
📊 TL;DR — Key Findings
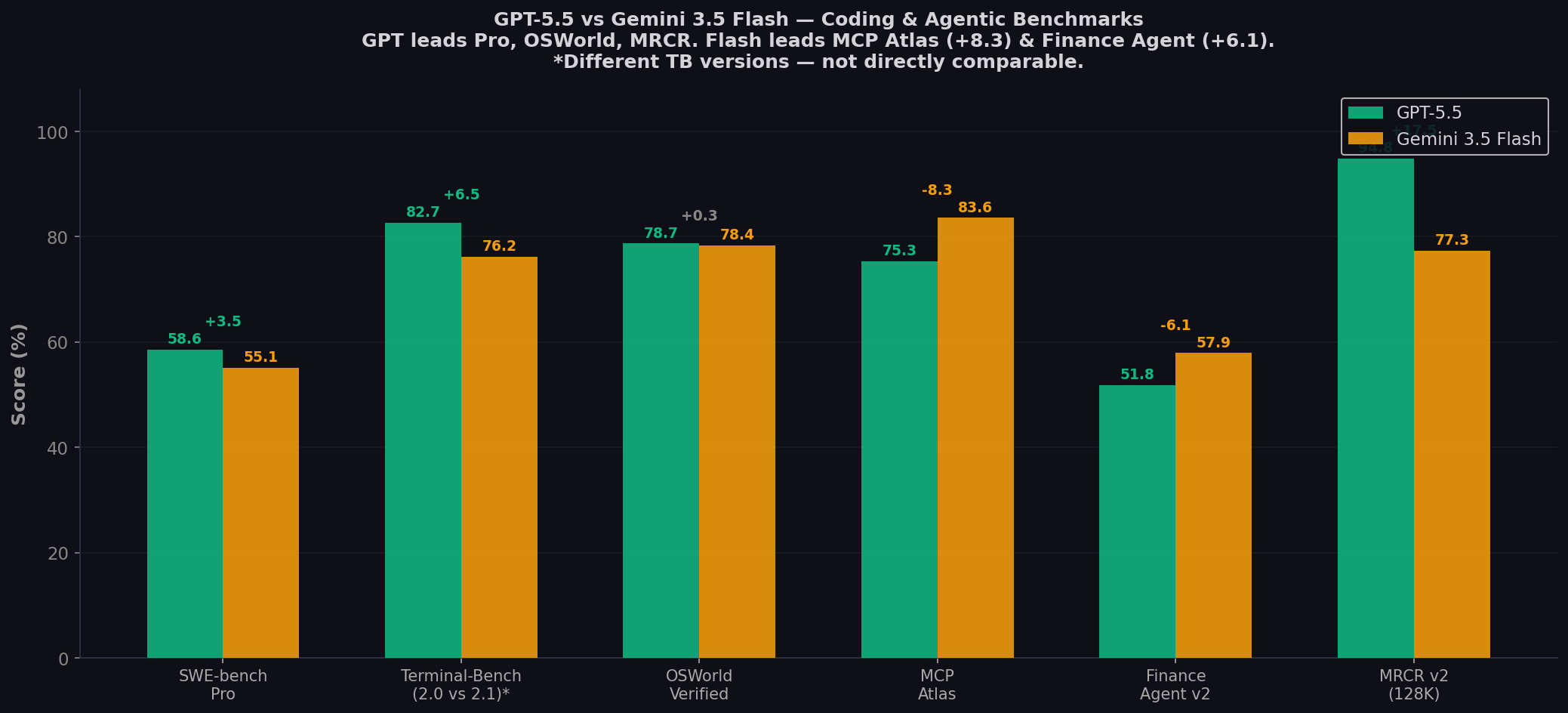
- GPT-5.5 dominates reasoning: +17.5 MRCR v2 (128K long context), +12.5 ARC-AGI-2 (abstract reasoning), +3.5 SWE-bench Pro.
- Flash dominates tool orchestration: +8.3 MCP Atlas (83.6% — best-in-class for multi-step tool calling), +6.1 Finance Agent v2, +0.9 Toolathlon.
- 3.3× price gap: Flash $9/1M output vs GPT-5.5 $30/1M. At 100M tokens/month: Flash $900 vs GPT-5.5 $3,000.
- 4× speed gap: Flash 152 tok/s vs GPT-5.5 ~38 tok/s. For latency-sensitive agent loops, Flash is in a different league.
- Terminal-Bench versions differ: GPT-5.5 at 82.7% (2.0) vs Flash at 76.2% (2.1). Not directly comparable — TB 2.1 is harder.
- OSWorld near-tie: GPT-5.5 78.7% vs Flash 78.4% — 0.3 point gap on computer use tasks.
Try both models side-by-side on your own code at CodingFleet →
Benchmark Comparison
| Benchmark | GPT-5.5 | Gemini 3.5 Flash | Winner |
|---|---|---|---|
| SWE-bench Pro ★ | 58.6% | 55.1% | GPT-5.5 (+3.5) |
| Terminal-Bench (2.0 vs 2.1)* | 82.7% (2.0) | 76.2% (2.1) | ⚠️ Different versions — not directly comparable |
| OSWorld-Verified | 78.7% | 78.4% | GPT-5.5 (+0.3 — virtual tie) |
| MCP Atlas | 75.3% | 83.6% | Flash (+8.3) |
| Toolathlon | 55.6% | 56.5% | Flash (+0.9 — near tie) |
| Finance Agent v2 | 51.8% | 57.9% | Flash (+6.1) |
| GDPval-AA (Elo) | 1769 | 1656 | GPT-5.5 (+113) |
| Blueprint-Bench 2 | 36.2% | 33.6% | GPT-5.5 (+2.6) |
| MMMU-Pro | 81.2% | 83.6% | Flash (+2.4) |
| CharXiv Reasoning | 84.1% | 84.2% | Flash (+0.1 — tie) |
| MRCR v2 (128K) | 94.8% | 77.3% | GPT-5.5 (+17.5) |
| MRCR v2 (1M) | 74.0% | 26.6% | GPT-5.5 (+47.4) |
| ARC-AGI-2 | 84.6% | 72.1% | GPT-5.5 (+12.5) |
| GPQA Diamond | 93.6% | — | GPT-5.5 — Flash score not published |
| Output Price /1M tok | $30.00 | $9.00 | Flash (3.3× cheaper) |
| Speed (tok/s) | ~38 tok/s | 152 tok/s | Flash (4.0× faster) |
Sources: Google DeepMind — Gemini 3.5 Flash Model Card (all Flash + competitor comparison rows from Google's published table) | Vellum — GPT-5.5 benchmarks | Artificial Analysis — GPT-5.5 vs Flash comparison | Google Blog — Gemini 3.5 announcement. All scores vendor-reported. ⚠️ Terminal-Bench version mismatch flagged. ★ SWE-bench Pro is the recommended benchmark.

MCP Atlas: Flash's Signature Win (+8.3)
The single most important finding in this comparison. Gemini 3.5 Flash scores 83.6% on MCP Atlas — the benchmark for multi-step tool orchestration via Model Context Protocol. GPT-5.5 scores 75.3%. That's an 8.3-point gap on the benchmark that most directly tests what AI agents actually do: chain multiple tools together reliably. DataCamp's analysis captures why this matters: "Agentic workflows seem to be the primary AI trend in 2026, so this gap could matter more than the Terminal-Bench gap in the other direction." Google explicitly designed Flash as the workhorse inside Antigravity's agent loops, and it shows — Flash's MCP Atlas score is the highest among all non-Mythos models tracked on the benchmark.
Terminal-Bench: The Version Trap
GPT-5.5 scores 82.7% on Terminal-Bench 2.0. Gemini 3.5 Flash scores 76.2% on Terminal-Bench 2.1. These are different test versions — TB 2.1 is harder than TB 2.0. You cannot directly compare them. The Google DeepMind model card provides the honest read: GPT-5.5 at 78.2% on TB 2.1 (using the standard harness). That narrows the gap from "6.5-point GPT lead" to "2.0-point GPT lead" — still GPT-5.5's favor, but within harness noise. For developers building CLI agents, both models are viable. For unattended terminal workflows where mistakes are expensive, GPT-5.5's proven terminal track record (highest TB 2.0 score ever at 82.7%) gives it the edge.
Long-Context Recall: The 47-Point Chasm
The widest gap on any shared benchmark. On MRCR v2 at 1M tokens — the gold standard for long-context retrieval — GPT-5.5 scores 74.0% while Flash collapses to 26.6%. Even at 128K tokens, the gap is 17.5 points (94.8% vs 77.3%). For applications loading entire codebases, large document corpora, or long conversation histories, GPT-5.5's structural advantage in long-context reasoning is decisive. This is the Achilles' heel of Flash — fast and cheap, but with a context window that degrades sharply beyond 128K.
Architecture & Ecosystem
| Feature | GPT-5.5 | Gemini 3.5 Flash |
|---|---|---|
| Release Date | April 23, 2026 | May 19, 2026 |
| Developer | OpenAI | Google DeepMind |
| Context Window | 922K tokens | 1,000K tokens |
| Speed (tok/s) | ~38 tok/s | 152 tok/s (4× faster) |
| Output Price /1M | $30.00 | $9.00 (3.3× cheaper) |
| Input Price /1M | $5.00 | $1.50 |
| Cached Input /1M | $0.50 | $0.15 |
| Batch/Flex Discount | 50% off ($15 output) | 50% off ($4.50 output) |
| Input Modalities | Text, Image, Audio, Video | Text, Image |
| Agentic Tools | Codex CLI, Computer Use, Sub-agents (8 parallel) | Antigravity, Managed Agents, Spark, Google Search |
| AA Intelligence Index | 60.2 (#2) | 55.3 |
| TTFT (Time to First Token) | ~3s | 18.73s (thinking overhead) |
| BenchLM Overall | 91/100 (#4 of 122) | — (Flash not yet fully benchmarked) |
Why GPT-5.5 Wins on Raw Intelligence
GPT-5.5 is OpenAI's most capable agentic coding model. Terminal-Bench 2.0 at 82.7% remains the highest score ever recorded (Claude Fable 5 at 88.0% on TB 2.1 excepted). The Codex CLI ecosystem — with cloud sandbox execution, 8 parallel sub-agents, 24+ hour unattended runs, and kernel-level sandboxing — gives GPT-5.5 an infrastructure advantage for complex, long-horizon tasks. The model's omnimodal architecture (text, image, audio, video in a single unified model) handles inputs that Flash can't. And on the hardest reasoning tests — MRCR v2 (+17.5), ARC-AGI-2 (+12.5) — the gap isn't marginal. It's structural. For teams building production coding agents where correctness matters more than cost, GPT-5.5 is the safer pick. O-Mega's analysis notes: "GPT-5.5 excels at planning and executing new workflows, and the CyberGym score of 81.8% suggests strong cybersecurity capabilities that complement the agentic coding profile."
Why Flash Wins on Speed & Tool Orchestration
Gemini 3.5 Flash was explicitly designed as "our strongest agentic and coding model yet, outperforming Gemini 3.1 Pro on challenging coding and agentic benchmarks." The 83.6% MCP Atlas score and 57.9% Finance Agent v2 aren't accidents — they reflect Google's bet that the future of AI coding is multi-step tool orchestration, not single-shot reasoning. The 4× speed advantage (152 vs 38 tok/s) isn't just nice-to-have — for latency-sensitive agent loops where the model is called hundreds of times per workflow, the cost and time difference compounds fast. And the Managed Agents + Spark + Google Search integration in Antigravity gives Flash an ecosystem that GPT-5.5's Codex CLI can't match for web-connected agentic work. DataCamp summarizes: "Flash is the stronger choice for tool-heavy pipelines, financial document work, and any deployment where cost and speed are primary constraints."
Pricing: 3.3× Economics + 4× Speed
At 100M output tokens/month — a realistic volume for production agent pipelines:
- GPT-5.5: $3,000/month (output) + $500/month (input) = $3,500/month
- Flash: $900/month (output) + $150/month (input) = $1,050/month
With Batch/Flex (50% off): GPT-5.5 drops to $1,750, Flash to $525. The $1,225-$2,975 monthly difference funds an entire additional model in your stack — or covers the cost of running DeepSeek V4 Pro ($0.87/1M) as a volume backbone with Flash as the orchestration layer. Flash's $0.15/1M cached input rate makes repeated agent loops dramatically cheaper — a pattern that compounds for any workflow where system prompts and tool schemas are resent on every turn.
Which Model Should You Use?
| Use Case | Winner | Why |
|---|---|---|
| Multi-file bug fixing | GPT-5.5 ✅ | +3.5 SWE-bench Pro — better at real GitHub issue resolution |
| Terminal / CLI / DevOps | GPT-5.5 ✅ | 82.7% TB 2.0 — highest ever. Flash at 76.2% on harder TB 2.1 |
| MCP tool orchestration | Flash ✅ | 83.6% MCP Atlas — +8.3. Best-in-class for multi-step tool chains |
| Financial analysis agents | Flash ✅ | +6.1 Finance Agent v2 — structured financial data is Flash's strength |
| Long-context codebase work | GPT-5.5 ✅ | +47.4 MRCR v2 at 1M. Flash collapses to 26.6% |
| Abstract reasoning | GPT-5.5 ✅ | +12.5 ARC-AGI-2. Flash at 72.1% is competent but far behind |
| High-volume budget pipelines | Flash ✅ | 3.3× cheaper, 4× faster. $525/mo vs $1,750/mo at 100M tokens with Batch |
| Latency-sensitive agent loops | Flash ✅ | 152 tok/s vs 38 tok/s. Compounding advantage across hundreds of calls |
| Computer use / GUI tasks | ⚖️ Tie | OSWorld 78.7% vs 78.4% — 0.3 points apart. Both are excellent |
| Multimodal (video/audio) | GPT-5.5 ✅ | Native omnimodal. Flash is text + image only |
Conclusion: The Generalist vs The Specialist
GPT-5.5 is the better model on raw intelligence — it leads on SWE-bench Pro, long-context reasoning, abstract reasoning, and has the stronger agentic infrastructure (Codex CLI, sub-agents, cyber capabilities). It's the model you reach for when correctness matters more than cost.
Gemini 3.5 Flash is the better model for tool orchestration — MCP Atlas at 83.6%, Finance Agent v2 at 57.9%, and 4× faster at 3.3× lower cost. For teams building multi-step agent pipelines, financial analysis agents, or any deployment where the model is called hundreds of times per workflow, Flash is the smarter economic choice.
The practical answer: use both. GPT-5.5 for hard reasoning, long-context codebase work, and unattended terminal agents. Flash for high-volume tool orchestration, financial analysis, and any task where speed and cost compound across repeated calls. The Lushbinary analysis captures the strategic take: "Opus 4.8 owns the hardest coding benchmark. GPT-5.5 keeps the Terminal-Bench crown. Gemini 3.5 Flash is the surprise — it punches well above its price on agentic-first, latency-sensitive work."
20+ LLMs available on CodingFleet. Test GPT-5.5 and Gemini 3.5 Flash side-by-side on your own code.
📚 Sources & Links
- Google DeepMind — Gemini 3.5 Flash Model Card — official benchmark table with GPT-5.5 comparison rows
- Google Blog — Gemini 3.5 announcement — "4× faster than other frontier models"
- Vellum — Everything You Need to Know About GPT-5.5 — comprehensive benchmark table
- Artificial Analysis — GPT-5.5 vs Gemini 3.5 Flash — independent speed/intelligence comparison
- DataCamp — Gemini 3.5 Flash vs GPT-5.5 — detailed analysis with MCP Atlas emphasis
- Lushbinary — Opus 4.8 vs GPT-5.5 vs Gemini 3.5 Flash — three-way cost-performance analysis
- O-Mega — GPT-5.5 Complete Guide 2026 — cross-model analysis with CyberGym context
- MorphLLM — SWE-bench Pro Leaderboard — cross-validated scores
- Francesco Ciulla on X — Gemini 3.5 Flash benchmark roundup — GPT-5.5 comparison data points
- Artificial Analysis — Gemini 3.5 Flash model page — speed, price, and quality metrics
📖 Read This Next
- Gemini 3.1 Pro vs GPT-5.5 — Google's enterprise workhorse vs OpenAI's flagship
- GPT-5.5 vs Qwen 3.7 Max — the $7.50 challenger that beats GPT on Pro
- MiniMax M3 vs GPT-5.5 — open-weight beats proprietary on Pro at 25× less
- SWE-bench Pro Live Leaderboard — every model ranked
- AI Model Pricing Calculator — compare costs at your token volume