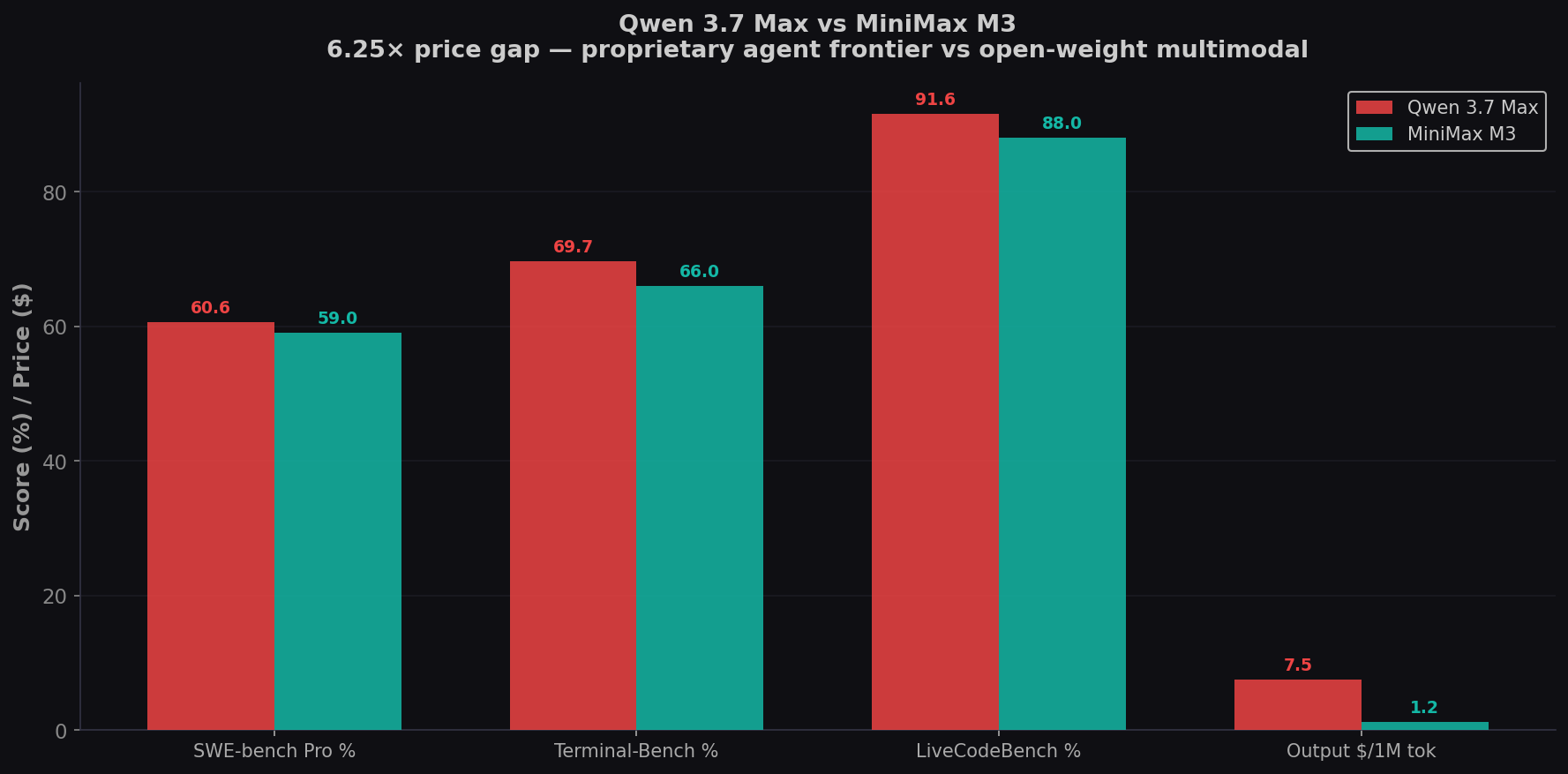
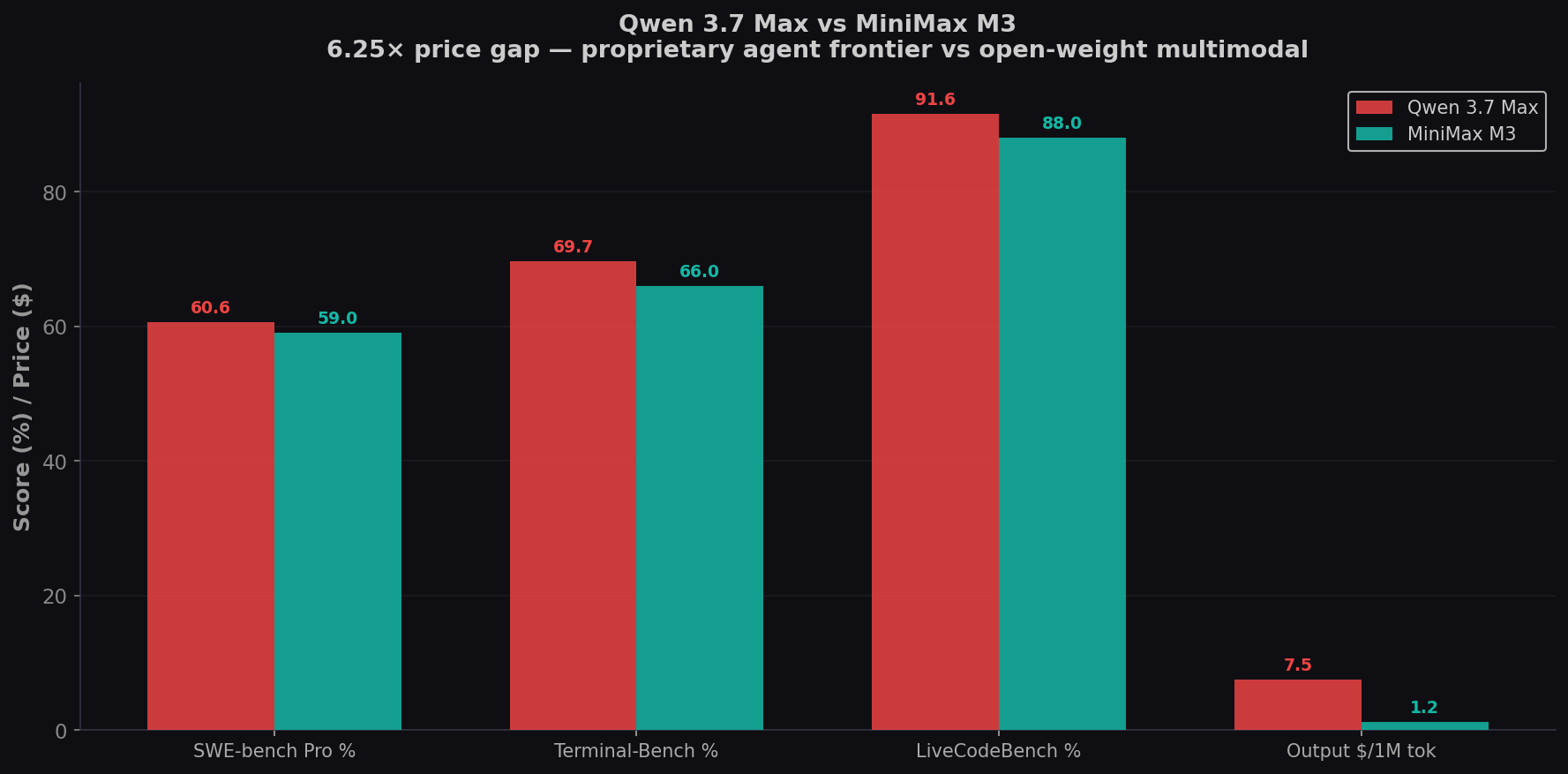
Qwen 3.7 Max calls itself the "Agent Frontier" — and the numbers back it up. 60.6% on SWE-bench Pro, the highest proprietary score on the benchmark (edging GPT-5.5 at 58.6%). It can run autonomously for up to 35 hours with 1,000+ sequential tool calls. MiniMax M3 scores 59.0% — just 1.6 points behind — but adds native video/image input and costs 6.25× less ($1.20 vs $7.50 per 1M output). One is a proprietary agent powerhouse from Alibaba with Anthropic API compatibility. The other is an open-weight multimodal challenger. Both launched within two weeks of each other. Here's the complete coding comparison. Try both on CodingFleet.
📊 Key Findings
- Razor-thin margins on coding benchmarks. Qwen leads by 1.6 points on SWE-bench Pro (60.6% vs 59.0%) and 3.7 on Terminal-Bench (69.7% vs 66.0%). Both edge GPT-5.5. For practical coding, they're functionally tied.
- Qwen dominates STEM reasoning: GPQA Diamond 92.4%, HMMT 97.1%, Apex 44.5. For scientific computing, ML engineering, and quantitative finance, Qwen's reasoning advantage is structural.
- M3 is multimodal — text, image, video input + desktop operation. Qwen is text-only. For code from screenshots, diagrams, or video walkthroughs, M3 is the only choice. Qwen 3.7 Plus adds multimodality but is a different model.
- M3 costs $1.20/1M (promo) vs Qwen at $7.50. Open-weights promised vs proprietary API-only. 6.25× cheaper — and once weights ship, M3 can be self-hosted. Qwen requires Alibaba Cloud.
Compare models on your own code at CodingFleet — 20+ LLMs, side-by-side.
Benchmark Comparison
| Benchmark | Qwen 3.7 Max | MiniMax M3 | Winner |
|---|---|---|---|
| SWE-bench Pro | 60.6% | 59.0% | Qwen (+1.6) |
| Terminal-Bench 2.0 | 69.7% | 66.0% | Qwen (+3.7) |
| LiveCodeBench | 91.6% | ~88% | Qwen (+3.6) |
| GPQA Diamond | 92.4% | ~88% | Qwen (+4.4) |
| HMMT 2026 Feb | 97.1% | — | Qwen |
| MCP-Atlas | 76.4% | — | Qwen |
| Kernel Bench L3 (speedup) | 1.98× (96% WR) | — | Qwen |
| BrowseComp | — | 83.5 | M3 |
| Video SWE-Bench | N/A (text-only) | 50.2% | M3 (unique) |
| Output Price /1M tok | $7.50 | $1.20 | M3 (6.25×) |
| Context Window | 1M | 1M (512K min) | Tie |
| Max Output | 65,536 tokens | — | Qwen |
| Autonomous Runtime | Up to 35 hours | — | Qwen |
| Weights | Proprietary (API-only) | Open-weights (promised) | M3 |
| Multimodal Input | Text only | Text + Image + Video | M3 |
| Desktop Operation | No | Yes | M3 |
Sources: Yotta Labs — Qwen 3.7 Max; Overchat — Qwen vs Rivals; VentureBeat — Qwen 3.7 Max; Lushbinary — M3 Guide. Qwen scores are vendor-published.
Architecture & Ecosystem
Qwen 3.7 Max: The Agent Powerhouse
Qwen 3.7 Max is built for long-horizon autonomous execution. Alibaba reports up to 35 hours of continuous autonomous operation with 1,000+ sequential tool calls. The model is designed for "cross-harness generalization" — rather than being optimized for a specific agent framework, it works as a drop-in intelligence layer across diverse harnesses. The headline feature: native Anthropic API protocol support. You can point Qwen 3.7 Max at Claude Code, OpenClaw, or any tool that speaks the Anthropic Messages API, and it works. Set `ANTHROPIC_MODEL="qwen3.7-max"`, configure the base URL, and Qwen slots into your existing Anthropic ecosystem.
This is a strategic move. Rather than building a competing agent platform (like Codex or Claude Code), Qwen makes itself compatible with the ones developers already use. For teams invested in Claude Code but wanting a higher Pro score at lower cost, Qwen 3.7 Max is a drop-in upgrade. The model also supports the OpenAI API spec. On Kernel Bench L3, Qwen achieves 1.98× median kernel speedup with a 96% win rate — meaning it can optimize low-level code competitively with Opus 4.6.
MiniMax M3: Multimodal, Open, and Self-Hostable
M3's MiniMax Sparse Attention (MSA) partitions KV caches into blocks more precisely than prior approaches, with a "KV outer gather Q" optimization that's 4× faster than open-source Flash-Sparse-Attention. This makes 1M-token context practical rather than theoretical. M3 also supports native desktop computer operation — controlling mouse and keyboard to interact with applications directly. No other open-weight model offers this.
The open-weights promise (within 10 days of June 1 launch) means M3 will be self-hostable. For enterprises that need data sovereignty but want frontier coding + video understanding, M3 will be the only option. The MSA architecture is a generational change from the M2 series, which had removed sparse attention. M3 brings it back in a fundamentally new form optimized for long-context agentic work.
Coding Deep-Dive
Qwen 3.7 Max — The Agent Powerhouse
- Highest proprietary SWE-bench Pro (60.6%). Resolves more real-world GitHub issues than any other API-only model. For bug fixing in Python repositories, Qwen is at the frontier — ahead of GPT-5.5.
- 35-hour autonomous runs. 1,000+ sequential tool calls without intervention. For multi-day engineering tasks — migrations, refactors, testing campaigns — Qwen can work while you sleep.
- Anthropic API compatibility. Drop Qwen into Claude Code, Continue, Aider, or any Anthropic-compatible tool. No migration. No new tooling. Just swap the model ID and endpoint. See our Qwen 3.7 Max vs GPT-5.5 comparison.
- STEM powerhouse. 92.4% GPQA Diamond, 97.1% HMMT, 44.5 Apex. For scientific computing, ML engineering, and quantitative development, Qwen's reasoning advantage over M3 is real and measurable.
MiniMax M3 — The Multimodal Value Play
- 59.0% Pro at $1.20/1M — 6.25× cheaper than Qwen. Only 1.6 points behind on the hardest coding benchmark. For practical purposes, the coding quality is equivalent — at a fraction of the cost.
- Code from anything. Screenshots, architecture diagrams, video walkthroughs — M3 generates code from all three. Desktop operation capability means M3 can also test the UI it generates. Video SWE-Bench 50.2% is a category M3 created.
- BrowseComp 83.5. Surpasses Claude Opus 4.7 on autonomous browsing. M3 can research documentation, read API references, and incorporate findings into code — all within a single session.
- Open-weights + MSA efficiency. Once weights ship, self-host on your own GPUs. The sparse attention mechanism means 1M-token context is truly usable. For cost-sensitive, high-volume coding pipelines, M3's economics are unbeatable.
When to Use Which
| Scenario | Use | Why |
|---|---|---|
| Maximum coding benchmark scores | Qwen 3.7 Max | 60.6% Pro. Highest proprietary score. |
| STEM-heavy coding (scientific, ML) | Qwen 3.7 Max | 92.4% GPQA, 97.1% HMMT, 44.5 Apex. |
| Anthropic API ecosystem users | Qwen 3.7 Max | Drop-in Claude Code replacement. |
| Multi-day autonomous tasks | Qwen 3.7 Max | 35-hour continuous runs. 1,000+ tool calls. |
| Code from screenshots/video | MiniMax M3 | Only model with video + 59% Pro. |
| Desktop GUI automation | MiniMax M3 | Native computer operation capability. |
| Cost-sensitive deployment | MiniMax M3 | $1.20 vs $7.50. 6.25× cheaper. |
| Self-hosting (when weights ship) | MiniMax M3 | Open-weights promised. Qwen is API-only. |
Bottom line: On pure text coding, Qwen 3.7 Max wins — but the margins are razor-thin. M3's 6.25× price advantage, native multimodality, and promised open weights make it the smarter pick for most teams. Use Qwen when you need every last point of benchmark performance, when you're running multi-day autonomous tasks, or when you want a drop-in Claude Code upgrade. For everything else, M3 delivers equivalent coding quality at a fraction of the cost.
20+ LLMs available. Side-by-side testing.
Sources: Yotta Labs — Qwen 3.7 Max | VentureBeat — Qwen 3.7 Max | Overchat — Qwen vs Rivals | Qwen — Claude Code Integration | Lushbinary — M3 Guide | MiniMax — M3 Official.