
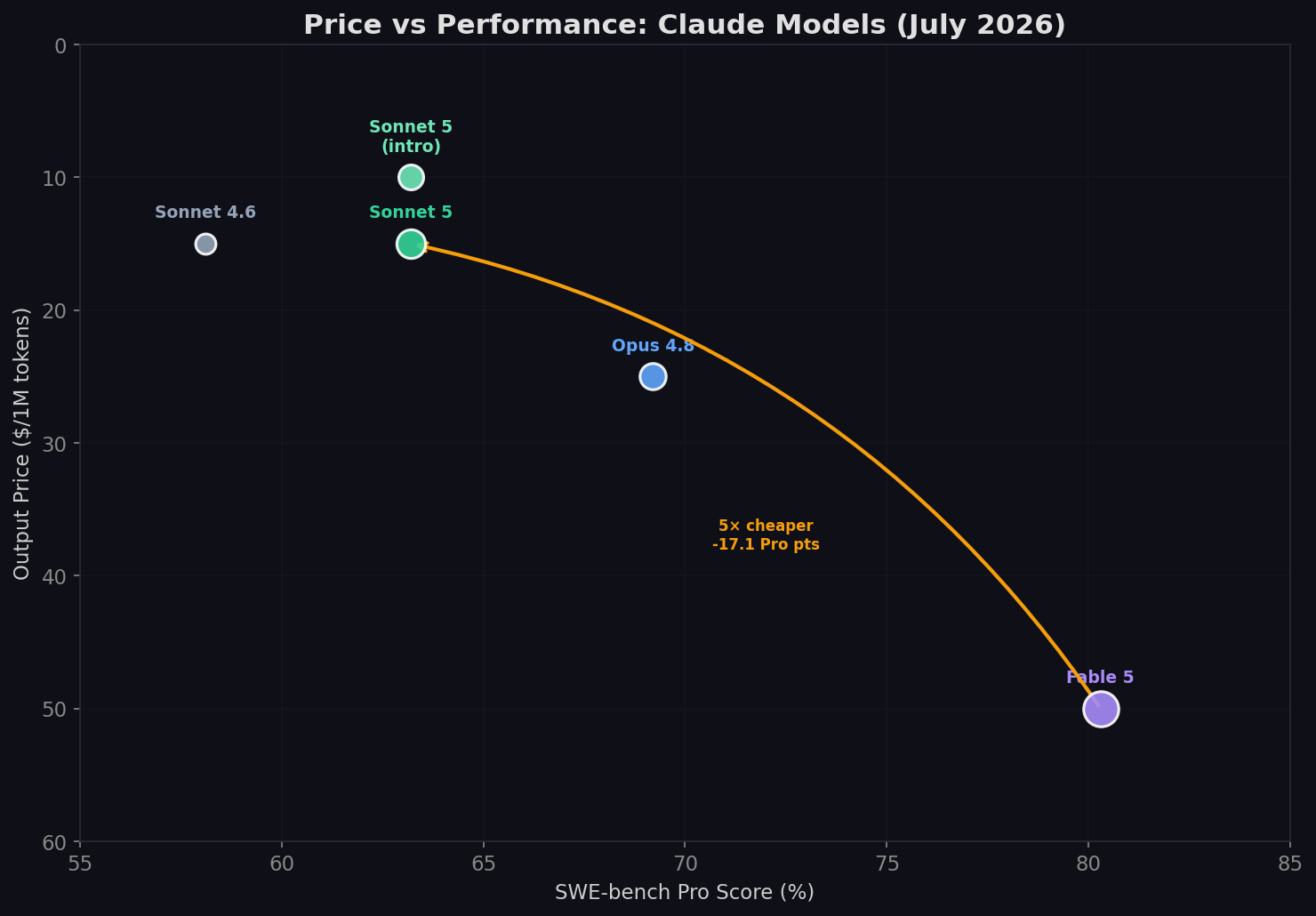
July 1, 2026. Two Claude models, two tiers, one question: Mythos or Sonnet? Claude Fable 5 — Anthropic's first publicly available Mythos-class model — sits at the top with 80.3% SWE-bench Pro and an $50/1M output price. Claude Sonnet 5 — released June 30, just one day ago — delivers 63.2% Pro at $15/1M (intro $10 through August 31). That's 79% of Fable 5's coding capability at 30% of the price. But benchmarks are only part of the story. Here's the complete data-driven comparison — 9 benchmarks, pricing deep-dive, value analysis, and a clear verdict on which model to use when.
🔮 Key Findings
- Fable 5 leads all 8 directly comparable benchmarks. SWE-bench Pro: +17.1. Terminal-Bench: +7.6. HLE no tools: +13.6. Average gap: +8.2 points across all shared evaluations.
- Sonnet 5 costs 70% less. $15/1M output vs $50/1M. Introductory pricing at $10/1M through August 31 makes it 5× cheaper than Fable 5.
- Sonnet 5 is 2.2× better value per Pro point. $0.24/point (standard) vs Fable 5's $0.62/point. At intro batch pricing: $0.08/point vs Fable's $0.31/point — nearly 4× better.
- Sonnet 5 beats Fable 5 on FrontierCode v1 (38.8% vs 29.3% Diamond). Different test versions, but Sonnet's production code quality is remarkably close to Mythos territory.
- Fable 5 just returned from a 19-day export suspension. Access restored July 1, 2026. Sonnet 5 launched during the ban and is already production-proven.
Also see: Fable 5 Complete Review · Sonnet 5 vs Sonnet 4.6 · SWE-bench Pro Leaderboard · Terminal-Bench Leaderboard · Pricing Calculator.
The Context: Two Models, One Month, One Company
Anthropic released Fable 5 on June 9, 2026 — their first publicly available Mythos-class model. It was immediately the most capable AI model ever made generally available. Three days later, on June 12, a US export control directive forced Anthropic to suspend access for all users. For 19 days, Fable 5 was offline.
During that window, Anthropic launched Claude Sonnet 5 (June 30) — a model that, according to their system card, "performs close to Opus 4.8 at lower prices." It was not blocked by export controls because its cybersecurity capabilities are deliberately limited. The timing is significant: Sonnet 5 became the best available Claude model for most of the developer ecosystem while Fable was unavailable.
Now, on July 1, both models are live. Fable 5 is back. Sonnet 5 is production-proven. Which one should you use? Let's look at every number.
Head-to-Head: Every Comparable Benchmark
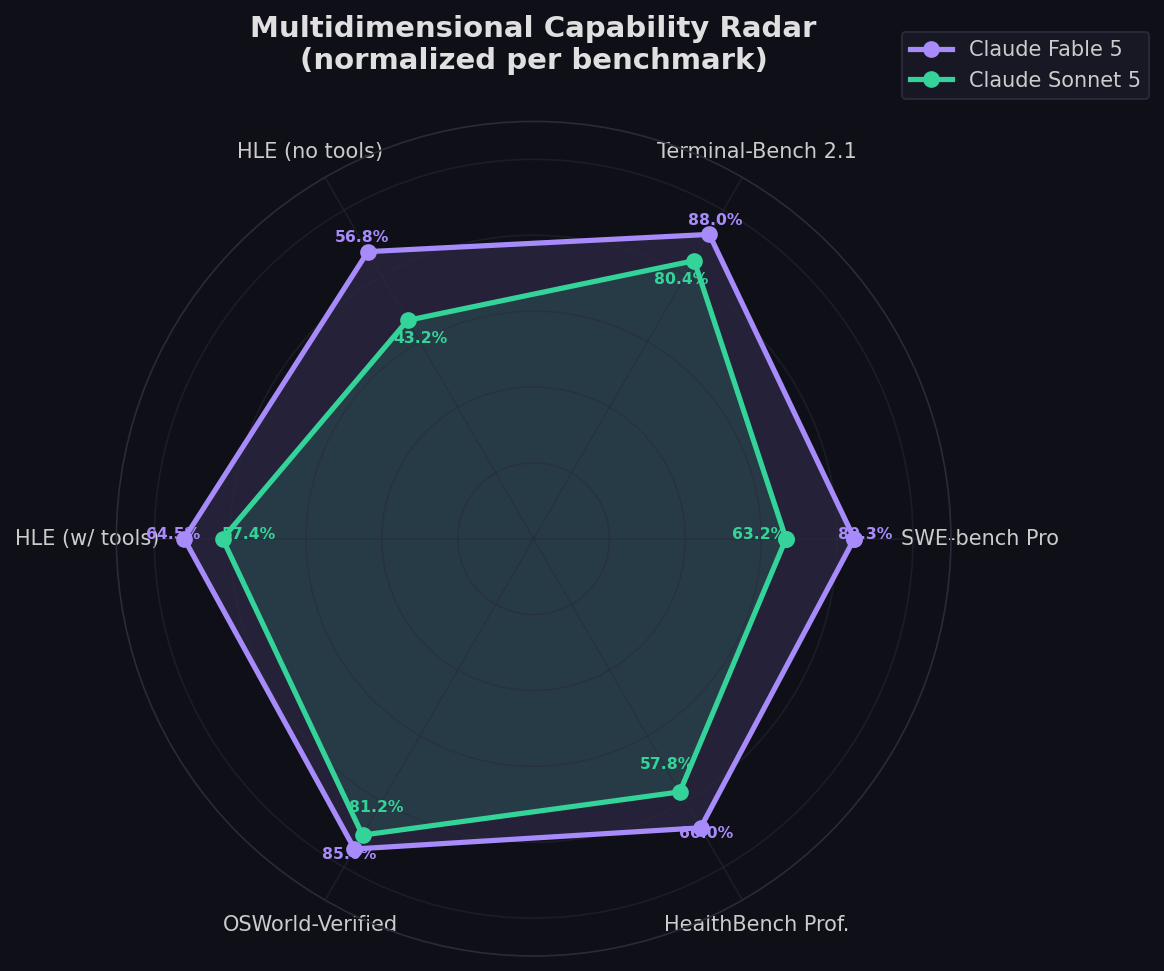
Below is the most comprehensive side-by-side comparison available as of July 1, 2026. All scores are Anthropic-reported from the respective system cards, using max effort / adaptive thinking at default sampling settings. Purple cells indicate the leader.
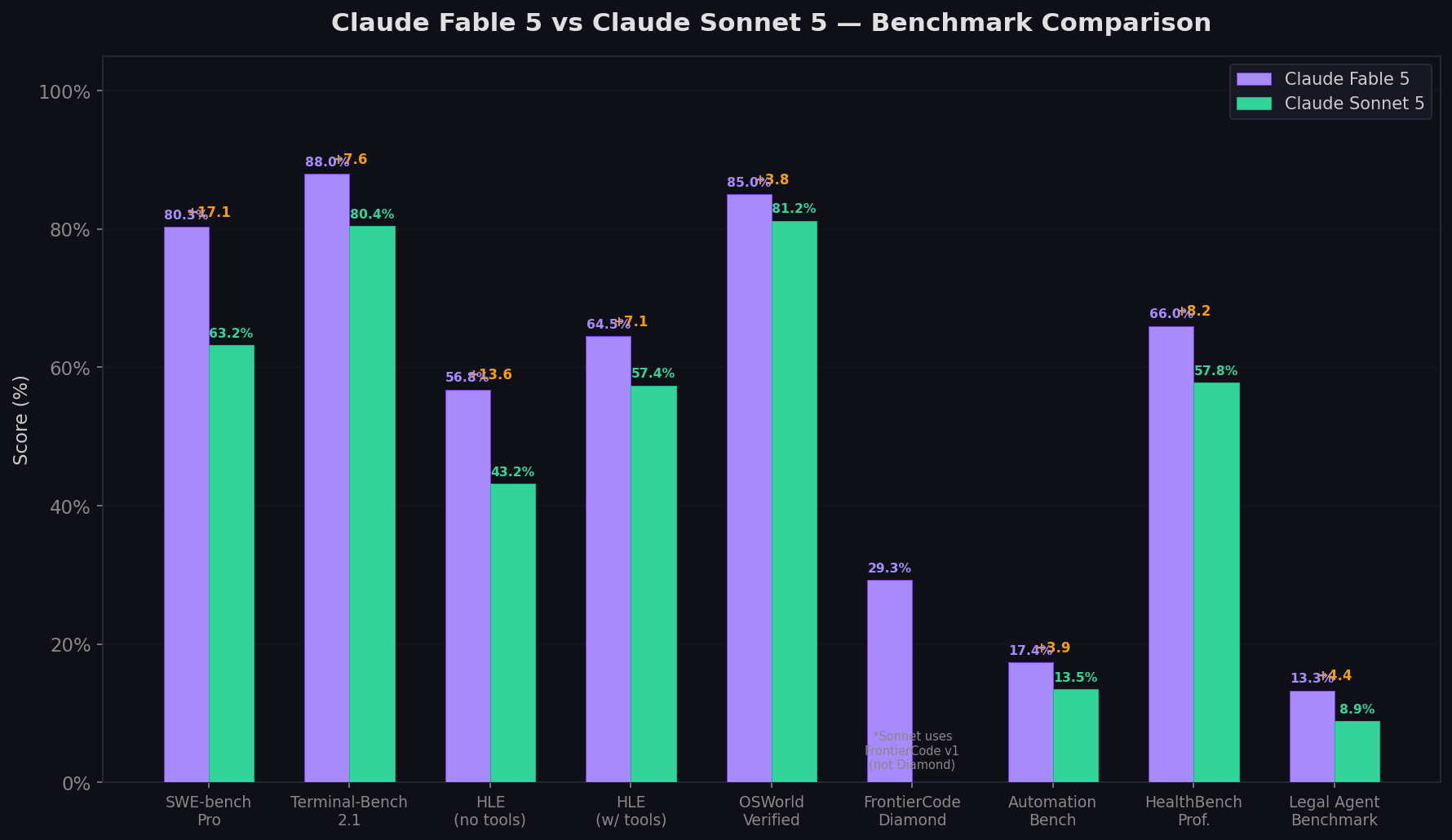
| Benchmark | Claude Fable 5 | Claude Sonnet 5 | Gap | What It Measures |
|---|---|---|---|---|
| SWE-bench Pro | 80.3% | 63.2% | +17.1 | Real GitHub issues, multi-file, contamination-resistant |
| Terminal-Bench 2.1 | 88.0% | 80.4% | +7.6 | CLI coding, shell, build systems |
| HLE (no tools) | 56.8% | 43.2% | +13.6 | Multidisciplinary expert reasoning |
| HLE (with tools) | 64.5% | 57.4% | +7.1 | Expert reasoning + tool orchestration |
| OSWorld-Verified | 85.0% | 81.2% | +3.8 | Computer use, GUI navigation |
| AutomationBench | 17.4% | 13.5% | +3.9 | Tool use and workflow automation |
| HealthBench Professional | 66.0% | 57.8% | +8.2 | Clinical accuracy across 26 specialties |
| Legal Agent Benchmark | 13.3% | 8.9% | +4.4 | Legal document analysis and reasoning |
| FrontierCode | 29.3% (Diamond) | 38.8% (v1) | — | Production-quality code (different test versions — not directly comparable) |
| GDPval-AA | 1932 (v1) | 1618 (v2) | — | Knowledge work (different test versions — not directly comparable) |
Sources: Fable 5 System Card · Sonnet 5 System Card. All scores Anthropic-reported with max effort / adaptive thinking at default sampling. FrontierCode and GDPval-AA use different benchmark versions (Diamond vs v1, v1 vs v2) and are not directly comparable.
Pricing: 3.3× Cheaper, 2.2× Better Value
This is where the comparison gets interesting. Fable 5 delivers more capability — but Sonnet 5 delivers dramatically better value.
| Claude Fable 5 | Claude Sonnet 5 | Winner | |
|---|---|---|---|
| Input $/1M | $10.00 | $3.00 | Sonnet 5 |
| Output $/1M | $50.00 | $15.00 | Sonnet 5 |
| Intro Output $/1M | $50.00 | $10.00 | Sonnet 5 (thru Aug 31) |
| Batch Output $/1M | $25.00 | $7.50 | Sonnet 5 |
| Cached Input $/1M | $1.00 | $0.30 | Sonnet 5 |
| Context Window | 1M tokens | 1M tokens | Tie |
| Batch/Flex Discount | ✅ 50% | ✅ 50% | Tie |
| Prompt Caching | ✅ 90% | ✅ 90% | Tie |
| Subscription Access | Credits required | Default on Free/Pro | Sonnet 5 |
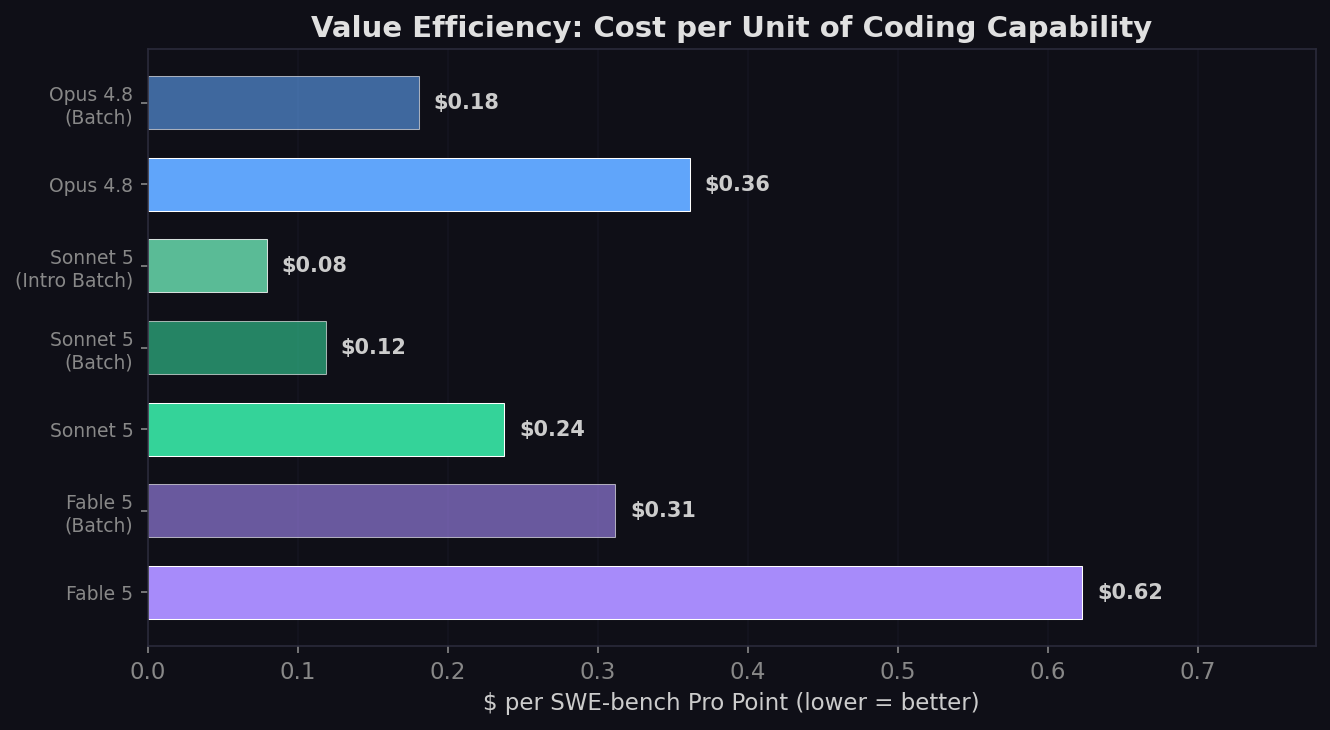
Cost per SWE-bench Pro Point
The clearest value metric: how much does each point of coding capability cost you?
| Configuration | Fable 5 | Sonnet 5 | Sonnet Advantage |
|---|---|---|---|
| Standard list price | $0.62/pt | $0.24/pt | 2.6× better |
| Batch pricing | $0.31/pt | $0.12/pt | 2.6× better |
| Intro + Batch (thru Aug 31) | $0.31/pt | $0.08/pt | 3.9× better |
Real-World Coding Session Cost
A typical heavy coding session — 3M input + 1M output tokens:
| Model | Standard | Batch | 100 Sessions/mo (Batch) |
|---|---|---|---|
| Claude Fable 5 | $80.00 | $40.00 | $4,000 |
| Claude Sonnet 5 | $24.00 | $12.00 | $1,200 |
| Claude Sonnet 5 (intro) | $19.00 | $9.50 | $950 |
At batch pricing, Sonnet 5 costs $1,200/month for 100 heavy sessions — 70% less than Fable 5 at $4,000. For teams running high-volume coding agents, the savings compound fast.
What Each Gap Actually Means
SWE-bench Pro: The 17.1-Point Chasm
This is the single most important number. SWE-bench Pro tests real GitHub issue resolution — reading unfamiliar codebases, making multi-file changes, and passing test suites with no answer leakage. Fable 5 at 80.3% vs Sonnet 5 at 63.2% is a 17.1-point gap — larger than Sonnet 5's lead over GPT-5.5 (+4.6 points) and Sonnet 4.6 (+5.1 points).
What does this mean in practice? On complex multi-file bugs where Sonnet 5 succeeds roughly 2 out of 3 times, Fable 5 succeeds 4 out of 5 times. That's the difference between "usually works" and "you can trust it." For solo developers, that extra reliability may be worth the premium. For teams running verification passes, Sonnet 5 at 2.6× better value is hard to beat.
Terminal-Bench 2.1: The Narrowest Gap
Fable 5: 88.0%. Sonnet 5: 80.4%. A 7.6-point gap — the closest of any major benchmark. Both models are excellent at CLI operations: installing packages, debugging builds, managing git, configuring servers. Sonnet 5's 80.4% is just 2.3 points behind Opus 4.8 (82.7%) and ahead of GPT-5.5's 78.2% (per tbench.ai). For DevOps automation and terminal-based agent work, Sonnet 5 is essentially Opus-class.
Humanity's Last Exam: The Reasoning Divide
Without tools: Fable 5 56.8% vs Sonnet 5 43.2% — a 13.6-point gap. With tools: Fable 5 64.5% vs Sonnet 5 57.4% — a 7.1-point gap. Fable 5's advantage shrinks when both models have access to tools, suggesting the gap is partly about raw knowledge breadth (where Fable's larger model size matters more) and partly about reasoning depth (where tools help level the field).
OSWorld: The Near-Tie
Fable 5: 85.0%. Sonnet 5: 81.2%. A 3.8-point gap — the tightest of any benchmark. Both models are exceptionally capable at GUI navigation, desktop automation, and computer use tasks. Sonnet 5 is within 2.2 points of Opus 4.8 (83.4%) on this benchmark. For browser automation and computer-use agents, Sonnet 5 is essentially indistinguishable from Anthropic's top-tier models.
FrontierCode & GDPval-AA: The Version Caveat
These benchmarks use different versions across the two models and cannot be directly compared. Fable 5's 29.3% on FrontierCode Diamond tests production-quality code on novel problems — the hardest coding benchmark available. Sonnet 5's 38.8% is on FrontierCode v1, a different (and likely easier) test set. Similarly, Fable 5's 1932 on GDPval-AA v1 and Sonnet 5's 1618 on v2 use different question sets and scoring methodologies. We include them for completeness but they don't inform the head-to-head.
Safety, Access, and Production Readiness
| Claude Fable 5 | Claude Sonnet 5 | |
|---|---|---|
| Safety Architecture | Cyber/bio/chemistry classifiers → falls back to Opus 4.8 on ~5% of queries | Deliberately limited cyber capabilities — no fallback needed |
| Export Status | Previously suspended (Jun 12–30); restored July 1 | Never suspended — available continuously since launch |
| Production Stability | 3 days of GA before suspension; just restored | 1 day old but no regulatory headwinds |
| Data Retention | 30-day mandatory retention (all business customers) | Standard Anthropic retention policy |
| Subscription | Credits required (was free on plans thru June 22) | Default model on Free and Pro plans |
| API Access | Available to all | Available to all |
| Rate Limits | Standard | Raised limits to accommodate heavier token usage |
The production stability question is real. Fable 5 has already been suspended once. While the export control is now lifted, the regulatory precedent means another suspension is not impossible. Sonnet 5 was deliberately designed to avoid triggering the same controls — Anthropic limited its cybersecurity capabilities specifically so it could ship without restrictions. For teams building production pipelines, Sonnet 5's regulatory safety may matter more than Fable 5's capability edge.
The Tokenizer Tax: What You Actually Pay
Sonnet 5 uses an updated tokenizer that produces 1.0–1.35× more tokens than Sonnet 4.6 for the same input. Anthropic's introductory pricing ($2/$10 instead of $3/$15) is designed to make the transition roughly cost-neutral from Sonnet 4.6. But compared to Fable 5, the tokenizer difference means Sonnet 5 consumes slightly more tokens for the same prompt — partially offsetting its lower per-token price.
Key tokenizer ratios from the system card:
| Content Type | Sonnet 4.6 Tokens | Sonnet 5 Tokens | Ratio |
|---|---|---|---|
| English text | 2,356 | 3,341 | 1.42× |
| Spanish text | 3,572 | 4,747 | 1.33× |
| Python code (4,279 lines) | 44,014 | 56,113 | 1.27× |
| Chinese (Simplified) | 3,334 | 3,360 | 1.01× |
Source: Sonnet 5 System Card, tokenizer comparison table. Fable 5 uses the same tokenizer as Opus 4.8 (legacy tokenizer, comparable to Sonnet 4.6 ratios).
The practical impact: for a Python-heavy coding session, Sonnet 5's effective cost advantage over Fable 5 shrinks from 3.3× to roughly 2.6× after accounting for the tokenizer — still massive, but worth factoring in for high-volume pipelines.
Where They Fit in the Claude Lineup
Anthropic now has four active tiers, and the positioning is clearer than ever:
| Tier | Model | Pro Score | Output $/1M | Best For |
|---|---|---|---|---|
| Mythos | Claude Fable 5 | 80.3% | $50.00 | Hardest coding problems, long-horizon autonomy, research |
| Opus | Claude Opus 4.8 | 69.2% | $25.00 | Complex engineering, calibrated honesty, unattended agents |
| Sonnet | Claude Sonnet 5 | 63.2% | $15.00 | Daily coding, CLI agents, computer use, best value |
| Haiku | Claude Haiku 4.5 | — | $5.00 | Fast chat, simple tasks, high-volume pipelines |
Sonnet 5 at 63.2% Pro is just 6 points behind Opus 4.8 (69.2%) at 60% of the price. It beats Opus on GDPval-AA v2 knowledge work (1618 vs 1615). It's within 2.2 points on OSWorld and 2.3 points on Terminal-Bench. For most developers, Sonnet 5 makes Opus 4.8 unnecessary. Fable 5 remains the aspirational ceiling — the model you reach for when the problem genuinely requires Mythos-class reasoning.
Verdict: Capability vs Value — Pick Your Priority
| Use Case | Winner | Why |
|---|---|---|
| Hardest bugs (4+ files, novel codebase) | Fable 5 | 80.3% Pro — 17.1 points ahead. The gap widens on harder tasks. |
| CLI / DevOps automation | Fable 5 | 88.0% TB 2.1. But Sonnet at 80.4% is close enough for most teams. |
| Long-horizon autonomous tasks | Fable 5 | Stripe 50M-line migration. Week-long genomics. Pokémon full playthrough. |
| Daily coding (routine bugs, PRs) | Sonnet 5 | 63.2% Pro is plenty. 3.3× cheaper. Default on Free/Pro plans. |
| Computer use / browser agents | Tie | 85.0% vs 81.2% — barely distinguishable. Use Sonnet for cost. |
| Cost-sensitive high volume | Sonnet 5 | $0.12/Pro point (batch) vs $0.31. 70% cheaper per session. |
| Production pipelines (no human review) | Sonnet 5 | No export suspension risk. No safety fallbacks. Proven availability. |
| Scientific research / expert reasoning | Fable 5 | 56.8% HLE (no tools) vs 43.2%. 13.6-point gap in raw reasoning. |
| Legal / healthcare compliance | Fable 5 | 13.3% vs 8.9% (Legal). 66.0% vs 57.8% (HealthBench). |
| Best overall value | Sonnet 5 | 79% of Fable 5's coding capability at 30% of the price. |
Conclusion: The Right Tool for the Right Job
Claude Fable 5 is the most capable AI model ever made publicly available. It leads every shared benchmark, often by double-digit margins. It completed Stripe's 50M-line migration in a day. It designs proteins better than humans. It plays Pokémon with vision alone. If you need maximum capability and can verify the output, there is no substitute.
Claude Sonnet 5 is the smarter choice for most developers, most of the time. At 63.2% Pro — just 6 points behind Opus 4.8 — it handles daily coding, CLI automation, and computer use at near-Opus quality for Sonnet prices. The introductory $10/1M output pricing (through August 31) makes it the best value in the Anthropic lineup by a wide margin. And unlike Fable 5, it was designed to ship without regulatory headwinds.
The honest recommendation: use both. Sonnet 5 for your daily driver — coding, PRs, terminal work, computer use. Fable 5 for the hard problems — complex multi-file bugs, long-horizon autonomous tasks, research, and problems where a 17-point Pro gap is the difference between success and failure. At 2.6× better value per Pro point, Sonnet 5 handles 80% of what Fable 5 can do for 30% of the cost. The remaining 20% — the genuinely hard problems — is where Mythos earns its premium.
20+ LLMs. Side-by-side testing. Find which model handles your hardest problems.
Sources: Anthropic — Fable 5 & Mythos 5 System Card | Anthropic — Sonnet 5 System Card & Launch Announcement | Simon Willison — What's New in Sonnet 5 | DataCamp — Sonnet 5 Benchmarks & Pricing | Cosmic JS — Developer Guide | Morphllm — Claude Benchmarks. All benchmark scores Anthropic-reported unless otherwise noted. Pricing as of July 1, 2026. Sonnet 5 introductory pricing valid through August 31, 2026.