
The open-weight coding crown is separated by 0.4 percentage points. MiniMax M3: 59.0% SWE-bench Pro. Kimi K2.6: 58.6%. That's the difference between #1 and #2 among all open-weight models. But the story isn't the Pro gap — it's the philosophical chasm: M3 brings 1M context, native video input, desktop operation, and $1.20/1M pricing to a model that launched two weeks ago. Kimi K2.6 brings Agent Swarm (300 sub-agents, 4,000 coordinated steps), 54% HLE with tools, and 13-hour proven autonomous runs to a model that's been battle-tested since April. One is the efficiency revolution. The other is the agentic powerhouse. Here's the complete data. Test both on CodingFleet.
📊 Key Findings
- M3 leads SWE-bench Pro by 0.4 points (59.0% vs 58.6%). The #1 and #2 open-weight models on the hardest coding benchmark. Both beat GPT-5.5 (58.6% for Kimi, 59.0% for M3). Both beat GPT-5.4 (57.7%). These are genuine frontier coders.
- Kimi K2.6 dominates reasoning: GPQA +2.5 pts, LiveCode +1.6, HLE 54%. Kimi leads on deep reasoning benchmarks, HLE with tools, and Agent Swarm architecture. For autonomous agents and research-heavy coding, Kimi is structurally stronger.
- M3 is 3.3× cheaper: $1.20 vs $4.00 per 1M output. 1M context window (3.9× larger than Kimi's 256K). Native video/image input. Desktop computer operation. Open-weights promised within 10 days of launch.
- Kimi K2.6 is available now under Modified MIT license. Weights on Hugging Face since April 20. M3 weights promised but not yet shipped. For self-hosting today, Kimi is the only option between these two.
Compare models on your own code at CodingFleet — 20+ LLMs, side-by-side.
Benchmark Comparison
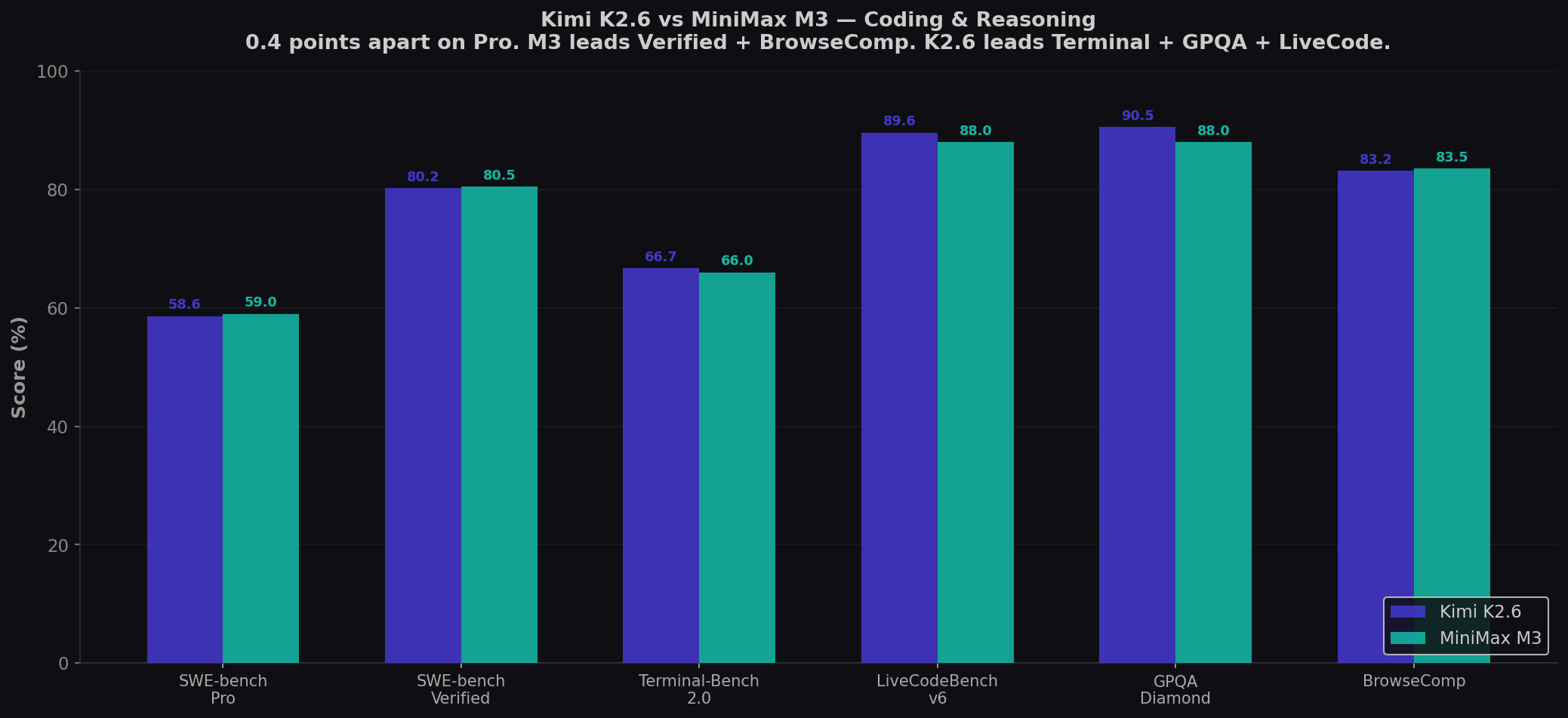
| Benchmark | Kimi K2.6 | MiniMax M3 | Winner |
|---|---|---|---|
| SWE-bench Pro | 58.6% | 59.0% | M3 (+0.4) |
| SWE-bench Verified | 80.2% | 80.5% | M3 (+0.3) |
| Terminal-Bench 2.0 | 66.7% | 66.0% | Kimi (+0.7) |
| LiveCodeBench v6 | 89.6% | ~88.0% | Kimi (+1.6) |
| GPQA Diamond | 90.5% | ~88.0% | Kimi (+2.5) |
| BrowseComp | 83.2% | 83.5% | M3 (+0.3) |
| BrowseComp (Agent Swarm) | 86.3% | — | Kimi |
| HLE-Full (with tools) | 54.0% | — | Kimi |
| OSWorld-Verified | 73.1% | — | Kimi |
| DeepSearchQA (F1) | 92.5% | — | Kimi |
| AIME 2026 | 96.4% | — | Kimi |
| HMMT 2026 Feb | 92.7% | — | Kimi |
| Video SWE-Bench | — | 50.2% | M3 (unique) |
| AA Coding Index | 47.1 | — | Kimi |
| Output Price /1M tok | $4.00 | $1.20 | M3 (3.3× cheaper) |
| Input Price /1M tok | $0.95 | $0.30 | M3 (3.2× cheaper) |
| Context Window | 256K | 1M | M3 (3.9× larger) |
| Weights Available | Yes (Modified MIT) | Promised (10 days) | Kimi |
Sources: FriendliAI — K2.6 Benchmarks; NVIDIA NIM — K2.6; DeepInfra — K2.6 Overview; Lushbinary — M3 Guide; BenchLM — SWE-bench Verified; Kilo Code — Open-Source Rankings. M3 GPQA and LiveCodeBench estimated from vendor comparison tables. M3 HLE, OSWorld not published.
Agentic Coding Radar
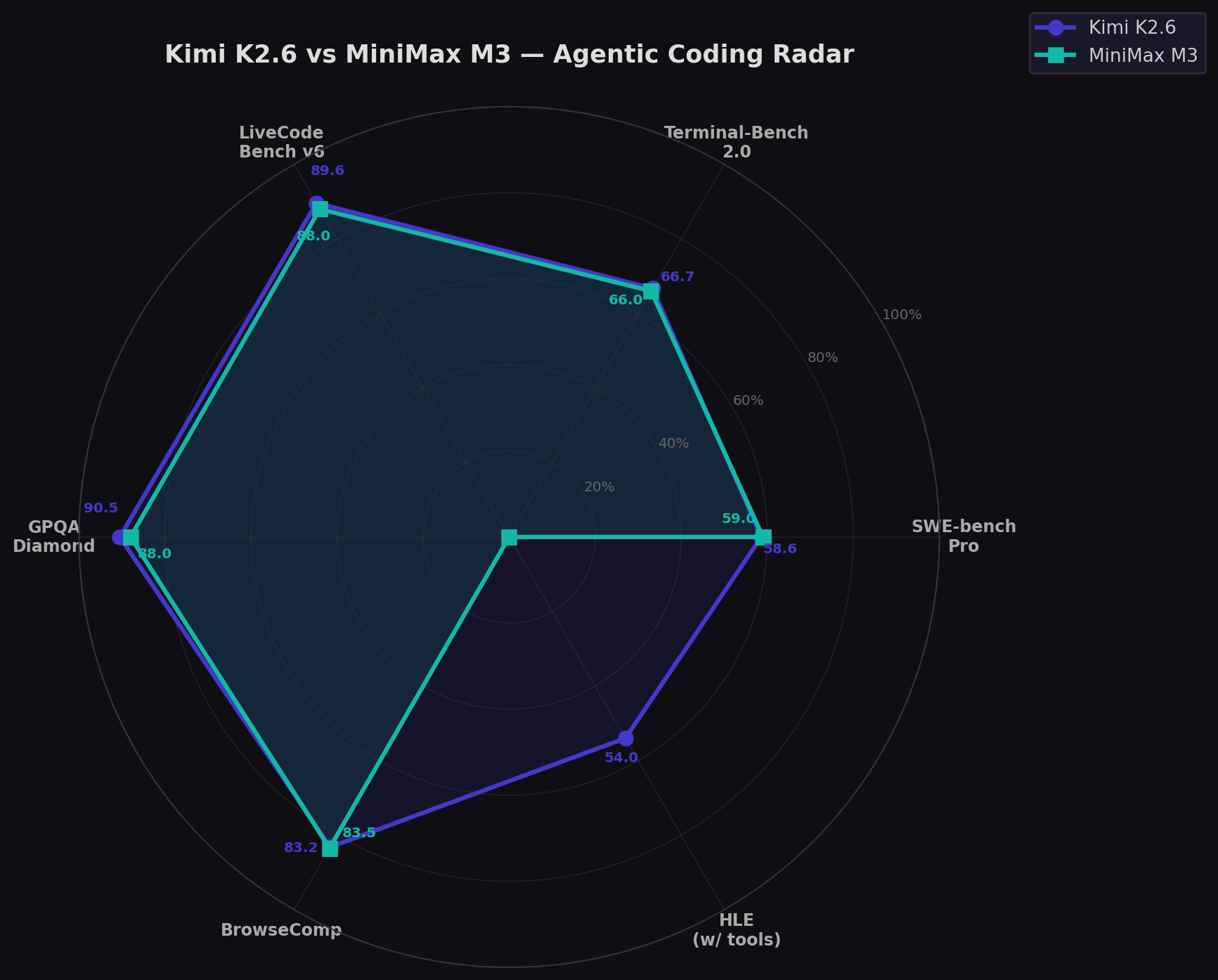
The radar shows two models nearly overlapped — the tightest competition in open-weight AI. Kimi's indigo peak on GPQA, HLE, and LiveCodeBench. M3's teal edge on SWE-bench Pro and BrowseComp. On Terminal-Bench they mirror. On everything measurable, they're within 3 points. This isn't a winner-takes-all comparison. It's two different philosophies achieving the same frontier result.
Architecture & Philosophy
Kimi K2.6: The Agent Swarm Titan
Released April 20, 2026 by Moonshot AI (Beijing). A 1-trillion parameter Mixture-of-Experts with 32B active per token, 256K context window, and a MoonViT 400M vision encoder. The headline innovation: Agent Swarm — scaling to 300 sub-agents executing 4,000 coordinated steps per session. This isn't a benchmark trick. Moonshot shipped a real-world proof: a 13-hour autonomous rewrite of `exchange-core` (an 8-year-old open-source financial matching engine) producing a 185% throughput gain across 4,000+ lines of code and 1,000+ tool calls. They also demonstrated a 12-hour port of Qwen 0.8B inference to Zig on a Mac.
K2.6 supports Thinking and Instant modes with dual OpenAI + Anthropic API compatibility. Weights available on Hugging Face under a Modified MIT license since launch day. Available across 9+ API providers including DeepInfra ($0.75/$3.50), Parasail, Fireworks (~85 tok/s), OpenRouter, and the native Kimi API ($0.95/$4.00). The AA Intelligence Index places K2.6 at 53.9 — #1 among open-weight models at launch. The AA Coding Index is 47.1, edging DeepSeek V4 Pro by 0.4 points in a near-tie for top open-source coding spot.
MiniMax M3: The Efficiency Revolution
Released June 1, 2026 — just six days ago. M3 introduces MiniMax Sparse Attention (MSA), a fundamentally new attention architecture that partitions KV caches into blocks more precisely than prior sparse approaches. The "KV outer gather Q" operator-level optimization reads each block only once with contiguous memory access — 4× faster than open-source Flash-Sparse-Attention under M3's head configuration. This makes 1M-token context practical rather than theoretical. The M2 series had removed sparse attention entirely. M3 brings it back in a new form optimized for long-context agentic work.
M3 supports native desktop computer operation — controlling mouse and keyboard to interact with applications directly. No other open-weight model offers this. Combined with native video/image input, M3 can watch a screen recording of a bug, generate the fix, and test the UI — all within a single session. Video SWE-Bench 50.2% is a category M3 created. Model weights and technical report are promised within 10 days of the June 1 launch. Pricing is aggressive: $0.30/$1.20 per 1M tokens (promotional).
Where Each Model Wins
Kimi K2.6 — The Agentic Powerhouse
- Agent Swarm: 300 sub-agents, 4,000 steps. No other model — open or closed — matches this orchestration scale. For codebase migrations, multi-repo refactors, and autonomous engineering campaigns, Kimi can coordinate work across hundreds of parallel agents. See our DeepSeek V4 Pro vs Kimi comparison.
- HLE with tools: 54.0%. Leads all frontier models on Humanity's Last Exam with tools — ahead of GPT-5.4 (52.1%), Claude Opus 4.6 (53.0%), and Gemini 3.1 Pro (51.4%). For research-heavy coding that requires tool use, Kimi is the best open-weight model.
- GPQA Diamond 90.5% — +2.5 over M3. For scientific coding, ML engineering, and quantitative development, Kimi's reasoning advantage is measurable.
- DeepSearchQA 92.5% F1. For coding tasks that require web research, documentation lookup, and cross-referencing, Kimi's search capability is best-in-class among open models.
- Proven 13-hour autonomous runs. Not a vendor claim — a demonstrated real-world result. The exchange-core rewrite is public. For teams deploying autonomous coding agents, proven runtime matters more than benchmark claims.
MiniMax M3 — The Multimodal Value King
- 59.0% SWE-bench Pro — #1 open-weight. The highest score of any model with freely available weights. For practical bug fixing in Python repos, M3 is the best open-weight model available — at 3.3× lower cost than Kimi.
- 1M context window — 3.9× larger than Kimi's 256K. For full-codebase analysis, processing entire repositories without chunking, and maintaining coherence across very long coding sessions, M3's context advantage is decisive.
- Desktop computer operation. M3 can control a mouse and keyboard. For end-to-end testing, GUI automation, and legacy system integration, this is a capability no other open-weight model offers.
- Video/code input: screenshots, diagrams, video walkthroughs. Code from anything. Send a screen recording of a bug, get the fix. Send an architecture diagram, get the implementation. Video SWE-Bench 50.2% is a category M3 created.
- $1.20/1M output — 3.3× cheaper than Kimi. At scale, the economics are transformative. A CI/CD pipeline generating tests for every commit costs pennies. Batch refactoring across a codebase costs less than a coffee.
- 83.5 BrowseComp. Surpasses Claude Opus 4.7 on autonomous browsing. M3 navigates the web, reads documentation, and incorporates findings into code — all within a single session.
Pricing & Availability
| Detail | Kimi K2.6 | MiniMax M3 |
|---|---|---|
| Input (per 1M tokens) | $0.95 (Kimi API) | $0.30 (promo) |
| Output (per 1M tokens) | $4.00 (Kimi API) | $1.20 (promo) |
| Cheapest provider input | $0.60 (Parasail) | $0.30 |
| Cheapest provider output | $2.50 (Moonshot native) | $1.20 |
| License | Modified MIT (available now) | Open-weights promised (10 days) |
| Self-hosting | Yes, weights on Hugging Face | Coming soon |
| Providers | 9+ (DeepInfra, Fireworks, OpenRouter, etc) | MiniMax API + OpenRouter |
| Speed (AA throughput) | ~85 tok/s (Fireworks) | ~45 tok/s (est) |
When to Use Which
| Scenario | Use | Why |
|---|---|---|
| Autonomous agent swarms / multi-agent | Kimi K2.6 | 300 sub-agents, 4,000 steps. No equivalent exists. |
| Research-heavy coding (tool use) | Kimi K2.6 | 54% HLE with tools. #1 among all frontier models. |
| Scientific / ML / quantitative coding | Kimi K2.6 | 90.5% GPQA. 96.4% AIME. Math/reasoning leader. |
| Self-hosting today | Kimi K2.6 | Weights available now. M3 weights promised but not yet. |
| Speed-sensitive deployments | Kimi K2.6 | ~85 tok/s on Fireworks. ~2× faster than M3. |
| Maximum Pro score (bug fixing) | MiniMax M3 | 59.0% #1 open-weight. 0.4 pts ahead of Kimi. |
| Full-codebase analysis (1M context) | MiniMax M3 | 1M context vs 256K. 3.9× larger window. |
| Code from screenshots/video | MiniMax M3 | Video SWE-Bench 50.2%. Desktop operation. |
| Cost-sensitive high-volume coding | MiniMax M3 | $1.20 vs $4.00. 3.3× cheaper output. |
| Desktop GUI automation / testing | MiniMax M3 | Only open-weight model with computer operation. |
Conclusion: Two Crowns, One Throne
Kimi K2.6 and MiniMax M3 are the two best open-weight coding models in the world — and they're separated by 0.4 points on the benchmark that matters most. The choice isn't about which is better. It's about which philosophy fits your workflow.
Kimi K2.6 is the agentic titan. Agent Swarm, HLE leadership, proven 13-hour autonomous runs, available weights today, 9+ providers. For teams building autonomous coding agents, multi-repo orchestration, and research-heavy development, Kimi is the open-weight model to beat.
MiniMax M3 is the efficiency revolution. #1 Pro score, 1M context, native video, desktop operation, 3.3× cheaper. For teams maximizing coding performance per dollar, processing entire codebases, and generating code from visual inputs, M3 is the smarter economic choice — once the weights ship.
The open-weight frontier has never been this competitive. Six months ago, no open model scored above 50% on SWE-bench Pro. Today, two models are at 59% — both beating GPT-5.5. The gap between open and closed is now measured in single digits. That's the real story.
20+ LLMs available. Side-by-side testing. Both models ready.
Sources: FriendliAI — K2.6 Benchmarks | NVIDIA NIM — K2.6 Model Card | DeepInfra — K2.6 Architecture | Miraflow — K2.6 Explained | Lushbinary — M3 Developer Guide | Kilo Code — Open-Source Rankings | BenchLM — SWE-bench Verified | Handy AI — K2.6 Model Drop.