📊 TL;DR — Key Findings
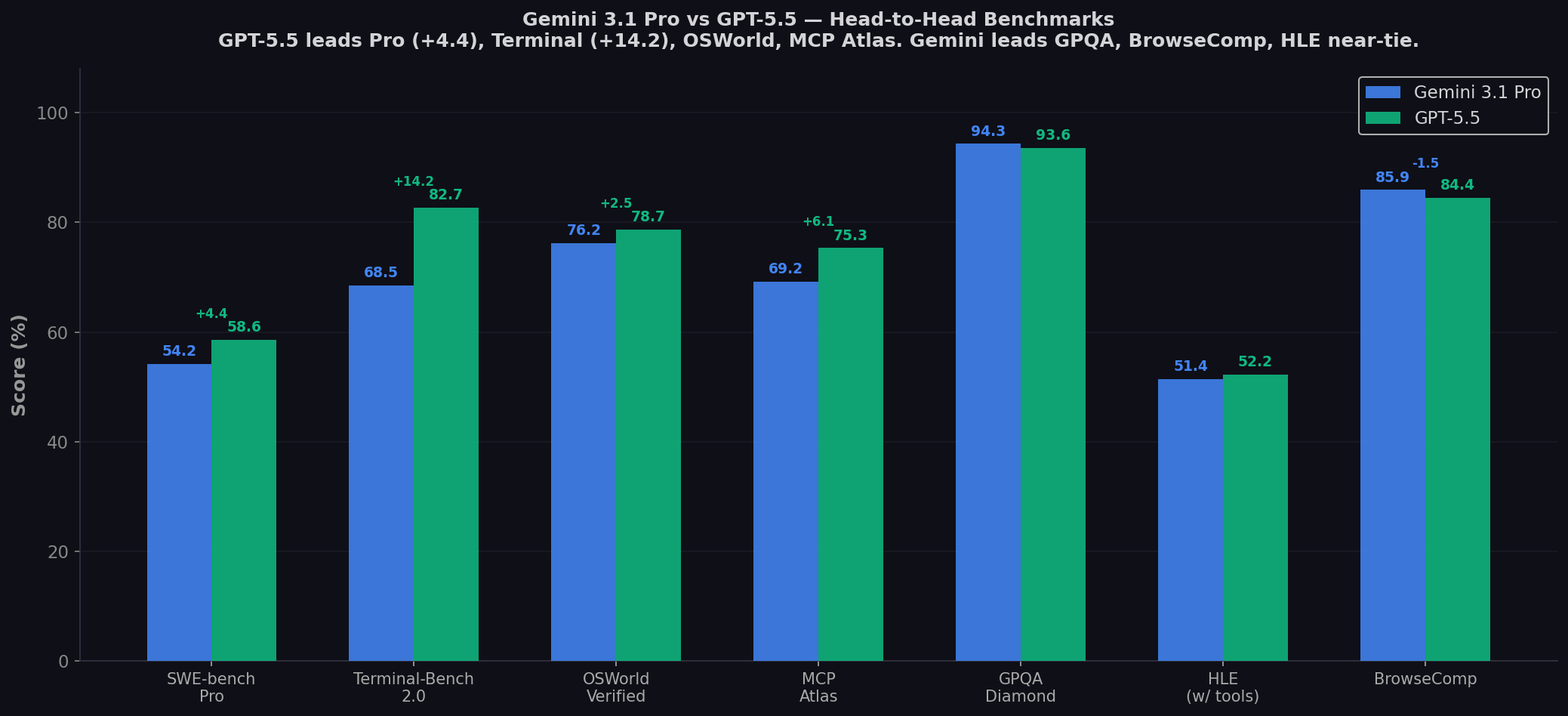
- GPT-5.5 dominates agentic coding: +4.4 pts SWE-bench Pro, +14.2 pts Terminal-Bench 2.0. For unattended terminal workflows, GPT-5.5 is the clear winner.
- Gemini wins on price: $2/$12 per 1M vs $5/$30 — 2.5× cheaper. Batch/Flex halves it further to $1/$6.
- GPQA Diamond near-tie: 94.3% vs 93.6% — both essentially at the ceiling for scientific reasoning.
- Gemini leads browsing: BrowseComp 85.9% vs 84.4% — Google Search integration advantage.
- HLE is a virtual tie: GPT-5.5 leads by 0.8 pts with tools — effectively identical on the hardest exam.
- Context window tie at 1M: But Gemini collapses to 26.3% at full context on MRCR v2 while GPT-5.5 holds 74.0%.
- 32% of GPT-5.5 SWE-bench Pro failures may trace to broken test cases (community analysis, unconfirmed).
Try both models side-by-side on your own code at CodingFleet →
Benchmark Comparison
| Benchmark | Gemini 3.1 Pro | GPT-5.5 | Winner |
|---|---|---|---|
| SWE-bench Pro | 54.2% | 58.6% | GPT-5.5 (+4.4) |
| SWE-bench Verified ⚠️ | 80.6% | 82.6% | GPT-5.5 (+2.0) |
| Terminal-Bench 2.0 | 68.5% | 82.7% | GPT-5.5 (+14.2) |
| OSWorld-Verified | 76.2% | 78.7% | GPT-5.5 (+2.5) |
| MCP Atlas | 69.2% | 75.3% | GPT-5.5 (+6.1) |
| BrowseComp | 85.9% | 84.4% | Gemini (+1.5) |
| GPQA Diamond | 94.3% | 93.6% | Gemini (+0.7) |
| HLE (no tools) | 44.4% | 41.4% | Gemini (+3.0) |
| HLE (with tools) | 51.4% | 52.2% | GPT-5.5 (+0.8) |
| LiveCodeBench Pro (Elo) | 2,887 | — | Gemini — GPT-5.5 not published |
| SciCode | 59% | — | Gemini — GPT-5.5 not published |
| CyberGym | — | 81.8% | GPT-5.5 — Gemini not published |
| MRCR v2 (1M tokens) | 26.3% | 74.0% | GPT-5.5 (+47.7) |
Sources: Google DeepMind model card | OpenAI GPT-5.5 page | Vellum. ⚠️ SWE-bench Verified deprecated by OpenAI Feb 2026 over contamination concerns.

The Terminal-Bench Gap: +14.2 Points
The single biggest differentiator between these two models. Terminal-Bench tests real CLI workflows — planning, iteration, and tool coordination in a sandboxed terminal. GPT-5.5's 82.7% vs Gemini's 68.5% is the widest gap on any shared benchmark. For developers building unattended terminal agents, CI/CD pipeline runners, or DevOps automation, this benchmark represents real agentic work more faithfully than SWE-bench. No publicly available model approached GPT-5.5's terminal performance until Claude Fable 5 arrived at 88.0%.
The harness matters: Gemini scores 68.5% on the standard Terminus-2 harness. But with scaffold optimization, it climbs to 80.2% (TongAgents harness). GPT-5.5 reaches 82.2% on Codex CLI and 84.7% on third-party harnesses — so the gap shrinks with better tooling, but GPT-5.5's raw advantage persists.
Reasoning & Knowledge: Split Decision
GPQA Diamond (94.3% vs 93.6%): Both are essentially at the ceiling for graduate-level scientific reasoning. A 0.7-point gap is within noise. HLE no-tools (44.4% vs 41.4%): Gemini leads by 3.0 points on the hardest exam ever created — but HLE with tools narrows to 0.8 points. The practical takeaway: both models are strong enough on pure reasoning that your choice should depend on task type, not GPQA/HLE scores.
LiveCodeBench Pro (2,887 Elo): Gemini 3.1 Pro leads the competitive programming benchmark with a commanding Elo rating. GPT-5.5 has not published a LiveCodeBench Pro score — only an earlier LiveCodeBench v6 score of 91.0% (at launch, now likely outdated). For competitive programming and algorithmic tasks, Gemini's proven Elo is the safer pick.
The Context Paradox: Both Claim 1M — Only One Delivers
Both models advertise 1M-token context windows. But on the MRCR v2 8-needle test — which measures whether the model can actually retrieve specific information from deep within the context — the difference is dramatic: GPT-5.5 holds 74.0% at full 1M context while Gemini collapses to 26.3%. For applications processing entire codebases, large document corpora, or long conversation histories, GPT-5.5's long-context recall is a structural advantage.
However: Gemini's usable context (up to ~256K where retrieval stays above 75%) covers 90%+ of real-world use cases. The 1M collapse is only relevant for the most extreme long-context workloads — and Gemini remains 2.5× cheaper across all context lengths.
MCP Atlas: The Tool Orchestration Divide
GPT-5.5 scores 75.3% vs Gemini's 69.2% — a 6.1-point lead on multi-step tool orchestration. For teams building complex agent chains with Model Context Protocol, GPT-5.5's better reliability in chained scenarios matters. However, Gemini 3.1 Pro leads cross-server MCP coordination (69.2% vs 54.1% for the previous Gemini generation), making it the stronger pick for multi-server orchestration where Google's infrastructure advantage shines.
Pricing: The 2.5× Economics
| Pricing Tier | Gemini 3.1 Pro | GPT-5.5 | Gap |
|---|---|---|---|
| Input (≤200K ctx) | $2.00/1M | $5.00/1M | 2.5× |
| Input (>200K ctx) | $4.00/1M | $5.00/1M | 1.25× |
| Output (≤200K ctx) | $12.00/1M | $30.00/1M | 2.5× |
| Output (>200K ctx) | $18.00/1M | $30.00/1M | 1.67× |
| Cache hit (input) | $0.20/1M | $0.50/1M | 2.5× |
| Batch/Flex | $1.00/$6.00 | $2.50/$15.00 | 2.5× |
| Prompt caching discount | ~90% off input | ~90% off input | ~equal |
Sources: PricePerToken | Metacto | OpenAI API pricing. Batch/Flex = asynchronous processing within 24 hours.
At 100M output tokens/month — a realistic volume for a production agent pipeline — Gemini costs $1,200 vs GPT-5.5's $3,000. With Batch/Flex: $600 vs $1,500. The $900-$2,100 monthly difference funds an entire additional model in your stack.
Feature Comparison
| Feature | Gemini 3.1 Pro | GPT-5.5 |
|---|---|---|
| Release Date | February 19, 2026 | April 23, 2026 |
| Model Class | Google Frontier | OpenAI Frontier |
| Context Window | 1M (2M on API) | 1M |
| Max Output Tokens | 64K | 128K |
| Input Modalities | Text, Image, Audio, Video | Text, Image, Audio, Video |
| Native Image Generation | Yes (integrated) | Yes (GPT Image) |
| Agentic Tools | Antigravity, Google Search | Codex CLI, Computer Use |
| Batch/Flex Pricing | 50% off | 50% off |
| Prompt Caching | 90% off (≤200K) | 90% off |
| API Compatibility | Google Cloud, AI Studio | OpenAI SDK, Azure |
| Code | Proprietary | Proprietary |
Which Model Should You Use?
| Use Case | Winner | Why |
|---|---|---|
| Agentic CLI / DevOps | GPT-5.5 ✅ | +14.2 Terminal-Bench — 82.7% is the bar for unattended terminal work |
| Multi-file Code Review | GPT-5.5 ✅ | +4.4 SWE-bench Pro — better at real GitHub issue resolution |
| MCP Tool Orchestration | GPT-5.5 ✅ | +6.1 MCP Atlas — more reliable chained tool calls |
| Computer Use / Browser | GPT-5.5 ✅ | +2.5 OSWorld, Codex CLI native support |
| Scientific Research | ⚖️ Use Both | GPQA near-tie. Gemini: LiveCodeBench, SciCode. GPT: HLE w/tools. |
| High-Volume (100M+ tok/mo) | Gemini ✅ | 2.5× cheaper at every tier. $900/mo savings funds an additional model. |
| Broad Multimodal (video/audio) | Gemini ✅ | Integrated video+audio native. Google Photos/Workspace integration. |
| Web Research / Browsing | Gemini ✅ | +1.5 BrowseComp, Google Search native |
| Competitive Programming | Gemini ✅ | 2,887 Elo LiveCodeBench Pro leads all published scores |
Conclusion: Different Tools for Different Jobs
This isn't a one-model-wins comparison. GPT-5.5 is the better coding model — full stop. It leads on every shared agentic benchmark: SWE-bench Pro, Terminal-Bench, MCP Atlas, and OSWorld. For teams building production coding agents that run unattended in terminals, GPT-5.5 is the safer pick despite costing 2.5× more.
But Gemini 3.1 Pro is the better value for everything else. At $2/$12 per 1M tokens (vs $5/$30), it's the workhorse you use for high-volume pipelines, document analysis, scientific reasoning, and any workload where raw coding isn't the primary task. Its integrated multimodal capabilities — native video, audio, and image — make it the broader platform. And its LiveCodeBench Pro ranking (2,887 Elo) makes it the better algorithmic coder.
The practical answer for most teams: use both. GPT-5.5 for unattended terminal agents and code review. Gemini 3.1 Pro for scientific reasoning, browsing, and high-volume batch workloads. The right model depends on the job — and the best AI stacks in 2026 run multiple models, not one.
20+ LLMs available on CodingFleet. Test Gemini 3.1 Pro and GPT-5.5 side-by-side on your own code.
📚 Sources & Links
- Google DeepMind — Gemini 3.1 Pro Model Card — official benchmarks
- OpenAI — Introducing GPT-5.5 — official benchmarks and system card
- Vellum — Everything You Need to Know About GPT-5.5 — cross-model comparison tables
- MorphLLM — ChatGPT vs Gemini (June 2026) — pricing and benchmark aggregation
- Nipralo — GPT-5.5 Review 2026 — hands-on multi-model workflow analysis
- Attainment Labs — Founder's Hands-On Review — allocation framework
- MCP Playground — Best AI Model for MCP Tool Calling — MCP Atlas cross-server data
- Artificial Analysis — GPT-5.5 vs Gemini 3.1 Pro — independent speed/intelligence comparison
- PricePerToken — Gemini 3.1 Pro Pricing
- Metacto — Complete Gemini API Pricing
- Suprmind — Gemini Pricing Hub
📖 Read This Next
- Claude Fable 5 — The Complete Review — how the Mythos-class model compares to both
- Claude Fable 5 vs GPT-5.5 — Mythos-class vs GPT-5.5 head-to-head
- GPT-5.4 vs Gemini 3.5 Flash — the mid-tier procurement decision
- SWE-bench Pro Live Leaderboard — every model ranked
- AI Model Pricing Calculator — compare costs at your token volume