
On May 19, 2026, Alibaba dropped a bombshell at the Alibaba Cloud Summit in Hangzhou. Qwen 3.7 Max — branded "The Agent Frontier" — claimed to beat Claude Opus 4.6 on SWE-bench Pro (60.6% vs 57.3%), Terminal-Bench (69.7% vs 65.4%), SciCode (53.5% vs 51.9%), and MCP Atlas (76.4% vs 75.8%). It launched at $2.50 input / $7.50 output per 1M tokens — half of Claude Opus on input and less than a third on output. But the real story isn't whether it beats Opus 4.6. It's whether it threatens Opus 4.8 and GPT-5.5 — and what its closed-weight, API-only strategy means for developers. Test Qwen 3.7 Max alongside every other model on CodingFleet's AI Chat.
📊 Key Findings
- Qwen 3.7 Max is the highest-ranked Chinese model on the AA Intelligence Index (56.6) — tied with Claude Opus 4.7 (57.3) and ahead of Kimi K2.6 (54), DeepSeek V4 Pro (52), and GLM-5.1 (51.4).
- It beats GPT-5.5 on SWE-bench Pro (60.6% vs 58.6%), LiveCodeBench (91.6% vs 56%), and SciCode (53.5% vs not published). GPT-5.5 still leads Terminal-Bench (78.2% vs 69.7%).
- It trails Claude Opus 4.8 by 8.6 points on SWE-bench Pro but costs 3.3× less. The gap is real — but so is the cost advantage.
- Anthropic API compatible. You can point Claude Code directly at the Qwen endpoint as a drop-in replacement. No harness changes needed.
- Not open-weight. Qwen 3.7 Max is proprietary and API-only. This is a strategic choice — compete on capability at mid-tier pricing, not on openness at cost-floor pricing.
- The verbosity tax is real. Qwen generated 97M tokens on the AA Intelligence Index evaluation — 4× the 24M-token average. Per-token prices understate actual costs on long agentic runs.
🚀 Qwen on CodingFleet: Two Tiers of Access
Both Qwen models are available on CodingFleet — but with different pricing:
- Qwen 3.6 Plus — Unlimited. The Unlimited plan gives you unrestricted access to Qwen 3.6 Plus with no weekly, daily, or hourly quotas. A strong everyday coding model at flat rate.
- Qwen 3.7 Max — 3 credits per 20K tokens. The flagship "Agent Frontier" model costs 3 credits per 20K output tokens. The Unlimited plan includes 600 credits per week, giving you roughly 4M output tokens/week of Qwen 3.7 Max — plenty for agentic coding sessions, but worth being aware of.
Given Qwen 3.7 Max's verbosity (4× the tokens of other models), the credit cost adds up on long runs. For heavy volume work, pair it with DeepSeek V4 Pro or MiniMax M2.7 as a cheaper backbone.
Want to test Qwen 3.7 Max against Opus 4.8 and GPT-5.5 on your own code? All three models are available on CodingFleet. Start a new chat →
What Is Qwen 3.7 Max?
Qwen 3.7 Max is Alibaba's flagship proprietary reasoning model, announced May 19, 2026 at the Alibaba Cloud Summit in Hangzhou. The Qwen team calls it "The Agent Frontier" — and the entire release is framed around long-horizon autonomous execution, not general chat.
| Spec | Qwen 3.7 Max | Claude Opus 4.8 | GPT-5.5 |
|---|---|---|---|
| Release Date | May 19, 2026 | May 28, 2026 | April 23, 2026 |
| Context Window | 1M tokens | 1M tokens | 1M tokens |
| Max Output | 65,536 tokens | 128K tokens | 100K tokens |
| Input Price | $2.50/1M | $5.00/1M | $5.00/1M |
| Cached Input | $0.25/1M | $1.25/1M | $2.50/1M |
| Output Price | $7.50/1M | $25.00/1M | $30.00/1M |
| OpenRouter Price | $1.25 / $3.75 | — | — |
| Open-Weight? | No — API Only | No | No |
| Multimodal? | Text only | Vision + Text | Omnimodal |
| API Protocol | OpenAI + Anthropic | Anthropic only | OpenAI only |
The key differentiator: Qwen 3.7 Max speaks both API protocols. You can point Claude Code, OpenClaw, or any Anthropic-compatible harness directly at the Qwen endpoint as a drop-in replacement. No code changes. This is a strategic masterstroke — it piggybacks on Anthropic's entire agent ecosystem.
Benchmark Comparison: Qwen 3.7 Max vs The Flagships
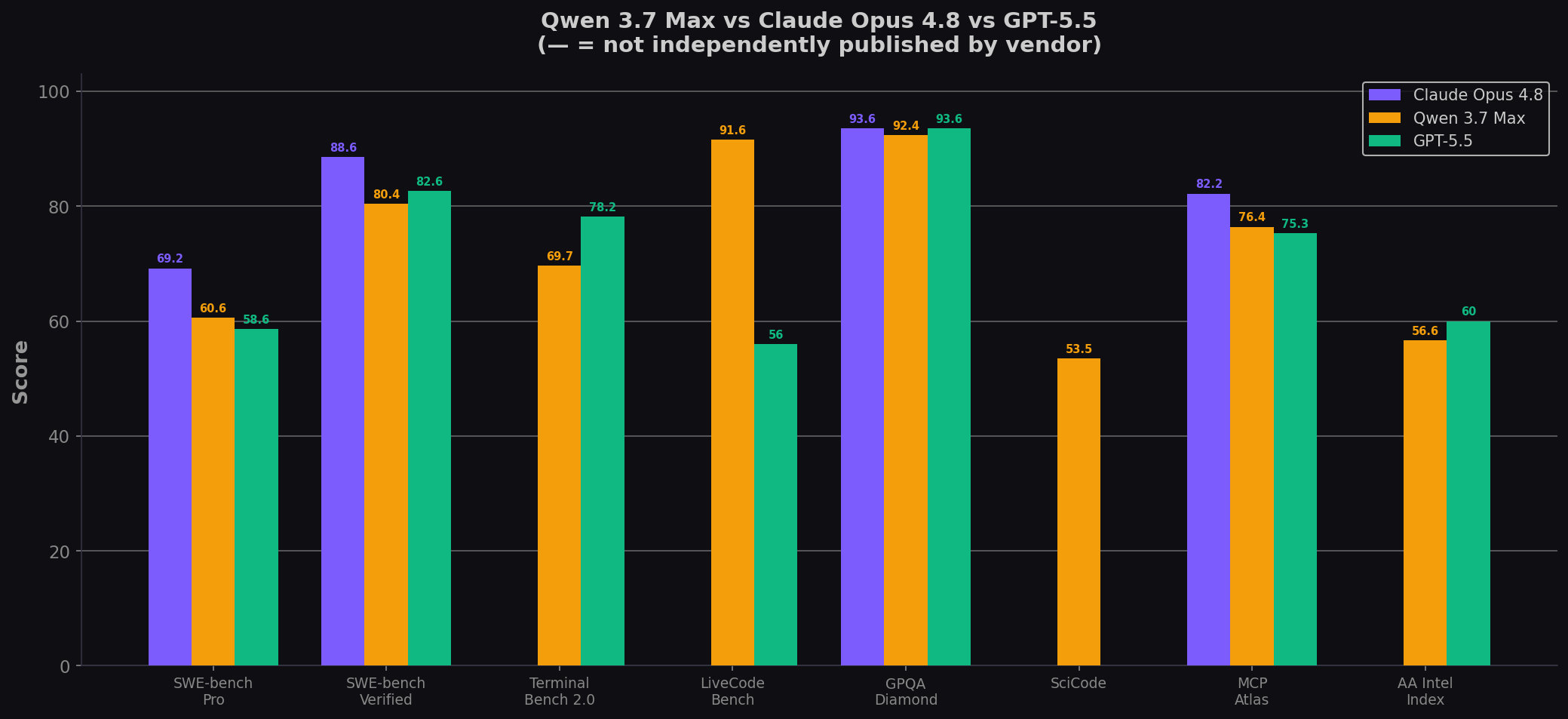
| Benchmark | Qwen 3.7 Max | Claude Opus 4.8 | GPT-5.5 | Best |
|---|---|---|---|---|
| SWE-bench Pro ★ | 60.6% | 69.2% | 58.6% | Opus 4.8 |
| SWE-bench Verified ⚠️ | 80.4% | 88.6% | 82.6% | Opus 4.8 |
| SWE-bench Multilingual | 78.3% | 84.4% | — | Opus 4.8 |
| Terminal-Bench 2.0 | 69.7% | — | 78.2% | GPT-5.5 |
| LiveCodeBench | 91.6% | — | 56% | Qwen 3.7 Max |
| SciCode | 53.5% | — | — | Qwen 3.7 Max |
| GPQA Diamond | 92.4% | 93.6% | 93.6% | Tie |
| HLE (no tools) | 41.4% | 49.8% | 41.4% | Opus 4.8 |
| MCP-Atlas | 76.4% | 82.2% | 75.3% | Opus 4.8 |
| MCP-Mark | 60.8% | — | — | Qwen 3.7 Max |
| BFCL-V4 | 75.0% | — | — | Qwen 3.7 Max |
| NL2Repo | 47.2% | — | — | Qwen 3.7 Max |
| AA Intelligence Index | 56.6 | — | 60.3 | GPT-5.5 |
| HMMT 2026 Feb | 97.1% | — | — | Qwen 3.7 Max |
Sources: Qwen 3.7 official blog; Overchat AI analysis; Anthropic Opus 4.8 system card; OpenAI GPT-5.5 announcement. — = not independently published by vendor.
Where Qwen 3.7 Max Actually Beats the Flagships
The narrative that "Chinese models are almost as good for less money" is too simple. Qwen 3.7 Max has genuine leadership positions on several benchmarks:
LiveCodeBench (91.6%) — The Algorithmic Lead
Qwen 3.7 Max scores 91.6% on LiveCodeBench — 35.6 points ahead of GPT-5.5 (56%). This is the second-highest score of any model after DeepSeek V4 Pro (93.5%). For competitive programming, algorithm implementation, and LeetCode-style problem solving, Qwen is in elite territory. DeepSeek V4 Pro still leads at 93.5%, but Qwen's 91.6% puts it ahead of every proprietary flagship.
SciCode (53.5%) — The Scientific Computing Lead
Qwen 3.7 Max's 53.5% on SciCode doubles the previous best score (Gemini 3.1 Pro at 26.2%). This is a staggering result. SciCode — from Lawrence Berkeley National Lab — tests real scientific Python implementations (NumPy, SciPy, physics simulations). If Qwen's score holds under independent verification, it represents a breakthrough in scientific computing AI. See our Python coding comparison for context on why SciCode matters.
NL2Repo (47.2%) — The Repository Generation Lead
NL2Repo tests whether a model can generate an entire repository from a natural language description — not just fix a bug, but build from scratch. Qwen's 47.2% leads Opus 4.6 (47.6% — essentially tied) and beats Kimi K2.6 (42.8%) and DeepSeek V4 Pro (35.5%).
The Agent Suite: MCP-Mark (60.8%), BFCL-V4 (75.0%)
Qwen 3.7 Max leads on MCP-Mark (60.8% vs GLM-5.1's 57.5%) and BFCL-V4 (75.0%). These test tool-use and function-calling — the core of agentic coding. Qwen's "Agent Frontier" branding isn't marketing fluff.
The Verbosity Tax: Qwen's Hidden Cost
Artificial Analysis observed something critical during their Intelligence Index evaluation: Qwen 3.7 Max generated approximately 97 million tokens to complete the benchmark — roughly 4× the 24 million-token average across all models.
This changes the cost equation completely. At $7.50/1M output tokens, Qwen looks 3.3× cheaper than Claude Opus 4.8 ($25.00). But if Qwen generates 4× more tokens for the same task, the effective cost per task becomes:
| Model | Output $/1M | Relative Verbosity | Effective Cost/Task |
|---|---|---|---|
| DeepSeek V4 Pro | $0.87 | ~1.5× | Lowest |
| MiniMax M2.7 | $1.20 | ~1.2× | Very low |
| Qwen 3.7 Max | $7.50 | ~4× | Medium-high |
| Claude Opus 4.8 | $25.00 | ~1.0× (baseline) | High |
| GPT-5.5 | $30.00 | ~1.0× | Highest |
Verbosity estimates from Artificial Analysis benchmark data and vendor system cards. Actual task-level costs depend heavily on workflow.
The bottom line: Qwen's per-token price advantage shrinks significantly when you account for its reasoning verbosity. For long agentic runs, DeepSeek V4 Pro ($0.87/1M, less verbose) may actually be cheaper and more predictable. Read our heavy user's AI coding stack guide for the full cost analysis.
The Tetris Bot Experiment: Qwen Beats Both Flagships in the Real World
A Reddit experiment tested three frontier models on a real agentic task: write a Tetris bot that plays and trains itself across 10 iterations. Each model could read its own code, run benchmarks, and rewrite itself:
| Model | Training Cost | Bot Improvement | Cost per % Improvement |
|---|---|---|---|
| Qwen 3.7 Max | $1.32 | +56% | $0.024 |
| Claude Opus 4.7 | $12.15 | +28% | $0.434 |
| GPT-5.5 | $2.85 | +7% | $0.407 |
Qwen won on every dimension: biggest jump (+56%), 9× cheaper than Claude, and 18× more cost-effective per improvement point than GPT-5.5. The experiment is small (one task, one run) but directionally consistent with the benchmark data: on long-horizon agentic tasks where the model iterates on its own code, Qwen's architecture delivers disproportionate value.
Pricing Comparison: The Middle Ground
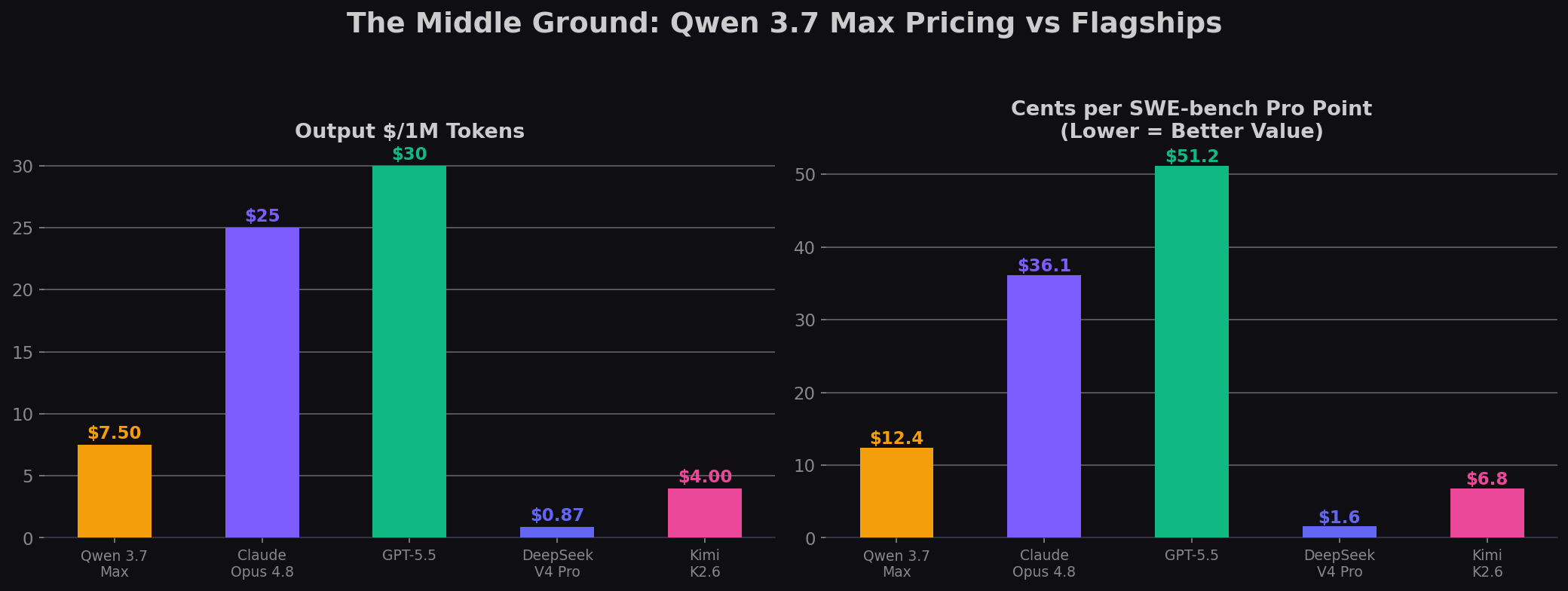
| Model | Input $/1M | Output $/1M | SWE-bench Pro | Cents per Pro Point |
|---|---|---|---|---|
| DeepSeek V4 Pro | $0.435 | $0.87 | 55.4% | $1.57 |
| Qwen 3.7 Max | $2.50 | $7.50 | 60.6% | $12.38 |
| Kimi K2.6 | $0.95 | $4.00 | 58.6% | $6.83 |
| Claude Opus 4.8 | $5.00 | $25.00 | 69.2% | $36.13 |
| GPT-5.5 | $5.00 | $30.00 | 58.6% | $51.19 |
Qwen occupies a strategic middle ground: 7.9× more expensive per Pro point than DeepSeek V4 Pro, but 2.9–4.1× cheaper than the US flagships. It's not the cheapest — but it offers the strongest benchmark scores of any model below $10/1M output.
The Strategic Choice: Closed-Weight, API-Only
This is the most significant strategic decision Alibaba made with Qwen 3.7 Max. Unlike Qwen 3.6 (open-weight, Apache 2.0), Qwen 3.7 Max is proprietary and API-only. You cannot download it. You cannot run it on your own GPUs. The only access is through Alibaba Cloud Model Studio.
Why? Alibaba is betting that frontier agent capability at mid-tier pricing is more sustainable than open-weight at cost-floor pricing. DeepSeek's strategy — MIT license, permanent 75% discounts — pushes prices toward zero. Alibaba's counter: better benchmarks at a reasonable price.
For developers, this means:
- No self-hosting. If you need offline or air-gapped AI, look at Qwen 3.6 Plus or DeepSeek V4 Pro.
- API dependency. You're locked into Alibaba Cloud — or OpenRouter as a reseller.
- Anthropic protocol compatibility mitigates lock-in. You can swap between Qwen and Claude without changing your harness code.
What Developers Are Saying
"Qwen 3.7 Max is the best Chinese model on the Artificial Analysis Intelligence Index at launch... On the coding side, Qwen leads Opus 4.6 on Terminal-Bench, SWE-bench Pro, and MCP Atlas. The agentic coding gap is meaningful." — YouTube analysis
"I am really happy with this model... the benchmark they have given on SWE-bench Pro, Multilingual, and Terminal-Bench 2.0 on agent coding is 100% correct... Qwen 3.7 Max on frontend coding and design and SVG generation — I give 10/10." — Independent tester
On the r/opencodeCLI subreddit, developers are actively discussing Qwen as part of multi-model stacks, pairing it with GLM-5.1 and Kimi K2.6 for cost-effective heavy usage. The consensus: Qwen for reasoning-heavy agent tasks, DeepSeek for volume, Kimi for coding.
Which Model for Which Task?
| Task | Best Model | Why |
|---|---|---|
| Real-world bug fixing (Django, Flask) | Claude Opus 4.8 | 69.2% SWE-bench Pro — 8.6 points ahead of Qwen |
| Algorithmic / LeetCode | DeepSeek V4 Pro | 93.5% LiveCodeBench; Qwen is close at 91.6% |
| Scientific Python | Qwen 3.7 Max | 53.5% SciCode — 2× the next model |
| Long-horizon agent runs | Qwen 3.7 Max | Designed for 35+ hour continuous execution; 1.98× GPU kernel speedup |
| Tool-use / function calling | Qwen 3.7 Max | 60.8% MCP-Mark, 75.0% BFCL-V4 — leads both |
| Terminal / CLI automation | GPT-5.5 | 78.2% Terminal-Bench; Qwen at 69.7% |
| Full-stack web dev (tied) | Claude Opus 4.8 | 69.2% SWE-bench Pro covers Django/Flask well |
| Cost-sensitive at scale (with verbosity considered) | DeepSeek V4 Pro | $0.87/1M output, less verbose than Qwen |
| Drop-in Claude Code replacement | Qwen 3.7 Max | Anthropic API compatible — no code changes |
| Office / productivity automation | Qwen 3.7 Max | 87% on SpreadSheetBench-v1; designed for this use case |
The Bottom Line
- Qwen 3.7 Max is the strongest Chinese model ever benchmarked. AA Intelligence Index of 56.6 — tied with Claude Opus 4.7. SWE-bench Pro at 60.6%. LiveCodeBench at 91.6%. SciCode at a staggering 53.5%. These are not "almost as good" numbers — they're genuinely competitive.
- It carves out unique leadership on specific benchmarks. SciCode (2× the next model), LiveCodeBench (35 points ahead of GPT-5.5), MCP-Mark, BFCL-V4. These aren't rounding errors — they're domains where Qwen is the best available model.
- The verbosity tax is the biggest hidden cost. At 4× token generation vs peers, Qwen's $7.50/1M output doesn't tell the full story. For cost-sensitive production, DeepSeek V4 Pro ($0.87/1M, less verbose) is often cheaper per task.
- Claude Opus 4.8 still wins the coding crown. 69.2% SWE-bench Pro vs Qwen's 60.6%. An 8.6-point gap is real. For production bug fixing, the premium pays for itself.
- The Anthropic API compatibility is a strategic masterstroke. Qwen can be dropped into any Claude Code or OpenClaw setup with zero code changes. This eliminates the biggest barrier to adoption: harness reconfiguration.
- Closed-weight, mid-tier pricing is a viable third path. Not as cheap as DeepSeek ($0.87), not as capable as Claude ($25). But the combination of 60.6% SWE-bench Pro at $7.50/1M output — with Anthropic protocol compatibility — occupies a genuine niche.
Qwen 3.7 Max is not a Claude killer. It's not a DeepSeek killer. It's a Claude alternative for agentic workloads at 70% of the cost — and on scientific computing and algorithmic coding, it's actually better. For the first time, a Chinese proprietary model isn't just competing on price. It's competing on capability.
📚 Related Articles
Sources: Qwen 3.7 Official Blog — The Agent Frontier | Overchat AI — Qwen 3.7 Max Analysis | Yotta Labs — Qwen 3.7 Max Guide | OpenRouter — Qwen 3.7 Max | Reddit — Tetris Bot Experiment | YouTube Analysis | Alibaba Cloud Model Studio. All benchmark scores vendor-reported from official Qwen blog unless otherwise noted. SciCode and LiveCodeBench scores pending independent verification.