
Claude Opus 4.8 is the best coding model in the world — 69.2% on SWE-bench Pro, 13.8 points ahead of DeepSeek V4 Pro. It costs $25 per million output tokens. DeepSeek V4 Pro costs $0.87 — a 28.7× price gap. But the coding king doesn't win every battle: DeepSeek beats Opus on LiveCodeBench (93.5% vs 88.8%) and Terminal-Bench (67.9% vs 65.4%). Here's the complete data-driven breakdown. Test both on CodingFleet.
📊 Key Findings
- Opus 4.8 leads SWE-bench Pro by 13.8 points (69.2% vs 55.4%). The widest gap between any two frontier models. Opus correctly fixes 7 out of 10 real-world bugs. DeepSeek fixes ~5.5. On tasks touching 4+ files, the gap widens further.
- DeepSeek beats Opus on algorithmic benchmarks. 93.5% LiveCodeBench vs 88.8%. 3206 Codeforces. For algorithm implementation, competitive programming, and data structures, the $0.87 model wins — and it's MIT-licensed.
- Opus 4.8 is ~4× less likely to let flaws in its own code slip by unremarked. This honesty improvement directly impacts coding trust. The model catches its own mistakes.
- Dynamic Workflows let Opus 4.8 spawn hundreds of parallel subagents. For codebase-scale migrations across hundreds of thousands of lines, Opus plans the work, executes in parallel, and verifies before reporting. DeepSeek doesn't have a comparable orchestration layer.
Compare models on your own code at CodingFleet — 20+ LLMs, side-by-side.
Benchmark Comparison
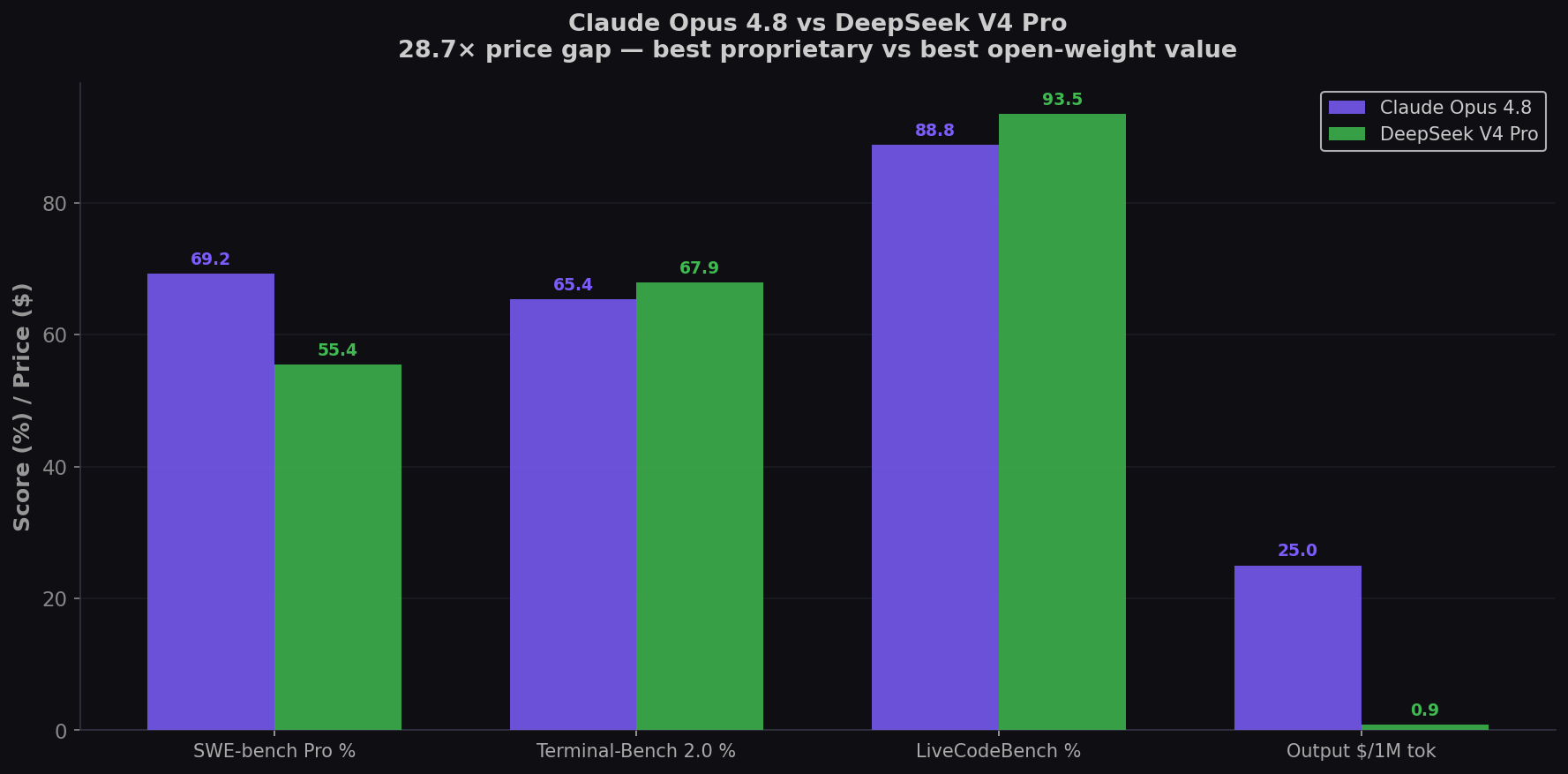
| Benchmark | Claude Opus 4.8 | DeepSeek V4 Pro | Winner |
|---|---|---|---|
| SWE-bench Pro | 69.2% | 55.4% | Opus (+13.8) |
| Terminal-Bench 2.0 | 65.4% | 67.9% | DeepSeek (+2.5) |
| LiveCodeBench | 88.8% | 93.5% | DeepSeek (+4.7) |
| GPQA Diamond | 93.6% | 90.1% | Opus (+3.5) |
| OSWorld-Verified | 83.4% | — | Opus |
| Online-Mind2Web | 84.0% | — | Opus |
| Output Price /1M tokens | $25.00 | $0.87 | DeepSeek (28.7×) |
| Context Window | 1M | 1M | Tie |
| Max Output Tokens | 128K | — | Opus |
| License | Proprietary | MIT (open-weight) | DeepSeek |
Sources: Vellum — Opus 4.8 Benchmarks; DeepSeek V4 Pro Model Card; Valletta Software Review.
Architecture & Ecosystem
Claude Opus 4.8 + Claude Code: The Agentic IDE
Opus 4.8 shipped alongside Dynamic Workflows — a research preview in Claude Code that lets Claude plan multi-step engineering work and spawn hundreds of parallel subagents in a single session. Each subagent works independently on a slice of the problem, with adversarial verification where one agent refutes another's findings. The system saves and resumes interrupted jobs. Anthropic's exemplar: a codebase-scale migration across hundreds of thousands of lines, from kickoff to merge, with the existing test suite as the bar.
Other Opus 4.8 improvements: mid-conversation system messages (update instructions mid-task without breaking prompt cache), effort control in claude.ai (choose how much compute Opus invests per response), and lower prompt-cache threshold (1,024 tokens minimum, down from higher on 4.7 — short RAG patterns now hit cache). The Fast mode runs 2.5× faster at $10/$50 per 1M — 3× cheaper than the previous Fast tier. Opus 4.8 keeps the same $5/$25 pricing as Opus 4.7 and 4.6, making it the most stable pricing trajectory among frontier models.
DeepSeek V4 Pro: Self-Hosted Freedom
DeepSeek V4 Pro's CSA+HCA attention uses 27% of the FLOPs and 10% of the KV cache of its predecessor at 1M tokens. The Muon optimizer and mHC residual connections squeeze more performance per parameter. A 1.6T MoE with 49B active per token fits on 8×H200 GPUs via vLLM or SGLang. FP8 quantization is the default for production. Self-hosting breaks even at ~15-50M tokens/month compared to API pricing.
Under MIT license, DeepSeek V4 Pro can be fine-tuned on proprietary codebases, deployed air-gapped, and never sends code to a third party. For regulated industries — defense, finance, healthcare — this is decisive. Opus 4.8 requires Anthropic's API. If data sovereignty matters, there is no comparison.
Where Each Model Excels at Coding
Claude Opus 4.8 — The Bug Fixer
The 13.8-point SWE-bench Pro gap defines this comparison. SWE-bench Pro tests real GitHub issue resolution: reading codebases, understanding bug reports, making multi-file changes, and passing test suites. Opus 4.8 correctly fixes ~7 of 10 real-world bugs. DeepSeek V4 Pro fixes ~5.5. On the hardest tasks — 4+ files, 100+ lines changed — Opus's lead widens further.
Opus 4.8 is ~4× less likely than Opus 4.7 to let flaws in its own code pass unremarked. In practice, this means fewer "looks right but secretly broken" outputs. The model catches its own edge cases. For production debugging where a missed bug costs real money, this honesty improvement compounds. The Dynamic Workflows capability means one Opus 4.8 session can orchestrate an entire migration — planning, parallel execution, adversarial verification — that would require custom tooling with any other model.
DeepSeek V4 Pro — The Algorithm Specialist
LiveCodeBench 93.5% and Codeforces 3206 are the highest of any model. For algorithm implementation, competitive programming, data structures, graph problems, and dynamic programming — DeepSeek V4 Pro is the best model available. Period. It wins on both quality and price.
The CSA+HCA attention mechanism makes 1M-token context practical. You can process entire repositories without budget anxiety. At $0.87/1M output, a full-codebase analysis that would cost $25 with Opus costs $0.87 with DeepSeek — a 28.7× difference. Multiply that across a team running dozens of codebase-scale analyses per day, and the savings are measured in hundreds of dollars daily. For high-volume use cases, MIT license + self-hosting makes DeepSeek the only economically viable option.
The 28.7× Decision: When to Pay for Opus
If you're fixing bugs in production, pay for Opus. 13.8 points on SWE-bench Pro is structural, not marginal. When a production incident costs thousands per minute, $25 for a correct fix is a trivial premium over $0.87 for one that might not work.
If you're running codebase-scale migrations, use Opus + Dynamic Workflows. No other model has a comparable orchestration layer. One Opus session can plan a migration, spawn hundreds of parallel subagents, verify results adversarially, and merge. Building this yourself is weeks of engineering.
If you're writing algorithms, use DeepSeek. It's literally better — and 28.7× cheaper. No tradeoff.
If you need data sovereignty, DeepSeek is the only option. MIT license. Self-host on your GPUs. Opus requires Anthropic's cloud.
20+ LLMs available. Side-by-side testing.
Sources: Vellum — Opus 4.8 Benchmarks | Totalum — Opus 4.8 Feature Breakdown | Anthropic — Opus 4.8 Launch | DeepSeek V4 Pro Model Card | MorphLLM — DeepSeek V4 | RunPod — V4 In the Wild.