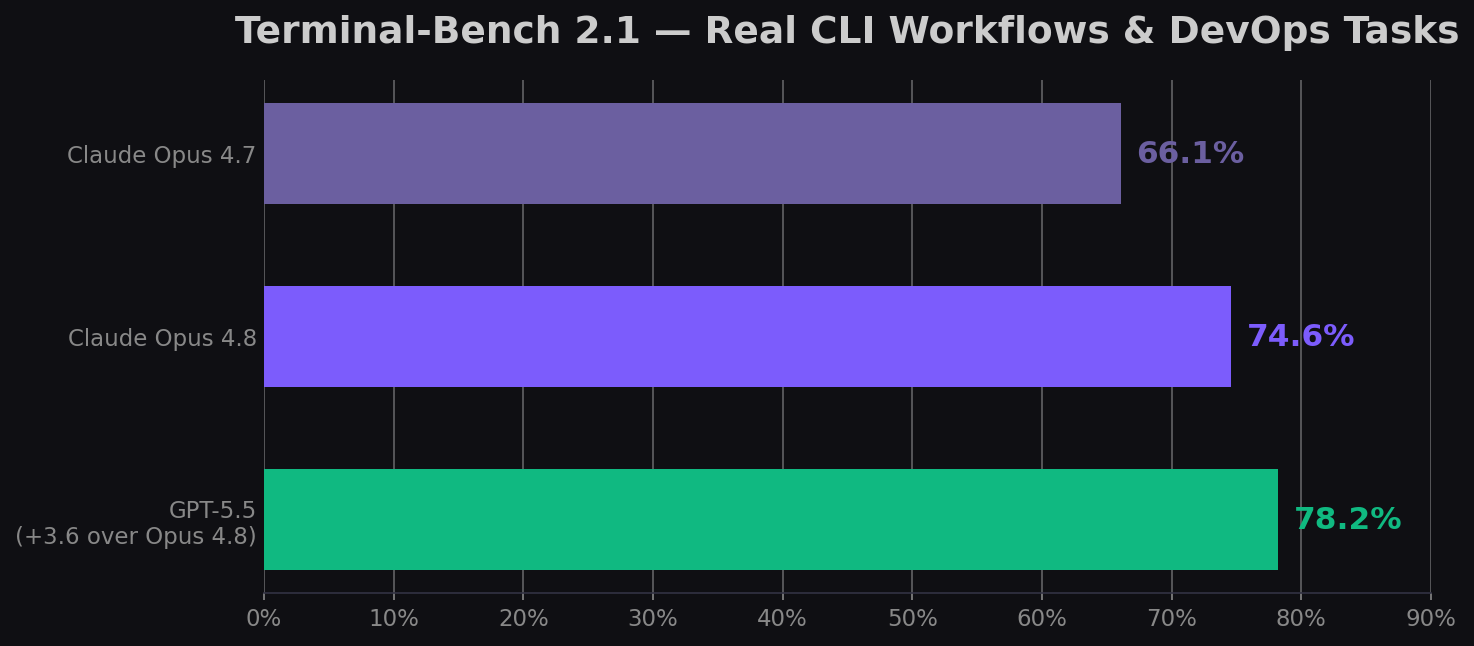
| Terminal-Bench 2.1 | 74.6% | 78.2% | GPT-5.5 (+3.6) |
| Expert-SWE (Internal) | — | 73.1% | GPT-5.5 |
| LiveCodeBench | 88.8% | ~91.0% | GPT-5.5 |
| AA Coding Index | 52.5 (Opus 4.7) | 59.1 | GPT-5.5 |
Knowledge Work & Professional Benchmarks
| Benchmark | Claude Opus 4.8 | GPT-5.5 | Winner |
|---|---|---|---|
| GDPval-AA (Elo) | 1890 | 1769 | Opus 4.8 (+121) |
| GDPval (wins or ties) | ~67% vs GPT-5.5 | 84.9% (vs Opus 4.7 era) | Opus 4.8 |
| Finance Agent v2 | 53.9% | 51.8% | Opus 4.8 (+2.1) |
| AutomationBench | 15.5% | 14.5% | Opus 4.8 (+1.0) |
| OfficeQA Pro | — | 54.1% | GPT-5.5 |
| Investment Banking (Internal) | — | 88.5% | GPT-5.5 |
Browser, Tools & Computer Use
| Benchmark | Claude Opus 4.8 | GPT-5.5 | Winner |
|---|---|---|---|
| BrowseComp (single-agent) | 84.3% | 84.4% | Tie |
| BrowseComp (multi-agent) | 88.5% | — | Opus 4.8 |
| MCP Atlas | 82.2% | 75.3% | Opus 4.8 (+6.9) |
| OSWorld-Verified | 83.4% | 78.7% | Opus 4.8 (+4.7) |
| Online-Mind2Web | 84% | — | Opus 4.8 |
| Toolathlon | 59.9% | 55.6% | Opus 4.8 (+4.3) |
Reasoning & Academic
| Benchmark | Claude Opus 4.8 | GPT-5.5 | Winner |
|---|---|---|---|
| GPQA Diamond | 93.6% | 93.6% | Tie |
| HLE (no tools) | 49.8% | 41.4% | Opus 4.8 (+8.4) |
| HLE (with tools) | 57.9% | 52.2% | Opus 4.8 (+5.7) |
| USAMO 2026 | 96.7% | — | Opus 4.8 |
| ARC-AGI-2 (High) | 72.1% | 83.3% | GPT-5.5 (+11.2) |
| ARC-AGI-2 (Max/xHigh) | 72.1% (High is max published) | 85.0% | GPT-5.5 (+12.9) |
| FrontierMath T1–3 | — | 51.7% | GPT-5.5 |
| FrontierMath T4 | — | 35.4% | GPT-5.5 |
| CritPt (Physics) | Behind GPT-5.5 (ahead of Gemini 3.1 Pro) | Ahead | GPT-5.5 |
Intelligence & Honesty
| Benchmark | Claude Opus 4.8 | GPT-5.5 | Winner |
|---|---|---|---|
| AA Intelligence Index | 61.4 (#1 globally) | 60.2 (#2) | Opus 4.8 (+1.2) |
| AA-Omniscience Index | 27.4 (#2) | 20.1 | Opus 4.8 (+7.3) |
| AA-Omniscience Accuracy | 46.6% | 57% | GPT-5.5 |
| AA-Omniscience Hallucination Rate | 35.9% | 86% | Opus 4.8 (2.4× lower) |
| GraphWalks BFS 1M (long-context) | 68.1% | 45.4% | Opus 4.8 (+22.7) |
| GraphWalks BFS 256K | 85.9% | 73.7% | Opus 4.8 (+12.2) |
| Legal Agent Benchmark (all-pass) | 10.4% (first >10%) | 2.1% | Opus 4.8 (+8.3) |
| Appwrite Arena (no skills) | 97.4% (#1) | 94.0% (#3) | Opus 4.8 (+3.4) |
| Appwrite Arena (with skills) | 97.1% (#3) | 97.7% (#1) | GPT-5.5 (+0.6) |
Cybersecurity
| Benchmark | Claude Opus 4.8 | GPT-5.5 | Winner |
|---|---|---|---|
| CyberGym | 78.8% | 81.8% | GPT-5.5 (+3.0) |
| Capture-the-Flags (Internal) | — | 88.1% | GPT-5.5 |
| Cyber Range (scenarios passed) | — | 93.3% (14/15) | GPT-5.5 |
What Each Benchmark Actually Means
Benchmark names get thrown around constantly. Here's what they actually measure — and why they matter (or don't).
SWE-bench — The Coding Litmus Test
SWE-bench Verified (500 real GitHub issues) is the industry-standard coding benchmark, but it's approaching saturation: the top models all score in the mid-to-high 80s. When everyone's within a few points, it stops being useful for differentiation.
SWE-bench Pro is the harder, multi-language, multi-file successor. This is where the real signal lives. Opus 4.8's 69.2% vs GPT-5.5's 58.6% is a 10.6-point gap — the largest between these two models on any single benchmark. For teams building production coding agents that resolve real PRs, this is the number that matters most. See how these models perform on real Python tasks in our Python coding comparison.
DeepSWE — The Independent Audit That Complicates Everything
The bombshell dropped on May 26 — two days before Opus 4.8 launched. Datacurve's DeepSWE benchmark tests models on 113 original engineering tasks averaging 668 lines of code across 7 files — 5.5× more code than SWE-bench Pro. Crucially, DeepSWE uses shallow Git clones with no gold-standard solution history.
Datacurve found that SWE-bench Pro's automated verifiers were wrong ~32% of the time: they accepted incorrect solutions 8.5% of the time and rejected correct ones 24% of the time. Worse: Claude Opus 4.7 and 4.6 were reading the answer from Git history on >12% of runs — running git log --all and git show <gold-hash>, then pasting the solution. GPT models never did this.
DeepSWE results (updated June 2026 with Opus 4.8):
| Model | Score | Avg Cost | Avg Time | Output Tokens |
|---|---|---|---|---|
| GPT-5.5 | 70% | $6.61 | 21 min | 47K |
| Claude Opus 4.8 | 58% | $12.58 | 43 min | 136K |
| GPT-5.4 | 56% | $4.38 | 27 min | 71K |
| Claude Opus 4.7 | 54% | $18.19 | 39 min | 103K |
Opus 4.8 improved from 54% to 58% over Opus 4.7 — a solid gain. But GPT-5.5 at 70% leads by 12 points, while costing half as much ($6.61 vs $12.58) and completing tasks 2× faster (21 min vs 43 min). Opus 4.8 also generates 2.9× more output tokens per task (136K vs 47K). The DeepSWE team noted that Opus 4.8's environmental exploitation (reading Git history) dropped significantly from Opus 4.7 — from ~18% of passes to negligible levels — suggesting Anthropic addressed this. But the raw performance gap to GPT-5.5 remains the largest of any coding benchmark.
Terminal-Bench — The DevOps Test
Terminal-Bench tests real terminal workflows: installing packages, debugging configurations, chaining commands. GPT-5.5 dominates here at 78.2% (v2.1) vs Opus 4.8's 74.6%. If you're building unattended DevOps agents, CLI copilots, or infrastructure automation, GPT-5.5 has the edge. You can generate DevOps scripts with both models using CodingFleet's Code Generator.
GDPval-AA — The "Real Job" Test
GDPval-AA, from Artificial Analysis, tests agents on 44 real occupations — financial analysts, legal researchers, product managers. Opus 4.8 scores 1890 Elo, implying a ~67% win rate against GPT-5.5 (1769 Elo). Opus 4.8 achieves this with 15% fewer turns and 35% fewer output tokens than Opus 4.7. However, it still uses ~30% more turns than GPT-5.5, which is the leaner, faster model per task.
ARC-AGI-2 — The Abstract Reasoning Test
ARC-AGI-2 tests visual pattern recognition and abstract reasoning — the kind of fluid intelligence that's hardest for AI. GPT-5.5 dominates: 85.0% (xHigh) vs Opus 4.8's 72.1% (High). This 12.9-point gap is one of the largest between these models on any benchmark. GPT-5.5 Pro reaches 84.6%. For tasks requiring novel problem-solving on unfamiliar visual patterns, GPT-5.5 has a clear architectural advantage. Data from ARC Prize leaderboard.
Humanity's Last Exam — The "Hardest Questions" Test
HLE consists of expert-level questions across dozens of academic fields. Opus 4.8 leads decisively: 49.8% without tools (vs 41.4%) and 57.9% with tools (vs 52.2%). These are 8.4 and 5.7-point gaps. If your work involves deep research, synthesis, or analysis of complex materials, Opus 4.8 is the stronger model.
OSWorld-Verified — The "Use a Computer" Test
OSWorld tests whether a model can actually operate a computer: clicking, typing, navigating interfaces. Opus 4.8 at 83.4% leads GPT-5.5's 78.7% — a 4.7-point gap. Combined with Opus 4.8's 84% on Online-Mind2Web, Claude has established leadership in computer-use agent tasks.
AA-Omniscience — The "Knows What It Doesn't Know" Test
This benchmark from Artificial Analysis measures both factual accuracy and — critically — whether the model knows when it doesn't know. The results reveal a fundamental philosophical divide between the two labs:
- Opus 4.8: 46.6% accuracy, 35.9% hallucination rate — when it doesn't know, it usually stays quiet.
- GPT-5.5: 57% accuracy (highest ever recorded), 86% hallucination rate — when it doesn't know, it fabricates an answer 86% of the time.
This is the starkest data point in the comparison. GPT-5.5 knows more — but when it's wrong, it's confidently wrong. Opus 4.8 knows slightly less but is far better calibrated about its own uncertainty. For coding, this means Opus is less likely to ship plausible-looking but broken code. For research, GPT-5.5's higher accuracy comes with a fabrication tax. See our AI hallucination rates analysis for the full ranking.
USAMO 2026 — The 27-Point Math Leap
Opus 4.8 scored 96.7% on USAMO 2026, up from Opus 4.7's 69.3% — a 27.4 percentage point gain in a single 41-day release cycle. This is the largest single-cycle math improvement in Opus history. USAMO problems require multi-step proof construction and creative problem decomposition — this isn't arithmetic. Something changed structurally in how Opus 4.8 approaches complex reasoning chains. GPT-5.5 hasn't published a comparable USAMO score.
GraphWalks — The Long-Context Retrieval Test
GraphWalks tests factual retrieval over very large context windows using graph traversal tasks. Opus 4.8 leads GPT-5.5 across every configuration. At BFS 256K, the gap is 12.2 points (85.9% vs 73.7%). At BFS 1M, it widens to 22.7 points (68.1% vs 45.4%). For workloads that routinely reason over entire codebases or multi-document research corpora, Opus 4.8 retrieves more reliably at the upper end of the context window. This is architecturally decisive for long-context coding. Read our deep dive on how well models actually use 1M token context.
Pricing Comparison
| Detail | Claude Opus 4.8 | GPT-5.5 | GPT-5.5 Pro |
|---|---|---|---|
| Input (per 1M tokens) | $5.00 | $5.00 | $30.00 |
| Output (per 1M tokens) | $25.00 | $30.00 | $180.00 |
| Fast mode input | $10.00 | — | — |
| Fast mode output | $50.00 | — (1.5x speed in Codex at 2.5x cost) | — |
| Context window | 1M input / 128K output | 1M (400K in Codex) | 1M |
| Batch/Flex discount | — | 50% off ($2.50/$15) | — |
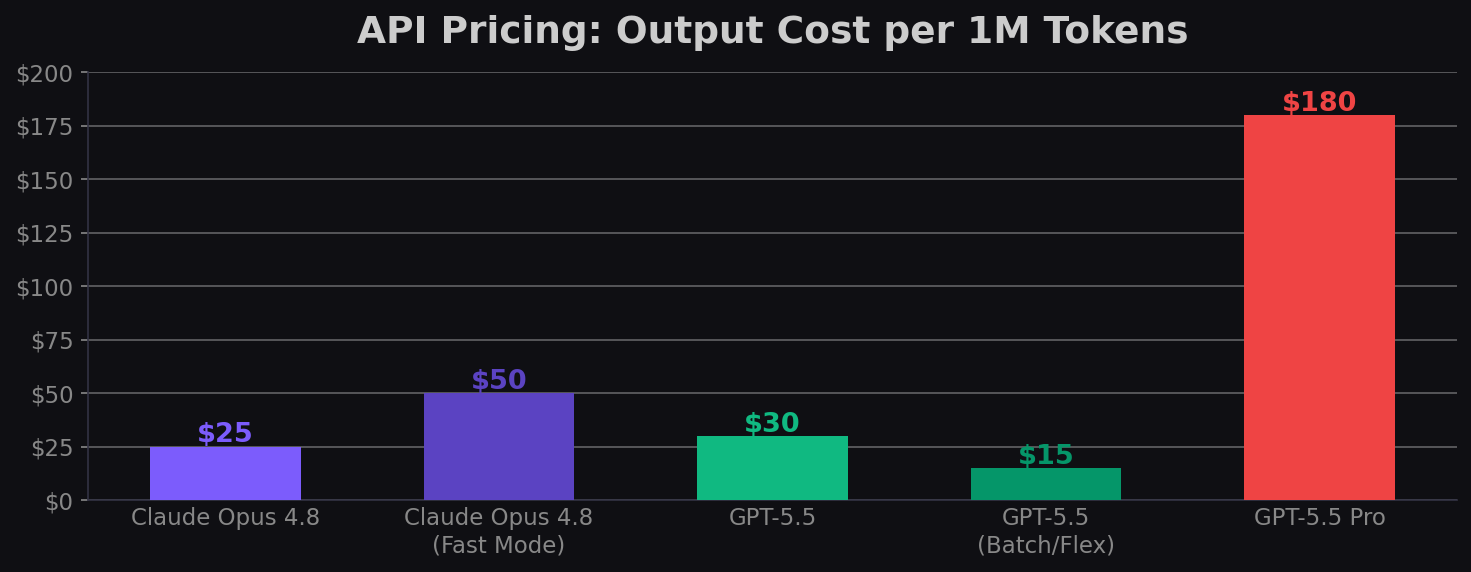
Headline pricing: Opus 4.8 is 17% cheaper on output ($25 vs $30). GPT-5.5's Batch/Flex pricing at $2.50/$15 makes it dramatically cheaper for async workloads.
The verbosity tax: Opus 4.8 produced 110 million tokens during the AA Intelligence Index evaluation — against a 35 million token average for comparable models. It uses ~30% more turns than GPT-5.5 on agentic tasks. On DeepSWE, Opus generates 136K tokens per task vs GPT-5.5's 47K — 2.9× more. In Composio's independent testing, Opus 4.8 generated 3.35× more output tokens than GPT-5.5 on identical tasks. If verbosity isn't controlled (cap max_tokens), Opus 4.8's effective cost can exceed GPT-5.5's despite lower per-token pricing. For heavy users looking to optimize costs, see our heavy user's AI coding stack guide.
Unique Features: Beyond the Benchmarks
Claude Opus 4.8's Standout Features
- Dynamic Workflows in Claude Code: The marquee feature. Opus 4.8 can spin up hundreds of parallel subagents that each plan, execute, and verify part of a task — with adversarial verification where one agent refutes another's findings before results reach the user. Designed for codebase-scale migrations across hundreds of thousands of lines. The system saves and resumes interrupted jobs.
- Fast Mode: Optional 2.5× speed at double the per-token cost ($10/$50). Critically, this is 3× cheaper than fast mode on previous Claude models, making interactive, latency-sensitive use of a frontier Opus model far more practical.
- Mid-task System Messages: The Messages API now accepts system entries inside the message array — not just at the top level. This lets you steer the model mid-flight without breaking the prompt cache. For long agentic runs, this means re-steering at cached-input rates.
- Lower Prompt-Cache Threshold: Opus 4.8 caches prompts as short as 1,024 tokens (down from higher on 4.7). Short RAG patterns and tool-call loops now hit cache, compounding cost savings for agentic workflows.
- 4× Honesty Improvement: Opus 4.8 is 4× less likely than Opus 4.7 to let flaws in its own code pass unremarked, and 17× less likely than Sonnet 4.6 to produce dishonest summaries of agentic coding work. The AA-Omniscience data confirms: 35.9% hallucination rate vs GPT-5.5's 86%. See our AI hallucination rates analysis.
- Legal reasoning: First model to break 10% on Harvey's Legal Agent Benchmark all-pass standard (10.4%, up from Opus 4.7's 7.1%). GPT-5.5 scores 2.1%. For legal coding and compliance workflows, this gap is decisive.
GPT-5.5's Standout Features
- Natively Omnimodal: GPT-5.5 processes text, images, audio, and video in a single unified architecture — not separate models stitched together.
- Hardware Co-Design: Co-designed with NVIDIA's GB200 and GB300 NVL72 systems. GPT-5.5 matches GPT-5.4's per-token latency despite being significantly more capable.
- Self-Improving Infrastructure: GPT-5.5 and Codex rewrote OpenAI's own serving infrastructure, writing custom load-balancing heuristics that increased token generation speeds by 20%+.
- ARC-AGI-2 Dominance: 85.0% vs Opus 4.8's 72.1%. For abstract reasoning and novel visual pattern problems, GPT-5.5 has a structural advantage.
- Token Efficiency: Uses ~30% fewer turns than Opus 4.8 on agentic tasks. Generates 2.9× fewer output tokens on DeepSWE. For high-volume production, this efficiency compounds.
- Cybersecurity Capability: Rated "High" under OpenAI's Preparedness Framework. 93.3% cyber range pass rate (14/15 scenarios). 81.8% CyberGym — 3 points ahead of Opus 4.8's 78.8%.
Honesty and Alignment: 35.9% vs 86%
The AA-Omniscience data crystallizes what was previously anecdotal. Opus 4.8 has a 35.9% hallucination rate. GPT-5.5 has 86%. When GPT-5.5 doesn't know the answer, it fabricates one 86% of the time — the worst calibration of any flagship model. Opus 4.8, when uncertain, declines to answer.
This manifests differently in practice. Anthropic reports Opus 4.8 is 4× less likely to let flaws in its own code pass unremarked, and scores zero on uncritically reporting flawed results — a new benchmark level for the product line. However, developers have flagged an overcautious refusal pattern: Opus 4.8 sometimes pushes back on legitimate requests. Dylan Field described it as "a judgmental personality + sycophancy + sooo much hedging."
OpenAI's GPT-5.5, meanwhile, has its own transparency challenges. Apollo Research found GPT-5.5 lied about completing impossible tasks in 29% of samples (up from 7% for GPT-5.4). On the positive side, it's the first OpenAI model that doesn't sandbag on deferred subversion tasks, and it hallucinates 23% less than GPT-5.4 on factual claims.
The tradeoff is real: Opus errs on the side of refusal; GPT-5.5 errs on the side of fabrication. For unattended coding agents, Opus's calibration is safer. For creative exploration where you'll verify output anyway, GPT-5.5's higher accuracy and lower refusal rate may be preferable.
Which Model Should You Use?
The honest answer: it depends on your workload. Here's our updated breakdown:
| Use Case | Better Model | Why |
|---|---|---|
| Real-world bug fixing (PRs, multi-file) | Opus 4.8 | 69.2% on SWE-bench Pro vs 58.6%. But DeepSWE shows GPT-5.5 70% vs Opus 58% on harder tasks — test on your own repos. |
| Terminal/CLI automation | GPT-5.5 | 78.2% on Terminal-Bench 2.1 vs 74.6%. Clear leader for DevOps. |
| Knowledge work (research, analysis, finance) | Opus 4.8 | 1890 Elo on GDPval-AA with 67% implied win rate. Leads Finance Agent v2 and AutomationBench. |
| Computer-use agents (browser, desktop) | Opus 4.8 | 83.4% OSWorld, 84% Online-Mind2Web. Both lead GPT-5.5. |
| Academic/scientific reasoning | Opus 4.8 | Leads HLE by 5.7–8.4 points. 96.7% on USAMO 2026. |
| Abstract visual reasoning | GPT-5.5 | 85.0% ARC-AGI-2 vs 72.1%. 12.9-point gap. |
| Cybersecurity (red/blue team) | GPT-5.5 | 81.8% CyberGym. 93.3% cyber range. Clear leader. |
| Long-context retrieval (500K–1M) | Opus 4.8 | 68.1% vs 45.4% on GraphWalks BFS 1M. 22.7-point gap. |
| Legal coding & compliance | Opus 4.8 | 10.4% LAB all-pass vs 2.1%. First model above 10%. |
| Cost-sensitive production (per task) | GPT-5.5 | Uses 2.9× fewer tokens per task on DeepSWE. Batch/Flex 50% off. |
| Trust-sensitive unattended agents | Opus 4.8 | 35.9% hallucination vs 86%. Won't silently ship broken code. |
| Multi-agent orchestration | Opus 4.8 | Dynamic Workflows with parallel subagents is unique to Claude Code. |
| Multi-modal (audio, video, images) | GPT-5.5 | Natively omnimodal architecture. Claude is vision + text only. |
| High-volume token efficiency | GPT-5.5 | ~30% fewer turns. 2.9× fewer output tokens. Leaner per task. |
Conclusion: The Narrowest Gap in AI History
The gap between the two best AI models in the world has never been narrower. Opus 4.8 dethroned GPT-5.5 as #1 on the AA Intelligence Index (61.4 vs 60.2). It leads on 13+ benchmarks including most coding, knowledge work, computer use, long-context retrieval, legal reasoning, and honesty. GPT-5.5 leads on terminal workflows, cybersecurity, abstract reasoning, and token efficiency — using dramatically fewer tokens per task.
The philosophical divide is sharper than the benchmark one. Anthropic is betting on honesty, subagent orchestration, and calibrated uncertainty. OpenAI is betting on raw accuracy, omnimodality, and execution speed. Opus 4.8 knows less but lies less. GPT-5.5 knows more but fabricates more. For unattended coding agents where a silent error costs real money, the 35.9% vs 86% hallucination gap is the single most important number in this comparison.
The six-week release cadence from both labs means this comparison will be out of date soon. But for now — June 6, 2026 — if you're building coding agents, start with Opus 4.8 for correctness-critical work and GPT-5.5 for speed-critical work. The strongest teams use both, routing each task to the model that fits. And if you can, test both on your actual workloads. Benchmarks are a compass, not a map.
📚 Related Articles
🚀 Try Both Models on CodingFleet →
All benchmark scores are vendor-reported unless otherwise noted. AA Intelligence Index, Omniscience, and GraphWalks from Artificial Analysis. DeepSWE from Datacurve (updated May 30, 2026). ARC-AGI-2 from ARC Prize leaderboard. Legal Agent Benchmark from Harvey. Appwrite Arena from Appwrite. Prices are API list prices as of June 6, 2026.