
📊 TL;DR — Key Findings
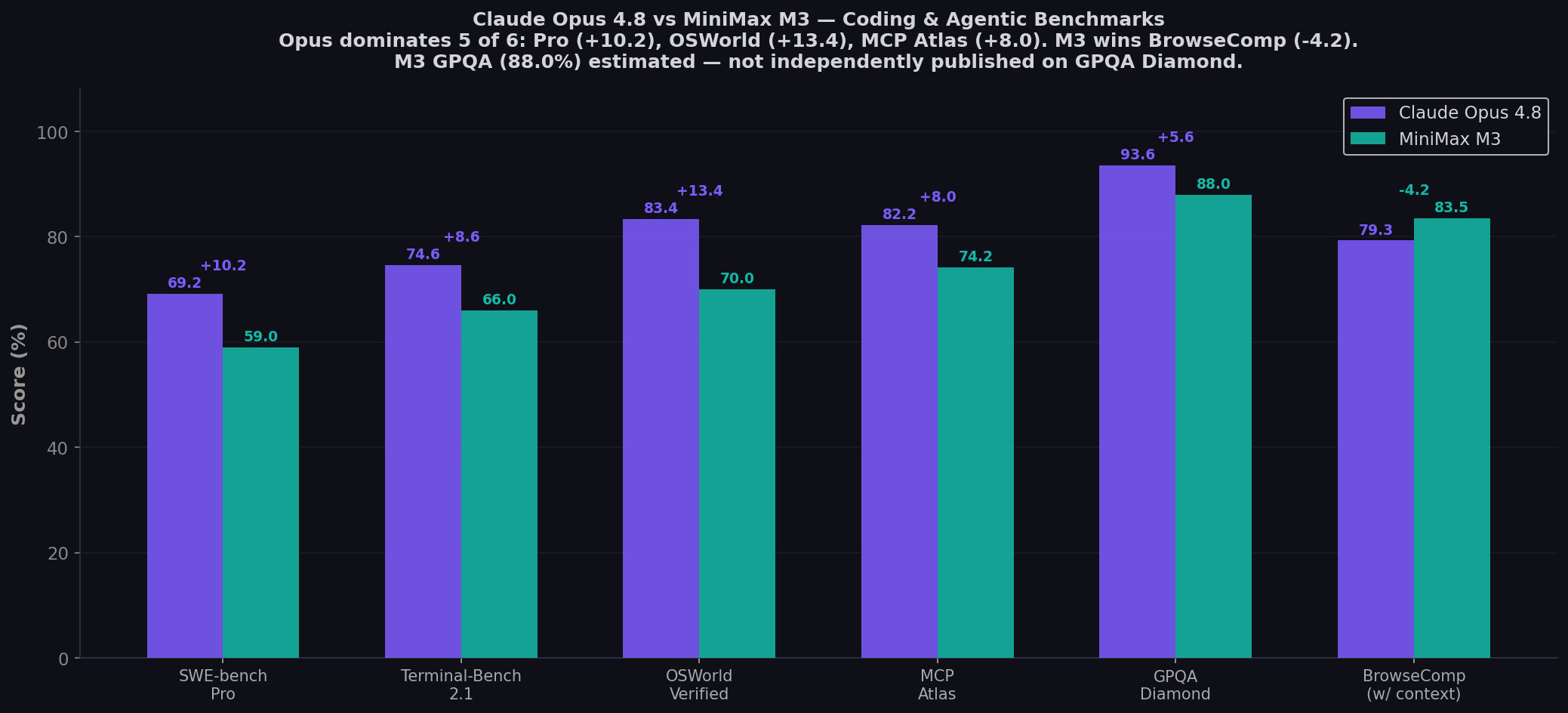
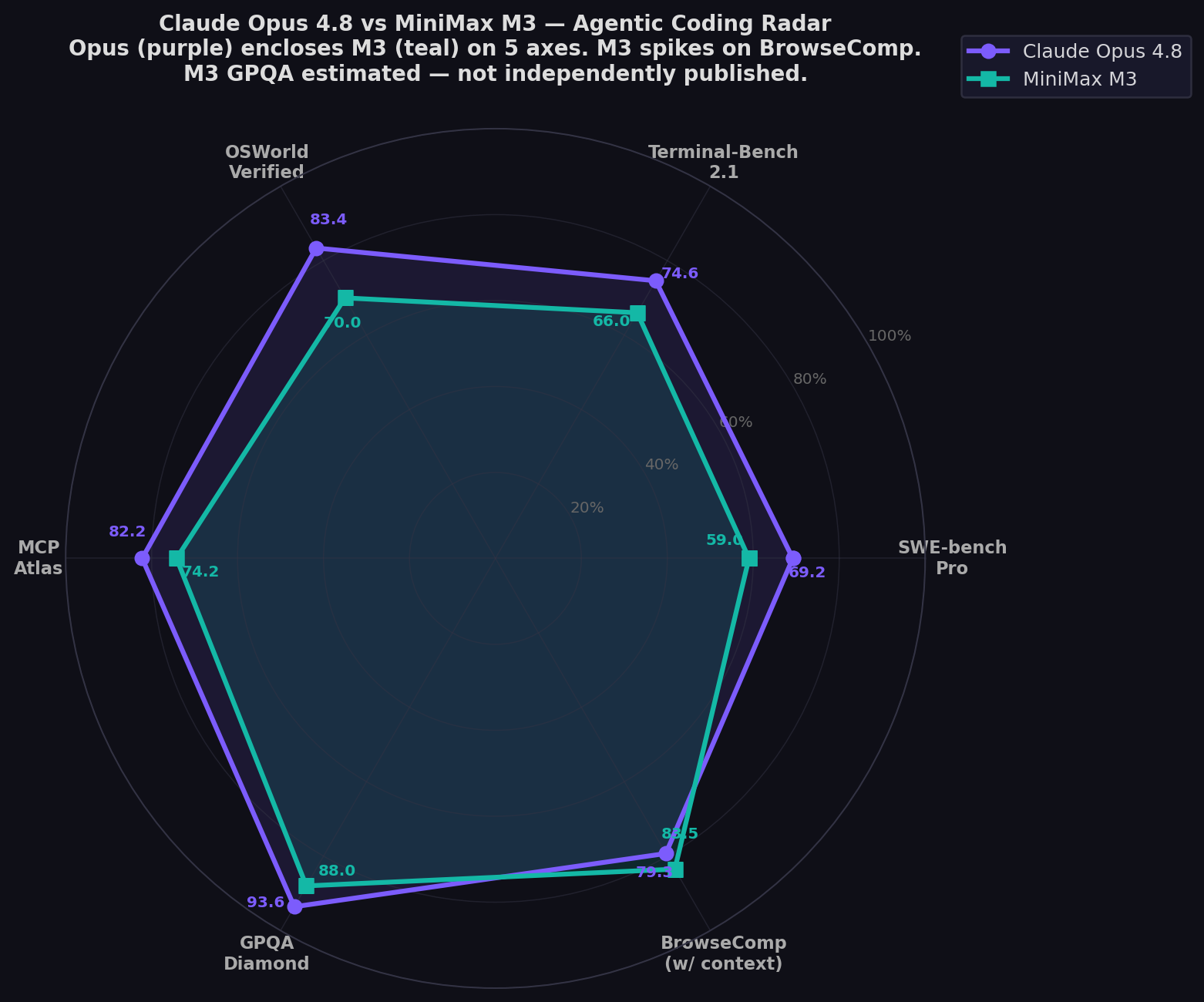
- Opus 4.8 dominates 5 of 6 shared benchmarks: Pro (+10.2), Terminal-Bench (+8.6), OSWorld (+13.4), MCP Atlas (+8.0), GPQA (+5.6). M3 wins BrowseComp (-4.2).
- 21× price gap: Opus $25/1M output vs M3 $1.20/1M (promo; $2.40 standard). At 100M tokens/month: Opus $2,500 vs M3 $120-$240.
- M3 is open-weight + multimodal: Weights on HuggingFace. Native video, image, and desktop computer operation. Opus is proprietary and text+image only.
- Opus is the safer coding pick: +10.2 Pro, +13.4 OSWorld — for unattended agentic work where correctness matters, the margin is decisive.
- Both share 1M context: Opus uses standard full attention. M3 uses MSA (MiniMax Sparse Attention) — 9.7× prefill, 15.6× decode speedup at 1M tokens.
Try both models side-by-side on your own code at CodingFleet →
Benchmark Comparison
| Benchmark | Claude Opus 4.8 | MiniMax M3 | Winner |
|---|---|---|---|
| SWE-bench Pro ★ | 69.2% | 59.0% | Opus (+10.2) |
| SWE-bench Verified ⚠️ | 88.6% | 80.5% | Opus (+8.1) |
| Terminal-Bench 2.1 | 74.6% | 66.0% | Opus (+8.6) |
| OSWorld-Verified | 83.4% | 70.0% | Opus (+13.4) |
| MCP Atlas | 82.2% | 74.2% | Opus (+8.0) |
| BrowseComp (w/ context) | 79.3% | 83.5% | M3 (+4.2) |
| GPQA Diamond | 93.6% | ~88.0%* | Opus (+5.6) |
| GDPval-AA (Elo) | 1,890 | — | Opus — M3 not published |
| HLE (with tools) | 57.9% | — | Opus — M3 not published |
| AA Intelligence Index | 61.4 (#1) | 55 | Opus (+6.4) |
| AA-Omniscience (hallucination) | 35.9% | — | Opus — M3 not evaluated |
| Output Price /1M tok | $25.00 | $1.20 (promo) / $2.40 | M3 (10-21× cheaper) |
| Input Modalities | Text, Image | Text, Image, Video | M3 |
| Weights Available | No | Yes — HuggingFace | M3 |
Sources: Vellum — Opus 4.8 benchmarks | Anthropic Opus 4.8 system card | VentureBeat — M3 vs Opus 4.8 comparison | MiniMax M3 launch blog | Lushbinary M3 guide | Artificial Analysis — Opus 4.8 analysis. *M3 GPQA ~88.0% estimated from available comparisons — not independently published on GPQA Diamond. ⚠️ SWE-bench Verified deprecated by OpenAI Feb 2026. All scores vendor-reported.
SWE-bench Pro: The 10.2-Point Gap That Defines the Comparison
The single most important number in this comparison. Opus 4.8 at 69.2% vs M3 at 59.0% on SWE-bench Pro — the benchmark for real-world GitHub issue resolution. This 10.2-point gap represents the difference between solving roughly 7 out of 10 hard multi-file bugs versus 6 out of 10. In practice, that translates to fewer unresolved PRs, fewer agent loops that fail silently, and fewer production issues that trace back to AI-generated code. VentureBeat's analysis captures the dynamic: "closed-source systems like Opus 4.8 maintain absolute margin leads on hyper-complex reasoning vectors, yet M3 delivers a highly capable baseline of local, tier-one automated operation without the compounding premium of closed-door API subscription fees."
OSWorld: The 13.4-Point Computer Use Chasm
The widest gap on any shared benchmark. Opus 4.8 at 83.4% vs M3 at 70.0% on OSWorld-Verified — the benchmark for real-world GUI task completion (editing documents, browsing the web, managing files on a live Ubuntu VM). This is Opus's strongest domain: only Fable 5 (85.0%) scored higher. For developers building computer-use agents that need to navigate GUIs, fill forms, and manipulate desktop applications, Opus 4.8's 13.4-point lead is decisive. M3's desktop computer operation feature is architecturally interesting — but the benchmark gap suggests the capability is still maturing.
BrowseComp: M3's Signature Win
The single benchmark where M3 beats Opus 4.8 — and not by a narrow margin. M3 at 83.5% vs Opus 4.8 at 79.3% on BrowseComp, the benchmark for autonomous web browsing and information retrieval. MiniMax's launch blog positions this as a core differentiator: "surpasses GPT-5.5 and Gemini 3.1 Pro on coding and edges past Claude Opus 4.7 on autonomous browsing." For web-connected agentic workflows — search, navigate, synthesize — M3 provides capabilities that Opus doesn't match. This is the one axis where the cheaper, open-weight model genuinely leads.
Architecture & Ecosystem
| Feature | Claude Opus 4.8 | MiniMax M3 |
|---|---|---|
| Release Date | May 28, 2026 | June 1, 2026 |
| Developer | Anthropic | MiniMax |
| Model Class | Proprietary Frontier | Open-Weight Frontier |
| Context Window | 1,000,000 tokens | 1,000,000 tokens |
| Attention Mechanism | Standard Full Attention | MSA (9.7× prefill, 15.6× decode at 1M) |
| Input Modalities | Text, Image | Text, Image, Video |
| Weights Available | No | Yes — HuggingFace (Modified MIT) |
| API Compatibility | Native Claude Code, MCP, broad SDK | MiniMax Code, REST API |
| Desktop Operation | Computer Use (via API) | Native desktop computer operation |
| AA Intelligence Index | 61.4 (#1 globally pre-Fable 5) | 55 |
| AA-Omniscience | 27.4 (35.9% hallucination) | — (not evaluated) |
| Self-Hosting | Not possible | Yes — open-weight, single GPU feasible |
Why Opus 4.8 Wins: The Reliability Premium
Claude Opus 4.8 is the most capable non-Mythos coding model Anthropic has ever shipped. The Vellum analysis notes that "the harder the variant, the bigger the gap" — Opus 4.8's advantage over competitors widens as task complexity increases. On SWE-bench Pro (+10.2 vs M3), Terminal-Bench 2.1 (+8.6), and OSWorld-Verified (+13.4), the margins are not marginal — they represent fundamentally different reliability tiers. The AA-Omniscience hallucination rate of 35.9% is the lowest among all frontier models — for agentic coding where a single hallucinated API or import can break an entire workflow, this reliability premium compounds across thousands of agent steps. Opus 4.8's native Claude Code integration and MCP ecosystem provide infrastructure maturity that M3's younger ecosystem can't match.
Why M3 Wins: The Freedom Premium
MiniMax M3 is not competing on raw benchmark dominance — it's competing on the axis of developer freedom. At $1.20/1M output (promo pricing) — 21× cheaper than Opus 4.8 — M3 makes high-volume AI coding affordable for individual developers, startups, and teams that can't justify $2,500/month token bills. The MSA sparse attention architecture gives M3 a structural cost advantage: 9.7× prefill speedup and 15.6× decode speedup at 1M tokens — meaning M3 processes long contexts at a fraction of the compute cost of full-attention models like Opus. The open-weight release on HuggingFace under a Modified MIT license means full self-hosting, fine-tuning, and air-gapped deployment. And native video/image input + desktop computer operation make M3 the more broadly capable model — even if it's not the more deeply capable one on pure coding.
Pricing: 21× Economics
| Pricing Tier | Claude Opus 4.8 | MiniMax M3 |
|---|---|---|
| Input /1M tok | $5.00 | $0.30 (promo) / $0.60 (standard) |
| Output /1M tok | $25.00 | $1.20 (promo) / $2.40 (standard) |
| Cached Input /1M tok | $0.50 | $0.03 (promo) |
| Batch/Flex Discount | 50% off | Not published |
| Self-Hosting Cost | Not possible | Open-weight — run locally |
| 100M output tokens/month | $2,500 | $120-$240 |
Sources: Anthropic API pricing | MiniMax M3 launch blog | Fireworks M3 pricing. M3 promo pricing was announced at launch — standard pricing may differ post-promo period.
Which Model Should You Use?
| Use Case | Winner | Why |
|---|---|---|
| Multi-file bug fixing | Opus ✅ | +10.2 SWE-bench Pro — the most reliable coding model below Mythos-class |
| Terminal / CLI / DevOps | Opus ✅ | +8.6 Terminal-Bench 2.1 — cleaner, safer terminal automation |
| Computer use / GUI | Opus ✅ | +13.4 OSWorld — widest gap on any benchmark |
| Tool orchestration (MCP) | Opus ✅ | +8.0 MCP Atlas, native MCP ecosystem, Claude Code integration |
| Web browsing agents | M3 ✅ | 83.5% BrowseComp — -4.2 vs Opus. Autonomous browsing leader |
| Video/image coding tasks | M3 ✅ | Native video input. Opus is text+image only |
| High-volume / budget | M3 ✅ | 21× cheaper. $120-$240/mo vs $2,500/mo at 100M output |
| Self-hosting / air-gapped | M3 ✅ | Open-weight on HuggingFace. Opus is proprietary only |
| Production agentic coding | Opus ✅ | 35.9% hallucination rate — lowest among frontiers. Trust matters |
| Long-context at scale | M3 ✅ | MSA: 15.6× decode speedup at 1M tokens. Cheaper to run long contexts |
Conclusion: The King Keeps His Crown — But the Court Is Shrinking
Claude Opus 4.8 is the better coding model — full stop. It leads on every shared benchmark except BrowseComp, with margins of 8-13 points on the agentic coding tests that matter most. The 35.9% hallucination rate, native Claude Code integration, and MCP ecosystem maturity make it the safer choice for production coding agents where correctness matters more than cost.
But MiniMax M3 is the more interesting model — 21× cheaper, open-weight, natively multimodal (video + desktop operation), and architecturally innovative (MSA sparse attention). It beats Opus 4.8 on BrowseComp and represents the direction the open-weight ecosystem is heading: models that are good enough to replace proprietary alternatives for 80% of use cases at 5% of the cost.
The VentureBeat verdict captures the strategic reality: "M3 delivers a highly capable baseline of local, tier-one automated operation without the compounding premium of closed-door API subscription fees. Closed-source systems like Opus 4.8 maintain absolute margin leads — yet the structural trade-offs currently defining the ecosystem." For most teams, the practical answer is Opus for hard problems, M3 for volume, and both for a tiered stack that maximizes capability per dollar.
20+ LLMs available on CodingFleet. Test Claude Opus 4.8 and MiniMax M3 side-by-side on your own code.
📚 Sources & Links
- Vellum — Claude Opus 4.8 Benchmarks Explained — full system card analysis
- Anthropic — Claude Opus 4.8 System Card — official benchmark tables
- Artificial Analysis — Claude Opus 4.8 Analysis — AA Index #1, hallucination rates
- VentureBeat — MiniMax M3 vs Opus 4.8 comparison — cross-model benchmark analysis
- MiniMax — M3 Launch Blog — official benchmarks and MSA architecture overview
- Lushbinary — MiniMax M3 Developer Guide — benchmark tables and pricing
- MarkTechPost — MiniMax M3 Release — MSA architecture details
- HuggingFace — MiniMax Goes Sparse — MSA technical deep-dive (9.7×/15.6× speedup)
- Fireworks — MiniMax M3 Launch — pricing and context window details
- MorphLLM — SWE-bench Pro Leaderboard — cross-validated scores
- BenchLM — MiniMax M3 Rankings — category scores
📖 Read This Next
- MiniMax M3 vs GPT-5.5 — open-weight beats proprietary on Pro at 25× less
- Kimi K2.6 vs MiniMax M3 — the open-weight crown (0.4 pts apart)
- Claude Opus 4.8 vs GPT-5.5 — the original flagship comparison
- SWE-bench Pro Live Leaderboard — every model ranked
- AI Model Pricing Calculator — compare costs at your token volume