📊 TL;DR — Key Findings
- TIED on SWE-bench Pro (58.6%): The #1 benchmark for real-world coding — both models score identically. The closest any two frontier models have ever been on Pro.
- Kimi leads agentic search dramatically: DeepSearchQA F1 92.5% vs 78.6% (+13.9). BrowseComp Agent Swarm 86.3% — GPT-5.5 can't do swarms. HLE w/tools 54.0% vs 52.2%.
- GPT-5.5 leads reasoning + knowledge: HLE no tools 41.4% vs 34.7% (+6.7). GPQA Diamond 93.6% vs 90.5% (+3.1). HMMT 97.7% vs 92.7% (+5.0). Toolathlon +5.6.
- 7.5× price gap: GPT-5.5 $30/1M output vs Kimi $4/1M. At 100M tokens/month: GPT-5.5 $3,500 vs Kimi $470.
- GPT-5.5 has 4× larger context: 1M vs 256K tokens — decisive for full-codebase work.
- Kimi is open-weight: Weights on HuggingFace (Modified MIT). Self-host, fine-tune, air-gap. GPT-5.5 is proprietary.
Try both models side-by-side on your own code at CodingFleet →
Benchmark Comparison
| Benchmark | GPT-5.5 | Kimi K2.6 | Winner |
|---|---|---|---|
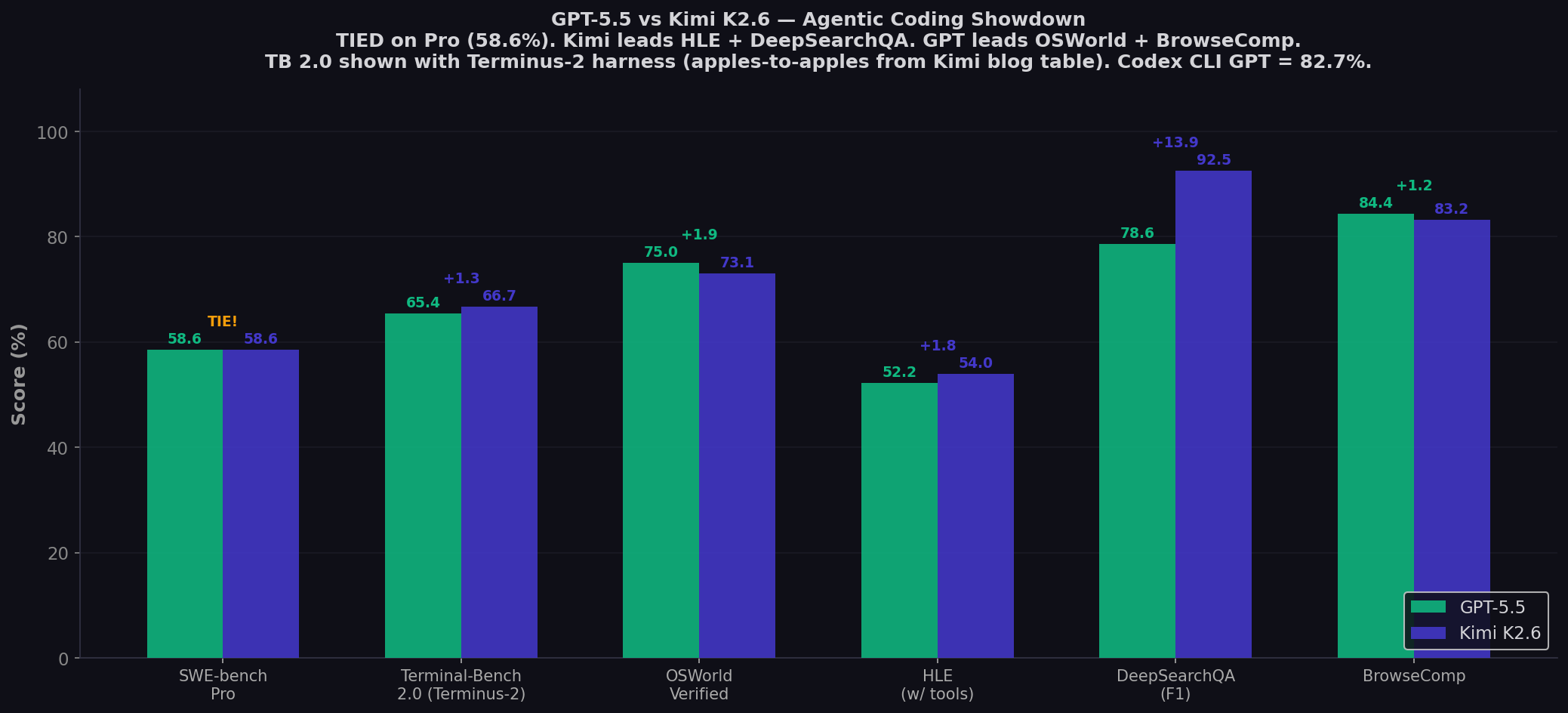
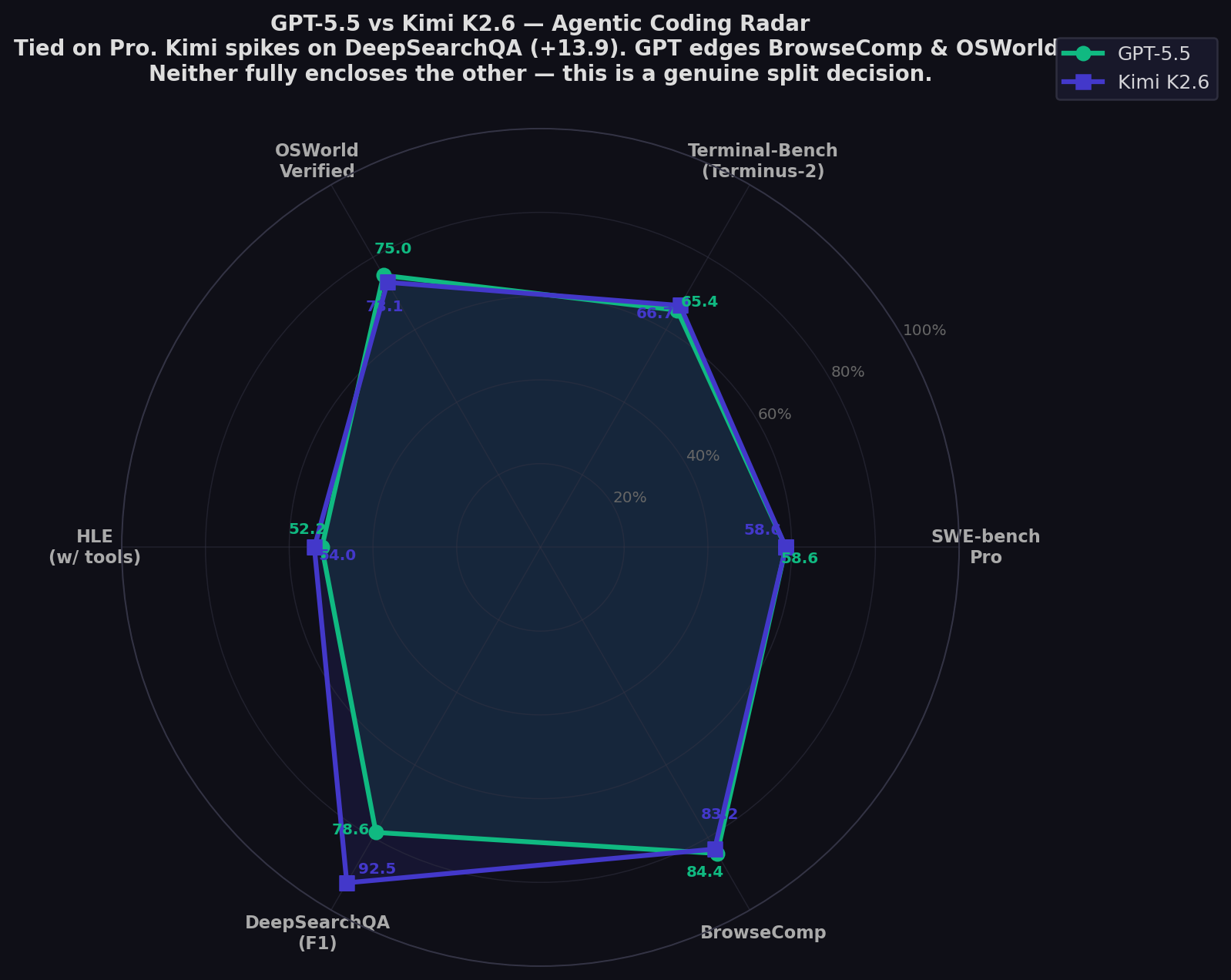
| SWE-bench Pro ★ | 58.6% | 58.6% | ⚖️ TIE |
| Terminal-Bench 2.0 (Terminus-2) | 65.4% | 66.7% | Kimi (+1.3) |
| Terminal-Bench 2.0 (Codex CLI) | 82.7% | — (different harness) | GPT-5.5 — harness-dependent |
| OSWorld-Verified | 75.0% | 73.1% | GPT-5.5 (+1.9) |
| HLE (no tools) | 41.4% | 34.7% | GPT-5.5 (+6.7) |
| HLE (with tools) | 52.2% | 54.0% | Kimi (+1.8) |
| BrowseComp | 84.4% | 83.2% | GPT-5.5 (+1.2) |
| BrowseComp (Agent Swarm) | — (no swarm capability) | 86.3% | Kimi — unique capability |
| DeepSearchQA (F1) | 78.6% | 92.5% | Kimi (+13.9) |
| Toolathlon | 55.6% | 50.0% | GPT-5.5 (+5.6) |
| MCPMark | 62.5% | 55.9% | GPT-5.5 (+6.6) |
| SciCode | 56.6% | 52.2% | GPT-5.5 (+4.4) |
| GPQA Diamond | 93.6% | 90.5% | GPT-5.5 (+3.1) |
| HMMT 2026 Feb | 97.7% | 92.7% | GPT-5.5 (+5.0) |
| APEX-Agents | 33.3% | 27.9% | GPT-5.5 (+5.4) |
| Output Price /1M tok | $30.00 | $4.00 | Kimi (7.5× cheaper) |
| Context Window | 1M (922K via AA) | 262K | GPT-5.5 (4× larger) |
Sources: Kimi K2.6 official tech blog — all apples-to-apples comparison rows with GPT-5.4 (xhigh) from Moonshot's published table | BenchLM — GPT-5.5 vs Kimi K2.6 | DeepInfra Kimi analysis | DeepLearning.AI Batch #351 | Lushbinary Kimi guide. TB 2.0 shown with Terminus-2 harness (fair comparison). GPT-5.5 with Codex CLI = 82.7%. ★ SWE-bench Pro is the recommended benchmark.
SWE-bench Pro: The Tie That Defines the Comparison
Both models score 58.6% on the hardest coding benchmark. No other frontier pair is this close — the next tightest is MiniMax M3 vs Kimi K2.6 at 0.4 points apart. This is the first genuine tie at the top of the open-weight vs proprietary coding hierarchy. On the benchmark that most directly tests real-world software engineering — multi-file GitHub issue resolution across Django, Flask, scikit-learn, and other production repos — these two models are functionally identical. BenchLM's head-to-head confirms: "GPT-5.5 is clearly ahead on the provisional aggregate, 89 to 81. The single biggest benchmark swing on the page is HLE. Kimi K2.6 does hit back in coding, so the answer changes if that is the part of the workload you care about most."
DeepSearchQA: The 13.9-Point Search Gap
The widest single-benchmark gap in this comparison. Kimi K2.6 at 92.5% F1 vs GPT-5.5 at 78.6% on DeepSearchQA — a benchmark that tests research retrieval and synthesis across multiple sources. The gap widens further on accuracy: Kimi 83.0% vs GPT-5.5 63.7%. This is not a narrow edge — it's a different capability tier. For agents that need to search, retrieve, cross-reference, and synthesize information from multiple documents, Kimi's architecture has a structural advantage. The DeepLearning.AI Batch analysis notes Kimi's "Agent Swarm capability that coordinates up to 300 parallel sub-agents across 4,000 steps — the model dynamically decomposes complex tasks and routes them to specialized sub-agents."
Terminal-Bench: The Harness Problem
This is the trickiest benchmark to compare fairly. GPT-5.5 with the Codex CLI harness scores 82.7% — the highest non-Mythos Terminal-Bench score ever. With the standard Terminus-2 harness (used in the Kimi blog's apples-to-apples comparison), GPT-5.5 scores 65.4%. Kimi K2.6 with Terminus-2 scores 66.7% — a 1.3-point edge. The honest read: GPT-5.5 with Codex CLI is dramatically better at terminal tasks. With equivalent harnesses, the models are within noise. For developers building CLI agents, the harness matters as much as the model — and GPT-5.5 + Codex CLI is the most capable terminal agent pair currently available.
Architecture & Ecosystem
| Feature | GPT-5.5 | Kimi K2.6 |
|---|---|---|
| Release Date | April 23, 2026 | April 20, 2026 |
| Developer | OpenAI | Moonshot AI (Beijing) |
| Model Class | Proprietary Frontier | Open-Weight (Modified MIT) |
| Context Window | 1M tokens | 262K tokens |
| Parameters | Not disclosed | ~1T total / ~32B active (MoE) |
| Input Modalities | Text, Image, Audio, Video | Text, Image |
| Weights Available | No | Yes — HuggingFace (Modified MIT) |
| API Compatibility | OpenAI SDK, Azure | OpenAI + Anthropic compatible |
| Agent Architecture | Codex CLI, sub-agents (8 parallel) | Agent Swarm: 300 sub-agents, 4,000 steps |
| Max Autonomous Runtime | 24+ hours (Codex cloud sandbox) | 12 hours (vendor claim) |
| AA-Omniscience Hallucination | 86% (high) | 39.26% (low) |
| LiveCodeBench v6 | — (not published) | 89.6% |
| Self-Hosting | Not possible | Yes — vLLM, SGLang, KTransformers |
Why GPT-5.5 Wins: The Generalist Premium
GPT-5.5 leads on 10 of the 14 shared benchmarks — not by narrow margins on most. HLE no-tools (+6.7), Toolathlon (+5.6), MCPMark (+6.6), HMMT (+5.0), GPQA (+3.1), APEX-Agents (+5.4), SciCode (+4.4). The pattern is consistent: GPT-5.5 is stronger on academic reasoning, scientific knowledge, and structured tool use. The Codex CLI ecosystem — with cloud sandbox execution, 24+ hour unattended runs, and kernel-level sandboxing — makes GPT-5.5 the more complete platform for production coding agents. And the 1M context window (4× Kimi's 256K) is decisive for full-codebase analysis. BenchLM gives GPT-5.5 the edge: "89 to 81 on the provisional leaderboard. The gap is large enough that you do not need to squint at the spreadsheet to see the difference."
Why Kimi K2.6 Wins: The Agentic Specialist
Kimi K2.6's defining advantage is Agent Swarm — the ability to decompose complex tasks into 300 parallel, domain-specialized sub-agents coordinating across 4,000 steps. This architecture shows its strength on the benchmarks that most directly test agentic capability: BrowseComp Agent Swarm (86.3%), DeepSearchQA (92.5% F1), HLE with tools (54.0%). And critically: Kimi achieves the same Pro score as GPT-5.5 at 7.5× lower cost. The open-weight release on HuggingFace under a Modified MIT license means full self-hosting via vLLM, SGLang, or KTransformers with native INT4 quantization. For teams that want coding capability parity without the $30/1M price tag, the choice is clear. DeepLearning.AI's analysis notes that Kimi's hallucination rate (39.26%) is dramatically lower than GPT-5.5's (86%) — "roughly comparable to Anthropic Claude Opus 4.7 (36.18%)." For agentic coding where a single hallucinated API call can break an entire workflow, this reliability gap compounds across thousands of agent steps.
Pricing: 7.5× Economics
At 100M output tokens/month:
- GPT-5.5: $3,000 output + $500 input = $3,500/month
- Kimi K2.6: $400 output + $95 input = $495/month (official) or as low as $280 output + $60 input = $340/month (DeepInfra/Parasail)
With Batch/Flex: GPT-5.5 drops to $1,750. Kimi via DeepInfra cached at $0.15/1M brings it even lower. The $1,250-$3,160 monthly difference funds an entire additional agent stack.
Which Model Should You Use?
| Use Case | Winner | Why |
|---|---|---|
| Real GitHub issue fixing | ⚖️ Tie | Both 58.6% Pro — functionally identical on multi-file bug resolution |
| CLI agent (Codex harness) | GPT-5.5 ✅ | 82.7% TB 2.0 with Codex CLI — unmatched terminal performance |
| Research / search agents | Kimi ✅ | 92.5% DeepSearchQA (+13.9). 86.3% BrowseComp Swarm |
| Academic reasoning | GPT-5.5 ✅ | +6.7 HLE no-tools, +5.0 HMMT, +3.1 GPQA |
| Agentic coding w/ tools | Kimi ✅ | +1.8 HLE w/tools. Agent Swarm architecture advantage |
| Full-codebase work | GPT-5.5 ✅ | 1M context vs 256K — 4× more codebase in memory |
| Self-hosting / air-gapped | Kimi ✅ | Open-weight on HuggingFace. GPT-5.5 is proprietary only |
| High-volume / budget | Kimi ✅ | 7.5× cheaper. $340-$495/mo vs $3,500/mo at 100M output |
| Production reliability | Kimi ✅ | 39% hallucination vs 86% — dramatically fewer fabricated API calls |
| Multimodal (video/audio) | GPT-5.5 ✅ | Native omnimodal. Kimi is text+image only |
Conclusion: Same Score, Different Models
The 58.6% Pro tie is the headline — but the models are not the same. GPT-5.5 is the stronger generalist: better at academic reasoning, structured tool use, scientific coding, and terminal agents (with Codex CLI). It has a 4× larger context window, native omnimodal input, and the Codex ecosystem behind it. For production teams building coding agents where correctness matters and the infrastructure budget exists, GPT-5.5 is the more complete answer.
Kimi K2.6 is the stronger specialist: its Agent Swarm architecture gives it unique advantages on research, search, and tool-augmented reasoning tasks that are the future of agentic AI. And critically: it achieves identical Pro performance at 7.5× lower cost, with 2.2× lower hallucination, and full open-weight freedom. For cost-conscious teams, self-hosting deployments, and any workflow where agentic search and swarm coordination matter more than raw academic reasoning, Kimi is the smarter choice.
BenchLM's verdict captures the practical calculus: "Pick GPT-5.5 if you want the stronger benchmark profile. Kimi K2.6 only becomes the better choice if coding is the priority or you want the cheaper token bill." In 2026, for most developers, coding is the priority — and the cheaper token bill means the difference between shipping and stalling.
20+ LLMs available on CodingFleet. Test GPT-5.5 and Kimi K2.6 side-by-side on your own code.
📚 Sources & Links
- Kimi K2.6 Official Tech Blog — Moonshot AI's published benchmark comparison table
- BenchLM — GPT-5.5 vs Kimi K2.6 Head-to-Head — category-level comparison with scores
- DeepInfra — Kimi K2.6 API Benchmarks — latency, throughput, and cost analysis
- DeepLearning.AI Batch #351 — GPT-5.5 hallucination analysis + Kimi K2.6 Agent Swarm overview
- Lushbinary — Kimi K2.6 Developer Guide — full benchmark tables and API pricing
- Verdent AI — Kimi K2.6 vs GPT-5.4 vs Claude — benchmark comparison
- KimiK2AI — Agent Swarm Deep Dive — 300 sub-agent architecture details
- Lorka AI — Kimi K2.6 Tested — real-world evaluation
- Handy AI — Model Drop: Kimi K2.6 — pricing and availability
- Vellum — GPT-5.5 benchmarks
📖 Read This Next
- GPT-5.5 vs Qwen 3.7 Max — Qwen beats GPT-5.5 on Pro at 4× less cost
- Kimi K2.6 vs MiniMax M3 — the open-weight crown (0.4 pts apart)
- GPT-5.5 vs Gemini 3.5 Flash — flagship vs speed demon
- SWE-bench Pro Live Leaderboard — every model ranked
- AI Model Pricing Calculator — compare costs at your token volume