
Both are MIT-licensed. Both are Chinese. Both have 1M context. Both are open-weight MoEs targeting developers who want frontier coding without proprietary lock-in. But they're built for completely different brains. GLM-5.2 (Z.ai, June 13): 62.1% SWE-bench Pro — the highest open-weight coding score. Anthropic API compatible. DeepSeek V4 Pro (DeepSeek, April 24): 93.5% LiveCodeBench — #1 of any model globally, closed or open. 3206 Codeforces. 90.1% GPQA Diamond. GLM leads software engineering. DeepSeek dominates algorithms, math, and competitive programming — at 5× cheaper ($0.87 vs $4.40/1M). Full comparison with data from DeepSeek's model card, Z.AI's cross-model table, and independent benchmarks. Test both on CodingFleet.
TL;DR — Key Findings
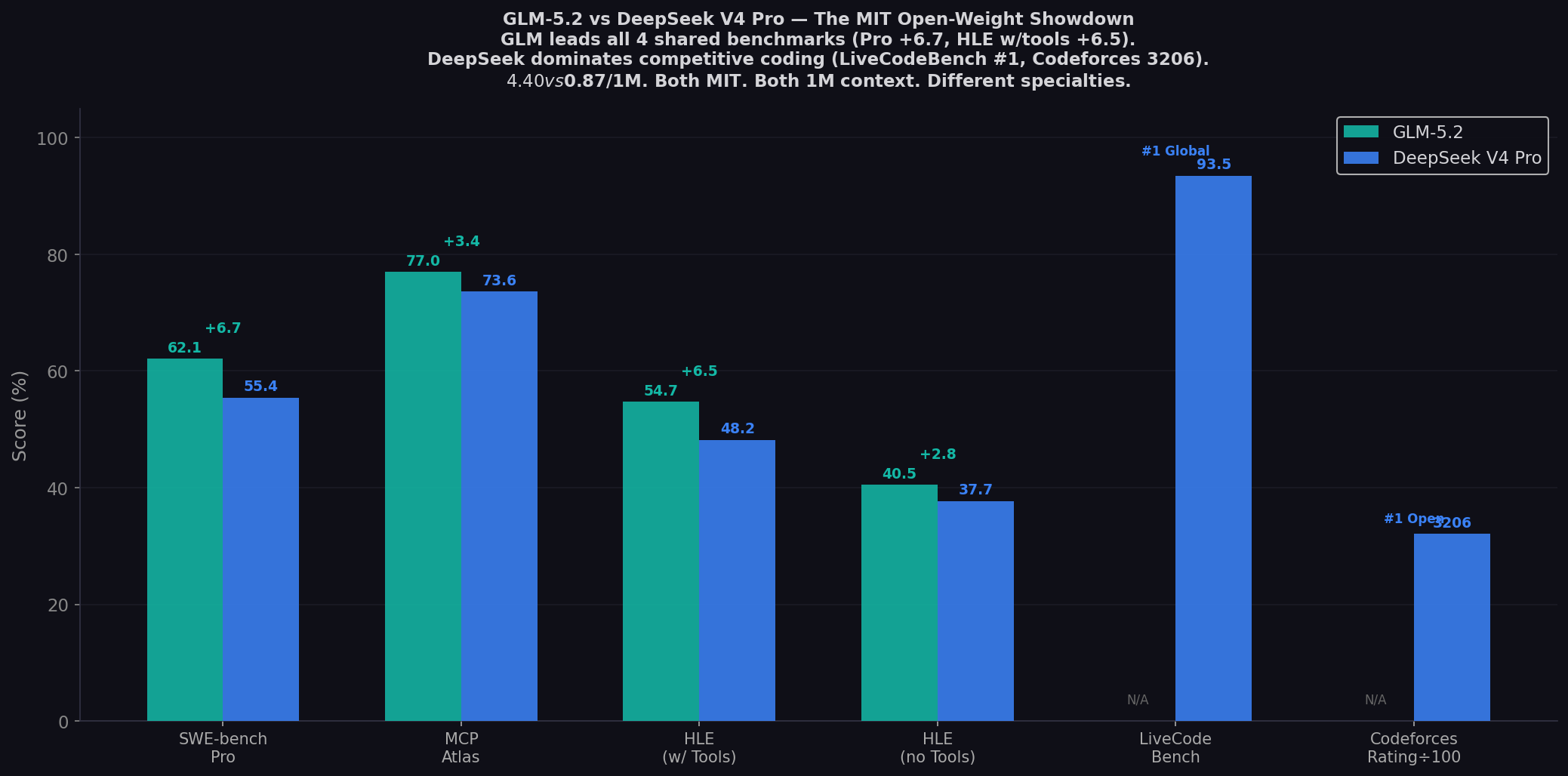
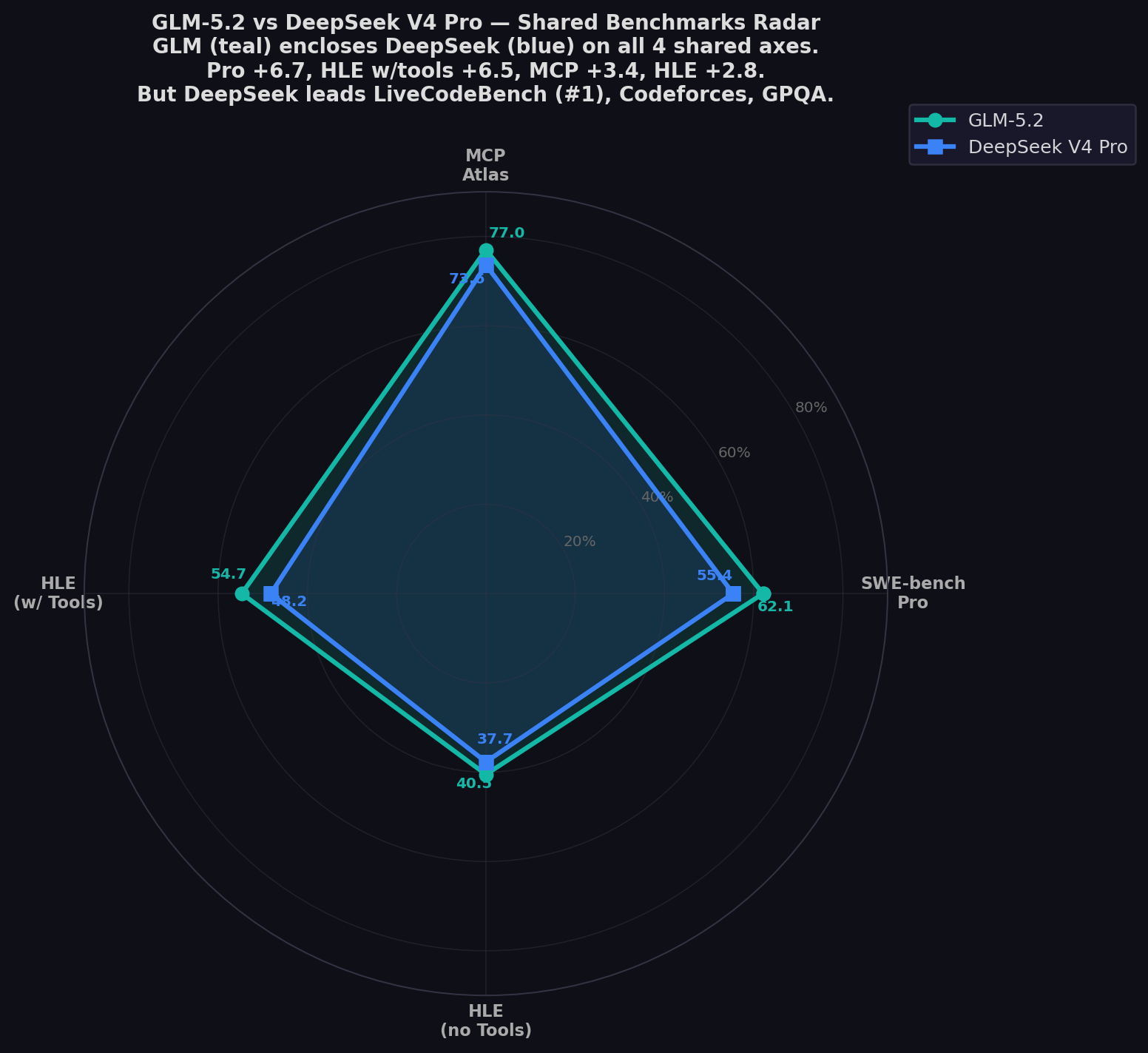
- GLM-5.2 leads all 4 shared benchmarks: Pro (+6.7), HLE w/tools (+6.5), MCP Atlas (+3.4), HLE (+2.8).
- DeepSeek dominates algorithms: LiveCodeBench 93.5% (#1 global), Codeforces 3206, HMMT 95.2%, GPQA 90.1%. GLM hasn't published on these.
- 5× price gap: DeepSeek $0.87/1M vs GLM $4.40/1M. Both offer flat-rate plans (DeepSeek API, GLM Coding Plan $3-80/mo).
- Both MIT license: Both weights on HuggingFace. Both self-hostable. DeepSeek V4 Pro: 1.6T/49B active. GLM-5.2: 753B.
- GLM: Anthropic API compatible (Claude Code native). DeepSeek: dual-mode OpenAI + Anthropic APIs.
- DeepSeek has vision (V4-Pro), GLM is text-only. DeepSeek: multilingual SWE (76.2%), BrowseComp (83.4%), SWE Verified (80.6%).
Try both models on CodingFleet
Benchmark Comparison
| Benchmark | GLM-5.2 | DeepSeek V4 Pro | Winner |
|---|---|---|---|
| SWE-bench Pro ★ | 62.1% | 55.4% | GLM (+6.7) |
| MCP Atlas | 77.0% | 73.6% | GLM (+3.4) |
| HLE (with tools) | 54.7% | 48.2% | GLM (+6.5) |
| HLE (no tools) | 40.5% | 37.7% | GLM (+2.8) |
| SWE-bench Verified | — | 80.6% | DS (highest open-weight) |
| LiveCodeBench | — | 93.5% (#1 GLOBAL) | DS |
| Codeforces Rating | — | 3206 | DS |
| GPQA Diamond | — | 90.1% | DS |
| HMMT 2026 Feb | — | 95.2% | DS |
| BrowseComp | — | 83.4% | DS |
| SWE Multilingual | — | 76.2% | DS |
| MMLU-Pro | — | 87.5% | DS |
| Output Price /1M tok | $4.40 | $0.87 | DS (5.1× cheaper) |
| Input Price /1M tok | $1.40 | $0.435 | DS (3.2× cheaper) |
Sources: GLM-5.2 from Z.AI cross-model table via VentureBeat | DeepSeek V4 Pro from DeepSeek model card, MorphLLM, DeepInfra, Kilo Code. All vendor-reported. Terminal-Bench not compared (GLM 2.1 vs DS 2.0 — different versions).
SWE-bench Pro: The 6.7-Point Software Engineering Edge
The headline for real-world coding. GLM-5.2 at 62.1% vs DeepSeek V4 Pro at 55.4%. A 6.7-point gap on multi-file GitHub issue resolution. Both scores from the Z.AI cross-model table — vendor-reported, same table, directly comparable. MorphLLM notes: "No independent SWE-bench Pro entry exists for DeepSeek V4 on Scale's SEAL leaderboard. The 55.4% figure circulates from vendor-style scaffolds and is unverified by Scale." GLM-5.2 also scores 62.1% from the same vendor table — making the gap apples-to-apples within that reporting framework. For teams where real GitHub issue resolution is the primary metric, GLM-5.2 is the stronger choice.
LiveCodeBench: DeepSeek's #1 Global Crown
DeepSeek V4 Pro at 93.5% on LiveCodeBench — the highest score of any model, open or closed. This benchmark tests competitive programming and algorithmic problem-solving across Codeforces-style problems. No other model — not Claude Fable 5, not GPT-5.5, not Opus 4.8 — has published a higher LiveCodeBench score. Add a 3206 Codeforces rating (the highest open-weight by a wide margin) and 95.2% on HMMT 2026 (Harvard-MIT Math Tournament), and the pattern is clear: DeepSeek V4 Pro is the algorithmic reasoning specialist. DeepInfra: "In maximum reasoning effort mode, V4-Pro-Max competes directly with leading closed-source systems." GLM-5.2 hasn't published LiveCodeBench, Codeforces, or HMMT scores — these capabilities are DeepSeek's uncontested territory.
SWE-bench Verified: DeepSeek's 80.6% — Highest Open-Weight
DeepSeek V4 Pro Max at 80.6% on SWE-bench Verified — tied with Gemini 3.1 Pro as the highest open-weight score. MorphLLM: "DeepSeek-V4-Pro-Max at 80.6% on SWE-bench Verified — the highest open-weights entry, tied with Gemini 3.1 Pro, 0.1 points ahead of MiniMax M3." GLM-5.2 hasn't published a Verified score — Z.ai skipped Verified and went straight to Pro. On Verified (which measures bug-fixing on the original 500-task set), DeepSeek has the proven track record.
Architecture & Ecosystem
| Feature | GLM-5.2 | DeepSeek V4 Pro |
|---|---|---|
| Release Date | June 13, 2026 | April 24, 2026 |
| Developer | Z.ai (Beijing) | DeepSeek (Hangzhou) |
| Parameters | 753B MoE | 1.6T / 49B active MoE |
| Context Window | 1,000,000 tokens | 1,000,000 tokens |
| Max Output | 131,072 tokens | 384,000 tokens |
| License | MIT | MIT |
| API Compatibility | Anthropic native (Claude Code) | Dual-mode OpenAI + Anthropic |
| Modalities | Text only | Text + Vision (V4-Pro) |
| Thinking Modes | High, Max | Non-Think, High, Max (3 modes) |
| Flat-rate access | GLM Coding Plan $3-80/mo | DeepSeek API (permanent 75% discount) |
| Best at | Real-world SWE, long-horizon agents, CLI | Algorithms, math, competitive coding, multilingual |
Which Model Should You Use?
| Use Case | Winner | Why |
|---|---|---|
| Real GitHub issue fixing | GLM ✅ | +6.7 Pro. Better at multi-file bug resolution |
| Competitive programming | DS ✅ | 93.5% LiveCodeBench #1. 3206 Codeforces |
| Advanced mathematics | DS ✅ | 95.2% HMMT, 90.1% GPQA. GLM unpublished |
| Tool orchestration (MCP) | GLM ✅ | +3.4 MCP Atlas. Near Opus 4.8 territory |
| Deep reasoning (HLE) | GLM ✅ | +6.5 HLE w/tools. Better with external tools |
| Budget / high-volume API | DS ✅ | 5× cheaper. $0.87 vs $4.40 per 1M output |
| Claude Code drop-in | GLM ✅ | Anthropic API native. Single env-var switch |
| Multilingual SWE | DS ✅ | 76.2% SWE Multilingual. GLM unpublished |
Conclusion: The SWE Leader vs The Algorithm King
These are the two most important MIT-licensed coding models in existence — and they complement each other perfectly. GLM-5.2 is the software engineering specialist: stronger on real GitHub issues, better at CLI agents, near-frontier on MCP Atlas. DeepSeek V4 Pro is the algorithmic reasoning specialist: #1 globally on LiveCodeBench, 3206 Codeforces, proven on math and multilingual coding — at 5× cheaper. Use GLM-5.2 for your Claude Code agent, long-horizon SWE, and multi-file refactors. Use DeepSeek V4 Pro for algorithmic code generation, high-volume API pipelines, and competitive programming.
⚡ Two MIT Models. One Sandbox.
Run GLM-5.2 and DeepSeek V4 Pro side-by-side on CodingFleet. Compare code quality in real time. Your sandbox keeps running — even when your laptop closes.
🔄 Compare Both Models →Sources & Links
- DeepSeek V4 Pro Model Card (HuggingFace) — all head-to-head benchmark data
- VentureBeat — GLM-5.2 benchmarks vs GPT-5.5, Opus 4.8
- MorphLLM — DeepSeek V4 architecture, benchmarks, API guide
- DeepInfra — DeepSeek V4 Pro model overview and benchmarks
- Codersera — GLM-5.2 vs DeepSeek V4 comparison
- Kilo Code — best open-source coding models 2026
- DeepInfra — DeepSeek V4 Pro pricing guide
Read This Next
- GLM-5.2 vs GPT-5.5 — MIT open-weight beats OpenAI on Pro
- Claude Opus 4.8 vs GLM-5.2 — 0.7 pts from the king
- GLM-5.2 vs MiniMax M3 — coding power vs multimodal versatility