
Both are Chinese. Both are open-weight. Both are called "Flash." Both launched within weeks of each other in April 2026. But the similarities end there. DeepSeek V4 Flash: 284B total / 13B active MoE, MIT-licensed, $0.28/1M output. 91.6% LiveCodeBench. Text-only, 1M native context. Qwen 3.6 Flash: 35B total / 3B active MoE, Apache 2.0, $0.90/1M output. 80.4% LiveCodeBench. Text + image + video input. 262K native context. One is the coding benchmark king — winning every head-to-head. The other is the efficiency miracle — doing it with 4× fewer active parameters, multimodal input, and faster tok/s. Here's the complete data. Test both on CodingFleet.
📊 Key Findings
- V4 Flash leads every coding benchmark. The cleanest sweep yet. Pro +3.1. Terminal +5.4. LiveCodeBench +11.2. HLE +13.4. GPQA +2.1. MCP Atlas +0.6. This is not a close comparison on pure code.
- Qwen is the efficiency champion. 35B/3B active vs 284B/13B. With 4.3× fewer active parameters and 8× fewer total parameters, Qwen achieves within 1-5 points of V4 Flash on most coding metrics. Also: multimodal input (text+image+video) and faster tok/s.
- V4 Flash is 3.2× cheaper: $0.28 vs $0.90 per 1M output. Both are open-weight but V4 Flash uses MIT (more permissive) vs Qwen's Apache 2.0. V4 Flash also has 1M native context vs Qwen's 262K.
- Qwen is 50-100% faster at inference: 90-172 tok/s vs 60-84. For latency-sensitive workflows, Qwen's 3B active footprint delivers smoother interactive experiences. Local deployment is practical on consumer GPUs.
- HLE gap is the widest: 34.8% vs 21.4% (+13.4). For research-heavy and deep reasoning tasks, V4 Flash is dramatically stronger. Qwen's 21.4% HLE is a genuine limitation for science-heavy coding.
Compare models on your own code at CodingFleet. See the SWE-bench Pro and Terminal-Bench leaderboards. Also: V4 Flash vs GPT-5.4 Mini · V4 Flash vs Gemini 3 Flash · Pricing Calculator.
Benchmark Comparison
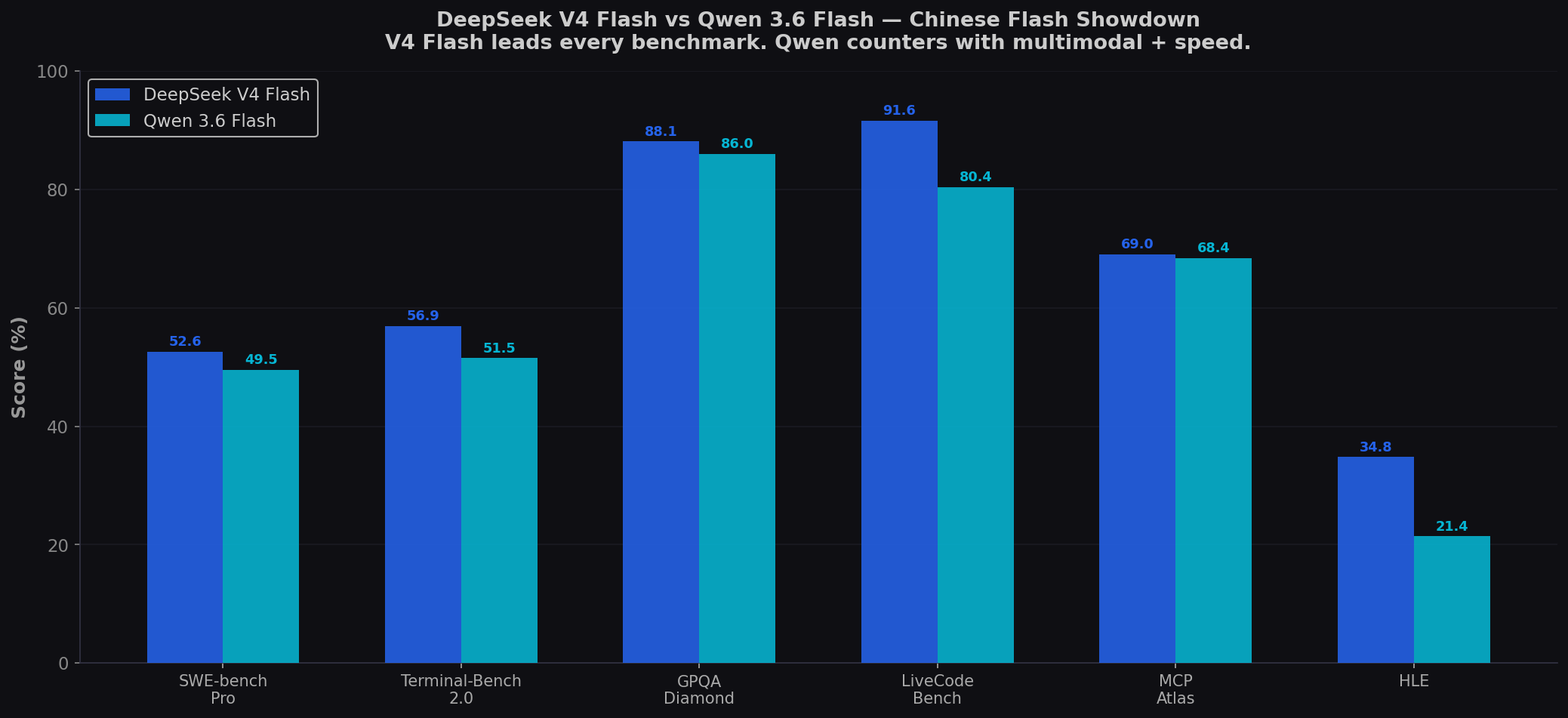
| Benchmark | DeepSeek V4 Flash | Qwen 3.6 Flash | Winner |
|---|---|---|---|
| SWE-bench Pro | 52.6% | 49.5% | V4 Flash (+3.1) |
| SWE-bench Verified | 79.0% | 73.4% | V4 Flash (+5.6) |
| Terminal-Bench 2.0 | 56.9% | 51.5% | V4 Flash (+5.4) |
| LiveCodeBench v6 | 91.6% | 80.4% | V4 Flash (+11.2) |
| GPQA Diamond | 88.1% | 86.0% | V4 Flash (+2.1) |
| HLE | 34.8% | 21.4% | V4 Flash (+13.4) |
| MMLU-Pro | 86.2% | 85.2% | V4 Flash (+1.0) |
| HMMT Feb 2026 | 94.8% | 83.6% | V4 Flash (+11.2) |
| AIME 2026 | 94.4%* | 92.7% | V4 Flash (+1.7) |
| MCP Atlas | 69.0% | 68.4% | V4 Flash (+0.6) |
| Output Price /1M tok | $0.28 | $0.90 | V4 Flash (3.2× cheaper) |
| Input Price /1M tok | $0.14 | $0.14 | Tie |
| Context Window (native) | 1M | 262K (1M w/ YaRN) | V4 Flash |
| Max Output | 384K | — | V4 Flash |
| Speed | ~60-84 tok/s | ~90-172 tok/s | Qwen (+50-100%) |
| Total Params | 284B | 35B | V4 Flash (8.1× larger) |
| Active Params | 13B | 3B | V4 Flash (4.3×) |
| License | MIT | Apache 2.0 | V4 Flash (more permissive) |
| Multimodal Input | Text only | Text + Image + Video | Qwen |
| Local Deployment | GPU server needed | Consumer GPU viable | Qwen |
Sources: DeepSeek V4 Model Card — V4 Flash scores (Max reasoning) · Qwen Official Blog — Qwen 3.6 Flash scores from model card comparison table · OpenRouter · PricePerToken. *AIME 2026: V4 Flash score interpolated from Pro Max (89.8) vs Flash High (85.1). Flash Max not published separately. "—" means not published.
Coding Radar: The Clean Sweep
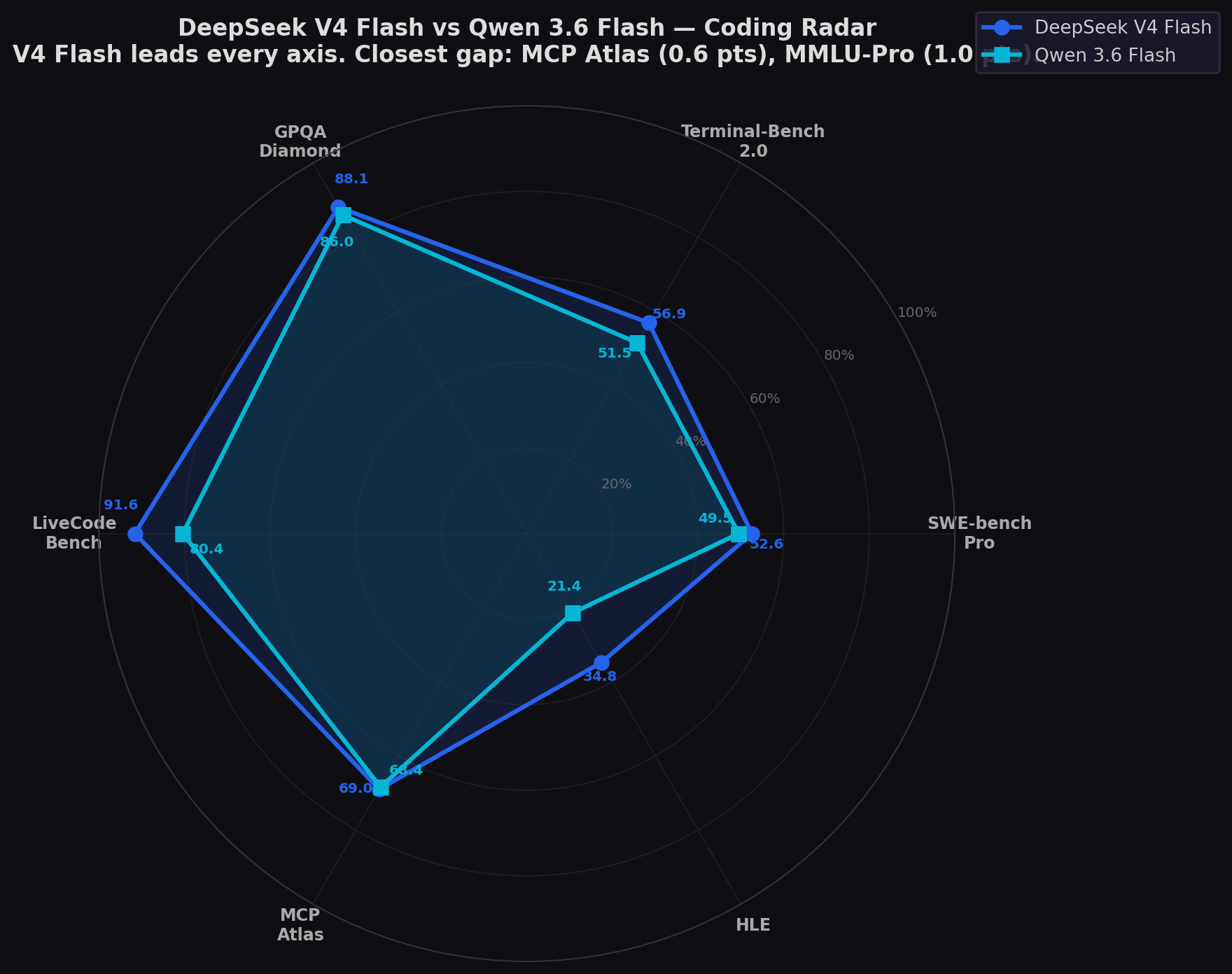
The radar tells a clear story: V4 Flash's blue ring encloses Qwen's cyan ring on every axis. The closest gap is MCP Atlas (0.6 points) and MMLU-Pro (1.0 points). The largest gaps are LiveCodeBench (11.2) and HLE (13.4). This is the most one-sided Flash comparison — but that's only half the story. Qwen achieves this with 4.3× fewer active parameters, multimodal input, and faster inference. It's not a coding win — it's an efficiency and modality win.
Where Each Model Wins at Coding
DeepSeek V4 Flash — The Benchmark King
- Sweeps every coding benchmark. Pro +3.1, Terminal +5.4, LiveCodeBench +11.2, HLE +13.4. For pure coding and reasoning performance, V4 Flash is demonstrably stronger in every category. No exceptions.
- LiveCodeBench 91.6% vs 80.4% — algorithmic dominance. The 11.2-point gap on competitive programming is the single largest differentiator between these models. For algorithm and data structure work, V4 Flash is in a different tier.
- HLE 34.8% vs 21.4% — deep reasoning gap. The widest relative gap. For research-heavy coding requiring deep scientific reasoning, V4 Flash is dramatically more capable.
- 3.2× cheaper: $0.28 vs $0.90 per 1M output. MIT license. 1M native context vs 262K. For cost-sensitive production pipelines and long-context coding, V4 Flash is the better economics.
- 384K max output — massive generation headroom. Qwen hasn't published a max output limit, but V4 Flash's 384K enables entire-file generations, full test suites, and complete documentation in a single pass.
Qwen 3.6 Flash — The Efficiency & Modality Play
- 35B total / 3B active — runs on a consumer GPU. While V4 Flash needs server-grade hardware for self-hosting, Qwen runs comfortably on a 24GB consumer card. For individual developers and small teams, Qwen is practical to deploy locally today.
- Multimodal: text + image + video input. Code from screenshots. Debug from screen recordings. Process UI mockups. Read charts and diagrams. V4 Flash is text-only — Qwen opens entirely different coding workflows.
- 50-100% faster: 90-172 tok/s vs 60-84 tok/s. For interactive coding sessions, Qwen's smaller active parameter footprint delivers noticeably faster response times. Less waiting between prompts.
- Apache 2.0 license — patent grant included. Both are open-weight, but Apache 2.0 includes an explicit patent grant that MIT does not. For enterprise legal teams, this matters.
- Within 0.6-5.6 points on most benchmarks despite 4.3× fewer active parameters. On MCP Atlas, the gap is just 0.6 points. On MMLU-Pro, 1.0 points. On GPQA, 2.1 points. Qwen's architectural efficiency is genuinely impressive.
When to Use Which
| Scenario | Use | Why |
|---|---|---|
| Production bug fixing (real repos) | DeepSeek V4 Flash | 52.6% Pro vs 49.5%. +3.1 lead. |
| Algorithm & competitive programming | DeepSeek V4 Flash | 91.6% LiveCodeBench. +11.2 lead. |
| Research-heavy coding (deep reasoning) | DeepSeek V4 Flash | 34.8% HLE vs 21.4%. +13.4. |
| Cost-sensitive high-volume API | DeepSeek V4 Flash | $0.28 vs $0.90. 3.2× cheaper. |
| Long-context codebase analysis (1M) | DeepSeek V4 Flash | 1M native vs 262K. No YaRN needed. |
| Code from images / video / screenshots | Qwen 3.6 Flash | Only one with multimodal input. |
| Local deployment on consumer GPU | Qwen 3.6 Flash | 3B active. Runs on 24GB cards. |
| Interactive coding (low latency) | Qwen 3.6 Flash | 90-172 tok/s. 50-100% faster. |
| Budget local inference | Qwen 3.6 Flash | 35B total params. Much lighter. |
Conclusion: The Coding Sweep vs The Efficiency Miracle
DeepSeek V4 Flash is the unequivocally better coding model. Every benchmark. Every category. Pro, Terminal, LiveCodeBench, HLE, GPQA, MMLU-Pro, HMMT, AIME, MCP Atlas — V4 Flash leads them all. If your question is "which model writes better code," the answer is V4 Flash. It's also cheaper, has a larger native context window, and uses a more permissive MIT license.
Qwen 3.6 Flash is the efficiency and modality champion. With 4.3× fewer active parameters, Qwen achieves within a few points of V4 Flash on most coding benchmarks while adding multimodal input and running 50-100% faster. For developers who need to code from visual references, deploy on consumer hardware, or prioritize interactive speed over raw benchmark scores, Qwen is the more practical choice. The 35B/3B footprint is a genuine engineering achievement.
The Flash tier in April 2026 presents a clean tradeoff: benchmarks and value → DeepSeek V4 Flash. Modality and deployability → Qwen 3.6 Flash. Both are open-weight. Both are Chinese. Both are excellent. Choose based on your stack, not your benchmark loyalty.
20+ LLMs available. Side-by-side testing. Both Flash models ready.
Sources: DeepSeek V4 Model Card | Qwen 3.6 Flash Official Blog | Qwen 3.6 HF Model Card | OpenRouter | PricePerToken | SWE-bench Pro Leaderboard | Terminal-Bench Leaderboard.