
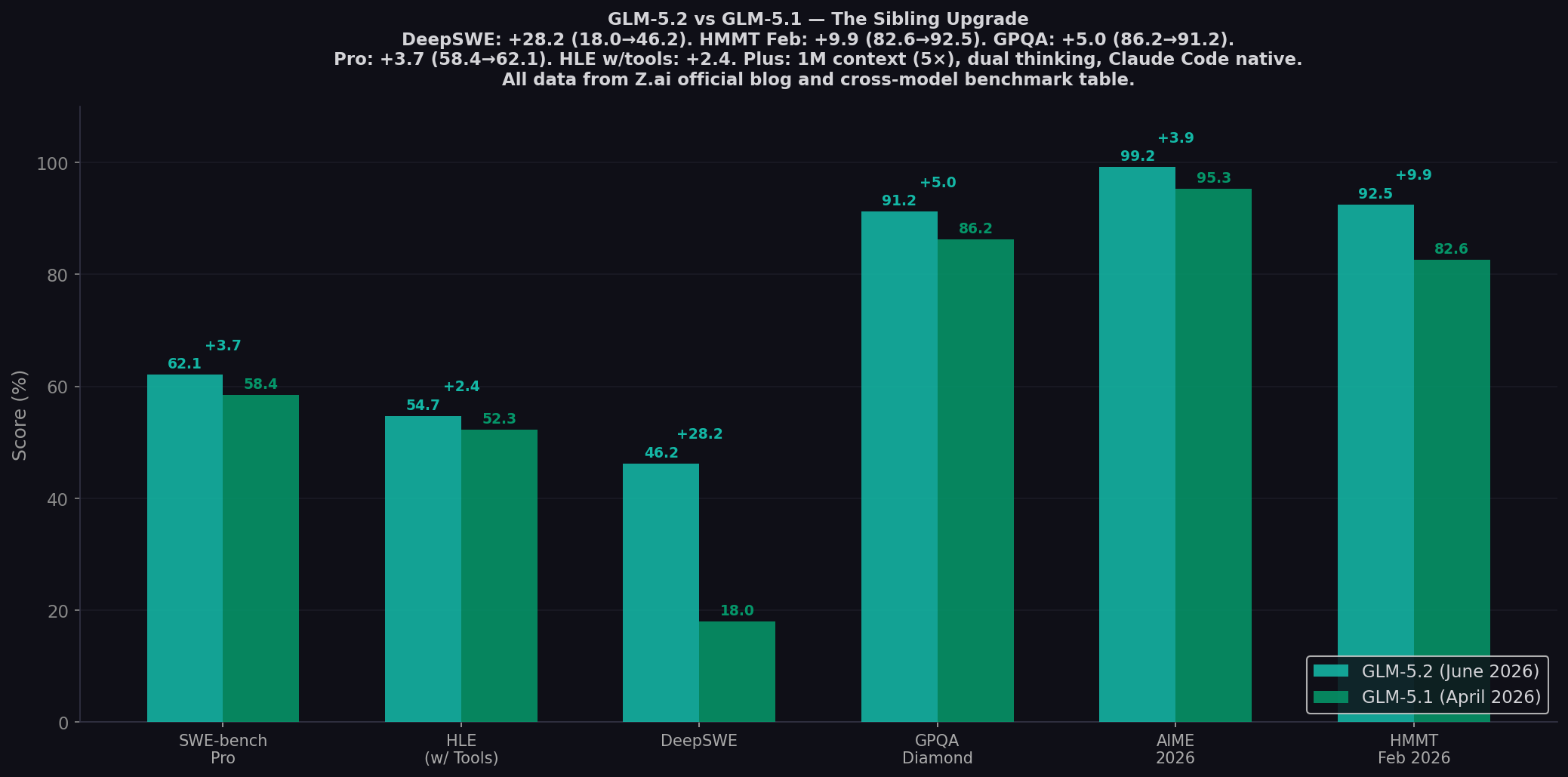
Eleven weeks. That's how long it took Z.ai to go from GLM-5.1 (April 7) to GLM-5.2 (June 13). The model family that started with GLM-5 in February now reaches its third iteration — and this one isn't incremental. DeepSWE jumps from 18.0% to 46.2% (+28.2). HMMT Feb 2026 from 82.6% to 92.5% (+9.9). The context window expands 5× from 200K to 1M tokens. Thinking effort gets a dual-mode system (High / Max). And the Anthropic API compatibility becomes native — drop into Claude Code with a single env-var change. All at the same price. Here's the complete sibling comparison with every benchmark from Z.ai's official launch blog. Test both on CodingFleet.
TL;DR — GLM-5.2 vs GLM-5.1 Upgrades
- DeepSWE +28.2: 18.0% → 46.2%. The biggest gain. Deep software engineering capability more than doubled.
- HMMT Feb 2026 +9.9: 82.6% → 92.5%. Math reasoning leap.
- Context +5×: 200K → 1,000,000 tokens. Handle entire codebases in one session.
- Dual thinking effort: Single mode → High / Max. Cost-vs-depth tradeoff per request.
- GPQA Diamond +5.0: 86.2% → 91.2%. Graduate-level physics reasoning.
- Pro +3.7: 58.4% → 62.1%. The #1 open-weight SWE-bench Pro score.
- Same price: $1.40/$4.40 per 1M. Same MIT license. GLM Coding Plan from $3/mo.
Full Benchmark Comparison
| Benchmark | GLM-5.2 | GLM-5.1 | Gain |
|---|---|---|---|
| DeepSWE | 46.2% | 18.0% | +28.2 |
| CritPt | 16.7 | 4.6 | +12.1 |
| HMMT Feb 2026 | 92.5% | 82.6% | +9.9 |
| HLE (no tools) | 40.5% | 31.0% | +9.5 |
| IMOAnswerBench | 91.0% | 83.8% | +7.2 |
| GPQA Diamond | 91.2% | 86.2% | +5.0 |
| AIME 2026 | 99.2% | 95.3% | +3.9 |
| SWE-bench Pro ★ | 62.1% | 58.4% | +3.7 |
| HLE (with tools) | 54.7% | 52.3% | +2.4 |
| HMMT Nov 2025 | 94.4% | 94.0% | +0.4 (tie) |
Source: All benchmark scores from Z.ai official GLM-5.2 launch blog cross-model comparison table. DeepSWE from Z.AI/VentureBeat data. 100% vendor-reported, directly comparable (same provider, same harness, same evaluation methodology).

DeepSWE: The 28.2-Point Transformation
The most dramatic improvement in the entire GLM-5 lineage. GLM-5.1 at 18.0% on DeepSWE — deep software engineering tasks requiring architectural changes, complex dependency resolution, and multi-file refactors across large codebases. GLM-5.2 at 46.2%. This is not a marginal gain — it's structural. The model went from barely capable at deep engineering to competitive with the frontier. Claude Opus 4.8 scores 58.0% on this benchmark — GLM-5.2 at 46.2% is now within striking distance of the proprietary king on the hardest software engineering tasks. Z.ai's blog: "GLM-5.2 marks a substantial leap in long-horizon task capability." DeepSWE is where that leap is most visible.
Context: 200K → 1M Tokens — The 5× Expansion
GLM-5.1's 200K token context was a limitation — adequate for single-file work but insufficient for repository-scale refactors. GLM-5.2's 1M context handles entire mid-size codebases in a single session. Lushbinary's upgrade guide: "The defining change is the jump from ~200K to a usable 1M-token context window, plus a dual thinking-effort system." Combined with 131,072 max output tokens (up from 120K), the model can both consume and produce larger units of work. For developers working with monorepos or large legacy codebases, this alone justifies the upgrade.
Dual Thinking Effort: High vs Max
GLM-5.1 had a single reasoning mode. GLM-5.2 introduces High and Max levels — the same cost-vs-depth tradeoff that defines frontier models like Claude Opus 4.8 (High / xHigh / Max) and DeepSeek V4 Pro (Non-Think / High / Max). DataCamp's guide: "Z.ai explicitly recommends max effort for coding tasks. The default in a new session maps to high. Higher effort means more deliberate output but also higher latency and token usage." This gives developers control: run High for quick iterations, switch to Max for complex multi-step refactors.
Math Reasoning: GPQA +5.0, HMMT +9.9
The math gains are substantial but uneven. HMMT Feb 2026 jumps from 82.6% to 92.5% (+9.9) — a major improvement on the most recent math competition benchmark. GPQA Diamond from 86.2% to 91.2% (+5.0). AIME 2026 from 95.3% to 99.2% (+3.9) — approaching ceiling. But HMMT Nov 2025 is essentially unchanged (94.0% → 94.4%, +0.4) — suggesting the math improvements are concentrated in harder, more recent benchmarks. BenchLM.ai's comparison: "GLM-5.2 is clearly ahead on the provisional aggregate, 94 to 74. The single biggest benchmark swing is Terminal-Bench 2.0, 63.5% to 81%."
Specification Changes
| Feature | GLM-5.1 | GLM-5.2 |
|---|---|---|
| Released | April 7, 2026 | June 13, 2026 |
| Context Window | ~200,000 tokens | 1,000,000 tokens (5×) |
| Max Output | 120,000 tokens | 131,072 tokens |
| Thinking Modes | Single mode | High, Max (dual) |
| API Compatibility | Z.AI API | Anthropic API native (Claude Code) |
| License | MIT | MIT |
| Pricing (API) | $1.00/$3.20 per 1M | $1.40/$4.40 per 1M |
| Parameters | 754B / 40B active MoE | 753B (MoE) |
Sources: DataCamp — GLM-5.2 spec comparison, Lushbinary upgrade guide, Z.ai official blog. Pricing: GLM-5.1 at $1.00/$3.20 (standard), GLM-5.2 at $1.40/$4.40 (standard). Both available via GLM Coding Plan from $3/mo.
Should You Upgrade?
| If you... | Decision |
|---|---|
| Need 1M context for repo-scale work | ✅ Upgrade. 5× context is the defining reason. |
| Run multi-hour long-horizon agents | ✅ Upgrade. +28.2 DeepSWE. +12.1 CritPt. |
| Use Claude Code or Cline | ✅ Upgrade. Anthropic API native. Drop-in replacement. |
| Do math-heavy coding or formal verification | ✅ Upgrade. +9.9 HMMT. +5.0 GPQA. |
| Are cost-sensitive on API | ⚖️ Stay. GLM-5.1 is $1.00/$3.20 vs $1.40/$4.40. |
| Need proven stability | ⚖️ Stay. GLM-5.1 has 11 weeks of production hardening. |
Conclusion: The Strict Superset
GLM-5.2 is a genuine improvement over GLM-5.1 on every measured benchmark. It's the rare model release where every number goes up — coding, reasoning, math, deep engineering. The context expansion alone (200K → 1M) makes it the practical choice for any developer working with real codebases. The dual thinking effort system brings it to parity with frontier model ergonomics. And it drops into Claude Code with zero config.
The only reasons to stay on GLM-5.1 are cost ($1.00/$3.20 vs $1.40/$4.40 on API) and stability (11 weeks of production hardening vs weeks-old release). For everyone else, GLM-5.2 is the strict superset — and at the same MIT license, same GLM Coding Plan, and same Z.ai ecosystem, the upgrade path is frictionless. Lushbinary's verdict: "If you are already running GLM 5.1, the question is whether the 1M window and the new thinking-effort control are worth a switch." The benchmark data says yes.
🔬 Side-by-Side Test
Run GLM-5.1 and GLM-5.2 on your own code. See the +28.2 DeepSWE improvement in practice. Your sandbox stays alive even when you close your laptop.
🔄 Compare the Siblings →Sources & Links
- Z.ai Official Blog — GLM-5.2: Built for Long-Horizon Tasks (cross-model benchmark table, all shared scores)
- Lushbinary — GLM-5.2 vs GLM-5.1 upgrade guide
- DataCamp — GLM-5.2 features, setup, spec comparison
- BenchLM.ai — GLM-5.1 vs GLM-5.2 comparison
- Lushbinary — GLM-5.1 benchmarks breakdown
- DeepInfra — GLM-5.1 model overview
Read This Next
- GLM-5.2 vs GPT-5.5 — MIT open-weight beats OpenAI on Pro
- Claude Opus 4.8 vs GLM-5.2 — 0.7 pts from the king
- GLM-5.2 vs DeepSeek V4 Pro — SWE leader vs algorithm king