
The same company. The same generation. Completely different priorities. Gemini 3.1 Pro is Google's $12/1M enterprise flagship — 2M token context, best-in-class abstract reasoning (HLE 44.4%, ARC-AGI-2 77.1%, GPQA 94.3%), and 116 tok/s. Gemini 3.5 Flash is Google's $9/1M speed-optimized agent — 4× faster (152 tok/s), beats Pro on every agentic benchmark, and costs 25% less. Flash is the stronger coding and tool-use model. Pro is the stronger reasoning and long-context model. Here's the complete comparison backed by the Google DeepMind official model card, LLM Stats, Appwrite, and PricePerToken. Try both on CodingFleet.
📊 TL;DR — Key Findings
- Flash dominates agents & coding: Finance Agent v2 (+14.9), Terminal-Bench 2.1 (+5.9), MCP Atlas (+5.4), OSWorld (+2.2), GDPval-AA (+342 Elo). Clean sweep on agentic benchmarks.
- Pro leads reasoning & long context: HLE (+4.2), MRCR v2 128K (+7.6), ARC-AGI-2 (+5.0). For deep reasoning, Pro is still king.
- Flash is 25% cheaper: $1.50/$9 per 1M vs Pro's $2.00/$12. Batch/Flex takes both to 50% off.
- Pro has 2× larger context: 2M tokens (industry's largest) vs Flash's 1M. For massive codebase analysis, Pro is the only option at this scale.
- Google's own verdict: "If your workload is an agent that needs to get something done rather than a researcher asking a hard question, 3.5 Flash is the better choice today."
Try both models side-by-side on CodingFleet
Benchmark Comparison
| Benchmark | Gemini 3.1 Pro | Gemini 3.5 Flash | Winner |
|---|---|---|---|
| Terminal-Bench 2.1 | 70.3% | 76.2% | Flash (+5.9) |
| SWE-bench Pro | 54.2% | 55.1% | Flash (+0.9) |
| MCP Atlas | 78.2% | 83.6% | Flash (+5.4) |
| Toolathlon | — (not published) | 56.5% | Flash — Pro score not published |
| OSWorld-Verified | 76.2% | 78.4% | Flash (+2.2) |
| Finance Agent v2 | 43.0% | 57.9% | Flash (+14.9) |
| GDPval-AA (Elo) | 1314 | 1656 | Flash (+342 Elo) |
| CharXiv Reasoning | 83.3% | 84.2% | Flash (+0.9) |
| MMMU-Pro | 80.5% | 83.6% | Flash (+3.1) |
| Blueprint-Bench 2 | 26.5% | 33.6% | Flash (+7.1) |
| MRCR v2 (128K) | 84.9% | 77.3% | Pro (+7.6) |
| HLE (no tools) | 44.4% | 40.2% | Pro (+4.2) |
| ARC-AGI-2 | 77.1% | 72.1% | Pro (+5.0) |
| GPQA Diamond | 94.3% | — (not published) | Pro |
| Output Price /1M tok | $12.00 | $9.00 | Flash (25% cheaper) |
| Speed (tok/s) | 116 tok/s | 152 tok/s | Flash (1.3× faster) |
Sources: Google DeepMind — Gemini 3.5 Flash Model Card | LLM Stats — Flash launch analysis | Appwrite Flash deep-dive | Google Blog — Gemini 3.5 announcement | PricePerToken — 3.1 Pro specs. All scores vendor-reported from Google published model card.
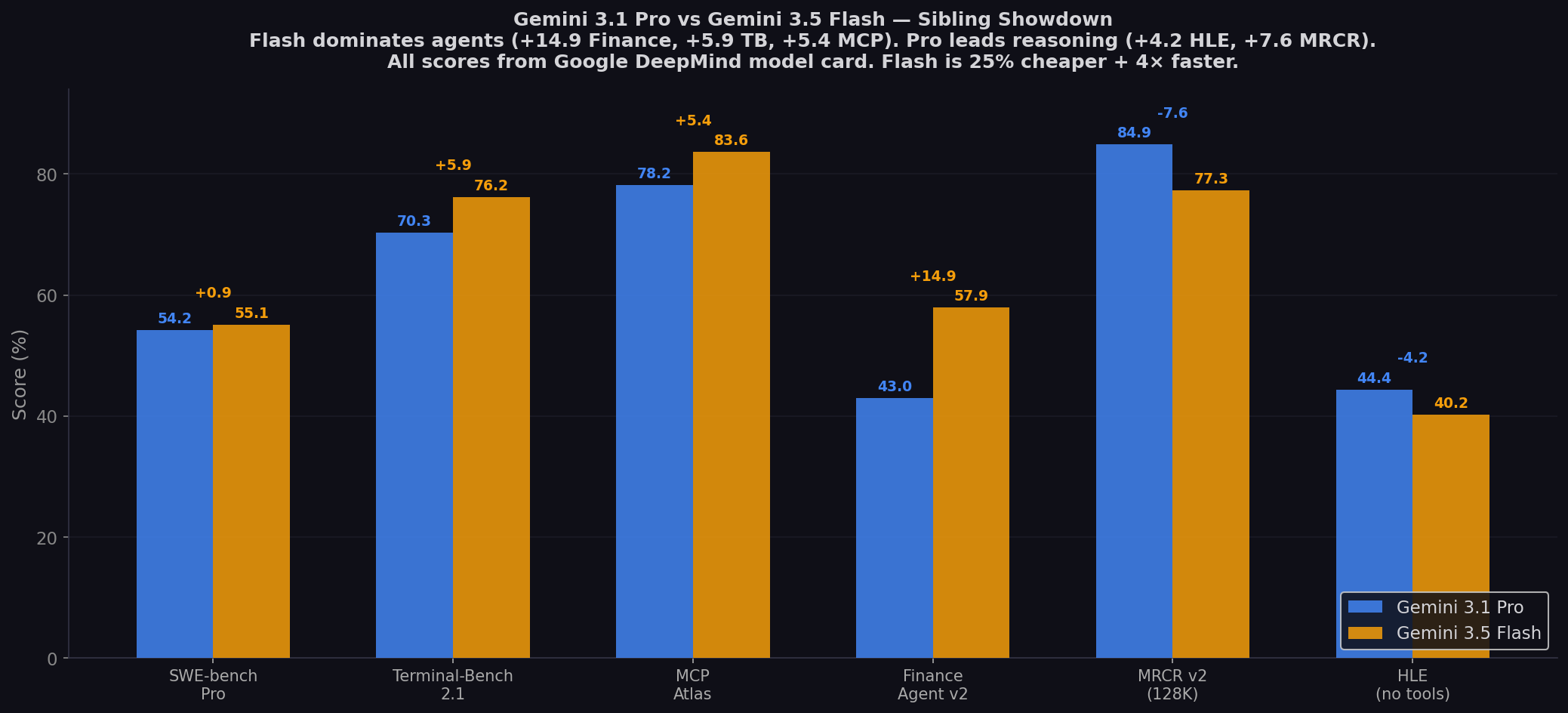

Finance Agent v2: The 14.9-Point Wake-Up Call
The single most important number in this comparison. Gemini 3.5 Flash at 57.9% vs Gemini 3.1 Pro at 43.0% on Finance Agent v2 — the benchmark for real-world financial analysis and decision-making with tool use. A 14.9-point gap between two models from the same company, same generation. This isn't a marginal edge — it's a fundamentally different capability tier. LLM Stats frames the trade Google is asking: "3.5 Flash trails 3.1 Pro on Humanity's Last Exam and ARC-AGI-2 — the benchmarks dominated by raw parametric knowledge and pure abstract reasoning. It beats 3.1 Pro on the benchmarks that look like real work."
Agentic Sweep: Flash Leads Every Agentic Benchmark
The pattern is unambiguous: MCP Atlas (+5.4), Terminal-Bench (+5.9), OSWorld (+2.2), GDPval-AA (+342 Elo), and Toolathlon where Pro didn't even publish. Appwrite's analysis confirms: "The largest gain is MCP Atlas: a 21.6 point increase over Gemini 3 Flash and 5.4 points over 3.1 Pro. On MCP tool-call workloads, 3.5 Flash is Google's strongest model in the Gemini 3 series." For developers building multi-step agent pipelines, tool orchestration, and computer-use agents, Flash is not just cheaper — it's better.
Pro's Counter-Attack: Deep Reasoning & Long Context
Pro fights back where it matters for research: HLE no-tools (+4.2), MRCR v2 128K (+7.6), ARC-AGI-2 (+5.0), GPQA Diamond (94.3% — Flash unpublished). For teams that need deep analytical reasoning on large document corpora, Pro's 2M context window (2× Flash's 1M) combined with stronger MRCR performance makes it the clear choice. But Google's model card reveals both models struggle at 1M: MRCR v2 1M scores are 26.3% (Pro) and 26.6% (Flash) — virtually identical and low for both.
Architecture & Ecosystem
| Feature | Gemini 3.1 Pro | Gemini 3.5 Flash |
|---|---|---|
| Release Date | February 19, 2026 | May 19, 2026 |
| Context Window | 2M tokens | 1M tokens |
| Speed (tok/s) | 116 tok/s | 152 tok/s |
| TTFT | 20.05s | 18.73s |
| Input Price | $2.00/1M | $1.50/1M |
| Output Price | $12.00/1M | $9.00/1M |
| Cached Input | $0.20/1M | $0.15/1M |
| Input Modalities | Text, Image, Audio, Video | Text, Image, Audio, Video, PDF |
| Thinking Mode | Deep reasoning | Explicit levels (quality/cost tradeoff) |
| Ecosystem | NotebookLM, Deep Research, Jules | Antigravity, Managed Agents, Spark, AI Mode |
Pricing: Same Family, 25% Different
At 100M output tokens/month: Pro costs $1,400 vs Flash at $1,050. With Batch/Flex (50% off): Pro at $700, Flash at $525. The $175–$350 monthly gap is modest. The decision isn't driven by price — it's driven by use case.
Which Model Should You Use?
| Use Case | Winner | Why |
|---|---|---|
| Agentic CLI / DevOps | Flash ✅ | +5.9 Terminal-Bench 2.1. Google's strongest CLI agent |
| Tool orchestration (MCP) | Flash ✅ | +5.4 MCP Atlas. Best MCP model in Gemini 3 series |
| Financial analysis | Flash ✅ | +14.9 Finance Agent v2. Dominant on structured finance |
| Coding (SWE-bench Pro) | Flash ✅ | +0.9. Narrow edge — both viable for coding |
| Deep reasoning / research | Pro ✅ | +4.2 HLE, +5.0 ARC-AGI-2, 94.3% GPQA |
| Long-context analysis | Pro ✅ | +7.6 MRCR 128K. 2M context — largest available |
| Massive document processing | Pro ✅ | 2M tokens — 2× Flash. Unique capability |
| Speed / latency sensitive | Flash ✅ | 152 tok/s — 4× faster than other frontier models |
Conclusion: The Right Gemini for the Right Job
Google's own framing — "a Flash model that beats its own Pro tier on coding and agents" — captures the dynamic. Gemini 3.5 Flash is the better model for agentic coding, tool orchestration, financial analysis, and any workload where speed and cost compound across repeated calls. It beats Pro on every agentic benchmark, often by significant margins.
Gemini 3.1 Pro is the better model for deep reasoning, long-context analysis, and abstract thought. The 2M context window, stronger MRCR and HLE scores, and 94.3% GPQA make it the choice for research-heavy workloads where correctness matters more than speed.
The practical answer: use Flash for agents, Pro for analysis. LLM Stats' verdict captures the strategic reality: "If your workload is 'an agent that needs to get something done' rather than 'a researcher asking a hard question,' 3.5 Flash is the better choice today."
20+ LLMs available on CodingFleet. Test Gemini 3.1 Pro and 3.5 Flash side-by-side on your own code.
📚 Sources & Links
- Google DeepMind — Gemini 3.5 Flash Model Card (official)
- Google Blog — Gemini 3.5 launch
- LLM Stats — Flash benchmark analysis
- Appwrite — Flash deep-dive
- PricePerToken — 3.1 Pro pricing & specs
- Metacto — Gemini pricing guide (May 2026)
- Francesco Ciulla on X — Flash benchmark table
📖 Read This Next
- GPT-5.5 vs Gemini 3.5 Flash — flagship vs speed demon
- Gemini 3.1 Pro vs GPT-5.5 — enterprise workhorse vs OpenAI
- Gemini 3.5 Flash vs DeepSeek V4 Pro — speed vs value
- SWE-bench Pro Live Leaderboard