
📊 Key Findings
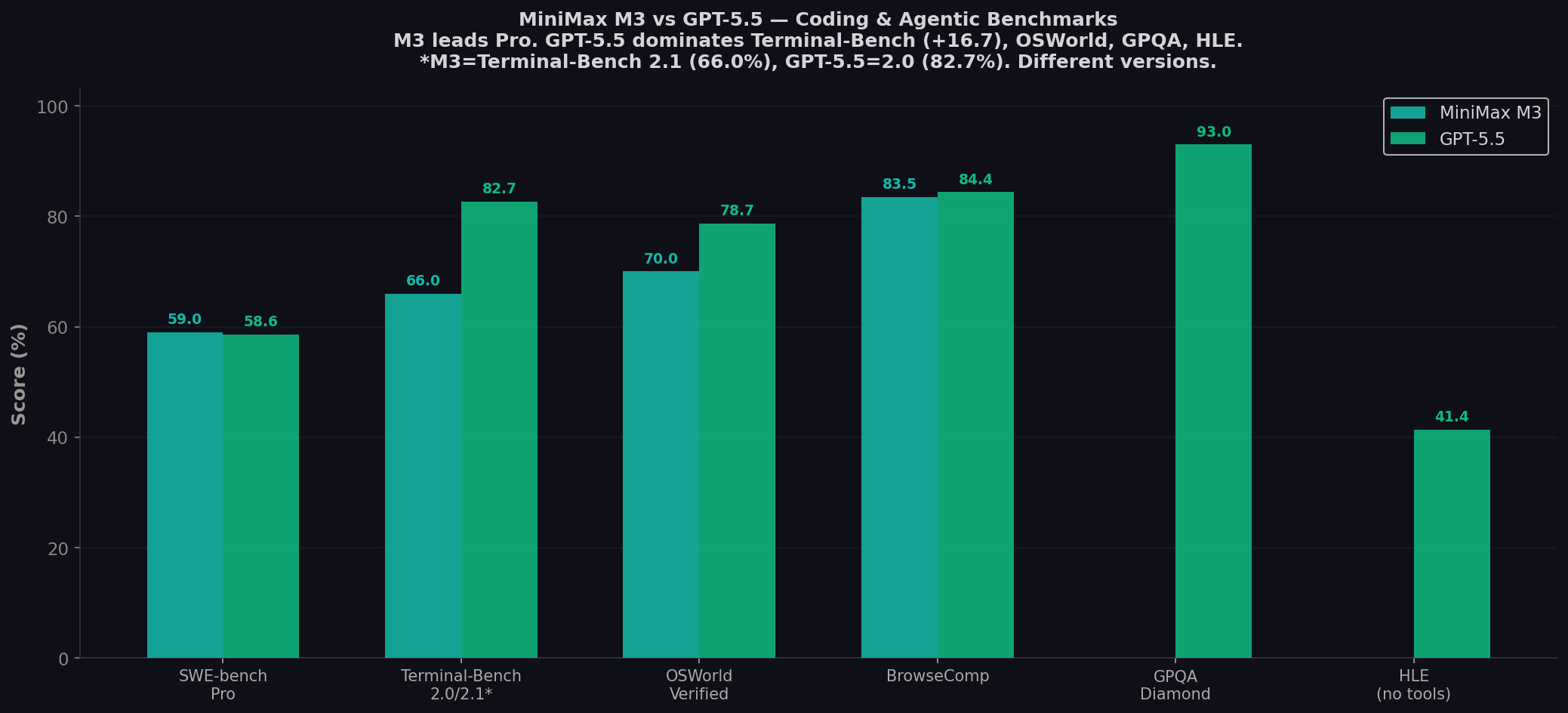
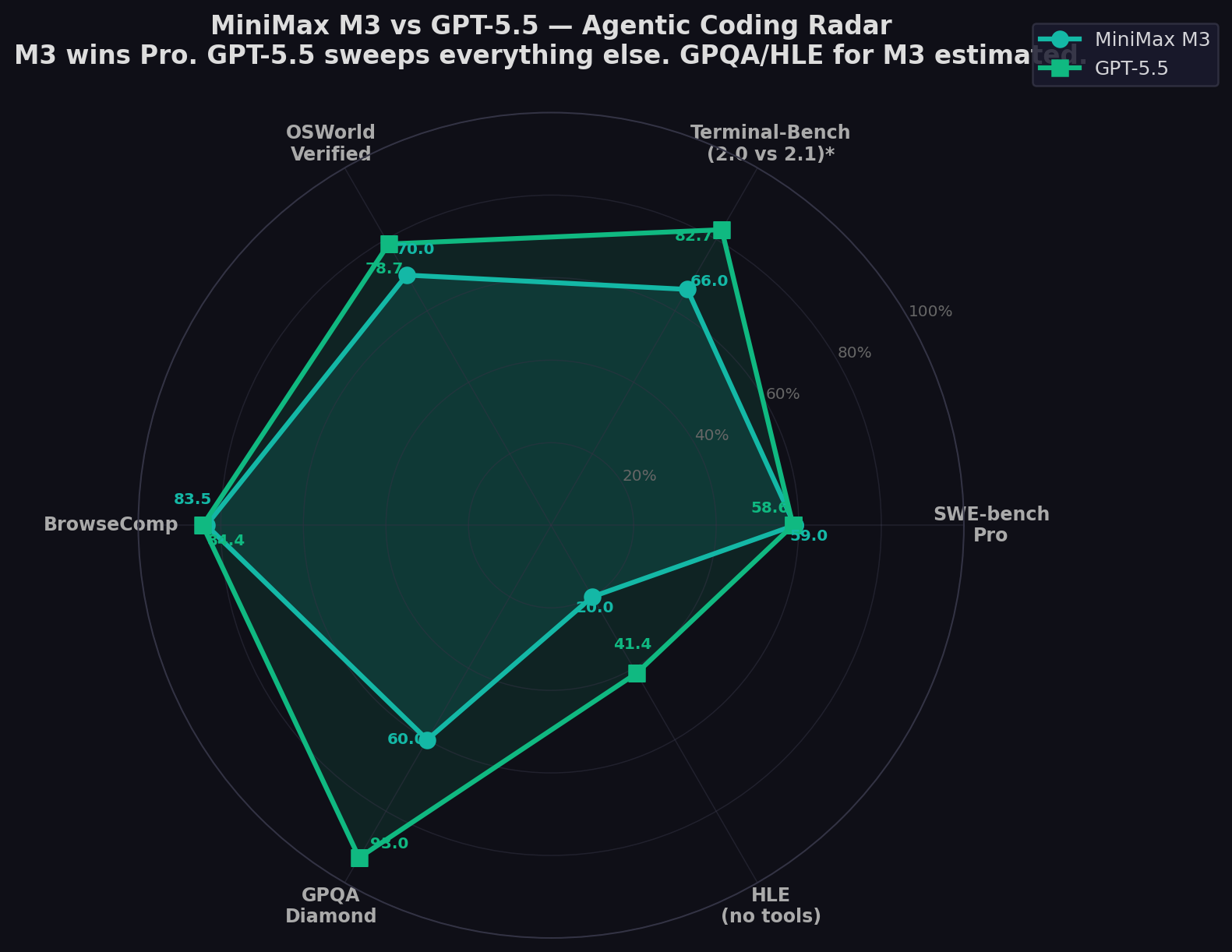
- MiniMax M3 leads SWE-bench Pro: 59.0% vs 58.6% — the first open-weight model to beat GPT-5.5 on the most important coding benchmark. But the 0.4-point gap is within the margin of error.
- GPT-5.5 dominates terminal/agentic benchmarks: +16.7 on Terminal-Bench (82.7% vs 66.0%), +8.7 on OSWorld (78.7% vs 70.0%). For CLI tasks and computer use, GPT-5.5 is in a different league.
- 25× price gap: M3 at $1.20/1M output vs GPT-5.5 at $30/1M. M3's promotional pricing ($0.30/$1.20) makes it even cheaper. Standard pricing ($0.60/$2.40) narrows the gap to 12.5×.
- M3 is open-weight (Modified MIT license) — self-hostable, fine-tunable, no vendor lock-in. GPT-5.5 is fully proprietary with no weights available.
- GPU-poor architecture: M3's MSA sparse attention delivers 9× prefill speedup and 1/20th compute at 1M tokens. Trained exclusively on Huawei Ascend 910B — zero NVIDIA GPUs.
- M3 benchmarks are vendor-reported and unverified: MiniMax hasn't published a technical report yet (promised within 10 days of launch). GPT-5.5 scores are independently verified on tbench.ai and other third-party leaderboards.
Compare these models side-by-side on real code. Both are available on CodingFleet. Start a new chat →
Benchmark Comparison
| Benchmark | MiniMax M3 | GPT-5.5 | Gap | Notes |
|---|---|---|---|---|
| SWE-bench Pro ★ | 59.0% | 58.6% | M3 +0.4 | M3: vendor-reported. GPT-5.5: verified. Both within noise range. |
| SWE-bench Verified ⚠️ | 80.5% | 82.6% | GPT +2.1 | Contaminated per OpenAI Feb 2026. Historical reference only. |
| Terminal-Bench 2.0/2.1* | 66.0% | 82.7% | GPT +16.7 | *M3: 2.1 (66.0%). GPT-5.5: 2.0 (82.7%). Codex CLI scores 83.4% on 2.1. |
| OSWorld Verified | 70.0% | 78.7% | GPT +8.7 | Computer use / GUI interaction benchmark. |
| BrowseComp | 83.5 | 84.4% | GPT +0.9 | Autonomous browsing. M3 beats Opus 4.7 (79.3). GPT-5.5 Pro: 90.1%. |
| MCP Atlas | 74.2% | 75.3% | GPT +1.1 | Tool orchestration / API calling. Very close. |
| GPQA Diamond | — | 93.0% | — | M3 not published. GPT-5.5 near top of leaderboard. |
| HLE (no tools) | — | 41.4% | — | Humanity's Last Exam. M3 not published. |
| HLE (with tools) | — | 52.2% | — | With browsing and code execution tools. |
Sources: MiniMax M3 official blog (June 1, 2026), BenchLM comparison, MorphLLM leaderboard, VentureBeat, MarkTechPost, Lushbinary. M3 scores are vendor-reported and unverified. GPT-5.5 scores independently verified on tbench.ai. Terminal-Bench versions differ between models.
Benchmark Deep Dives
SWE-bench Pro: The 0.4-Point "Win"
M3's 59.0% on SWE-bench Pro is genuinely impressive. It's the first open-weight model to surpass GPT-5.5 on the hardest coding benchmark. But context matters:
- 0.4 points is within the benchmark's noise floor. The ICSE 2026 patch correctness study found SWE-bench systematically overestimates scores by 3.8–5.2 percentage points. A 0.4-point difference is not statistically meaningful.
- M3's score is vendor-reported. MiniMax has not released the technical report or evaluation methodology yet (promised within 10 days of the June 1 launch). GPT-5.5's 58.6% is independently verified.
- Claude Fable 5's 80.3% shows how far both are from the actual frontier. The real coding king sits 21+ points above both of these models. This is a fight for second/third place in the open-weight vs proprietary mid-tier.
Terminal-Bench: The 16.7-Point Chasm
This is the single biggest gap in the comparison. GPT-5.5 at 82.7% (Terminal-Bench 2.0) vs M3 at 66.0% (Terminal-Bench 2.1). Even accounting for the version difference, this is a massive capability gap. Terminal-Bench tests real CLI workflows — package management, git operations, build systems, server configuration, Docker commands. This is 2026's DevOps. GPT-5.5 dominates it. M3 is mid-tier. If your AI workflow involves terminal commands, this single benchmark should guide your choice.
GPQA and HLE: The Silence
MiniMax published no GPQA Diamond or HLE scores for M3. These are the two most important reasoning benchmarks — graduate-level science questions and the "hardest test ever created." GPT-5.5 scores 93.0% on GPQA and 41.4% on HLE. M3's silence on these metrics is the biggest red flag in this comparison. Either the scores are weak, or MiniMax didn't test them — neither is reassuring.
Architecture & Ecosystem
| Attribute | MiniMax M3 | GPT-5.5 |
|---|---|---|
| Release Date | June 1, 2026 | April 23, 2026 |
| Architecture | Sparse MoE + MSA (MiniMax Sparse Attention) | Omnimodal transformer |
| Context Window | 1M tokens (512K guaranteed, higher costs beyond) | 1M tokens |
| Multimodality | Text + Image + Video input. Text output. Desktop computer operation. | Text + Image + Audio input. Text output. OSWorld + browser verification. |
| Training Hardware | Huawei Ascend 910B (zero NVIDIA) | NVIDIA (undisclosed) |
| License | Modified MIT (open-weight, self-hostable) | Proprietary (API-only) |
| Weights | Promised within 10 days of launch | Never — closed model |
| Ecosystem | MiniMax Code IDE, Antigravity agent platform | Codex CLI, ChatGPT, API, Azure, 4M weekly Codex devs |
MSA: The GPU-Poor Innovation
MiniMax Sparse Attention (MSA) is M3's defining architectural innovation. Standard attention has O(n²) complexity — as context grows, compute explodes. MSA partitions the KV cache into blocks and only processes relevant ones. The result:
- 9× faster prefill (input processing) vs the previous M2 generation
- 15× faster generation (output tokens)
- 1/20th compute per token at 1M tokens of context
This was trained entirely on Huawei Ascend 910B chips — one of the first frontier models built without NVIDIA hardware. For developers in regions with export restrictions or organizations that need air-gapped deployment on non-NVIDIA infrastructure, M3 is the first viable option at this capability level.
Codex CLI: GPT-5.5's Ecosystem Moat
GPT-5.5's biggest advantage isn't in benchmarks — it's in deployment. Codex CLI powers 4 million weekly developers. It has persisted goals, browser verification, and a self-repair loop that catches and fixes bugs autonomously. The Codex ecosystem is integrated into GitHub, Azure, and the OpenAI API. M3 has MiniMax Code (a good IDE) and Antigravity (a promising agent platform), but the ecosystem gap is measured in years, not benchmark points.
Pricing: The 25× Question
| Pricing Tier | MiniMax M3 | GPT-5.5 |
|---|---|---|
| Input (per 1M tokens) | $0.30 promo / $0.60 standard | $5.00 |
| Output (per 1M tokens) | $1.20 promo / $2.40 standard | $30.00 |
| Batch/Flex Output | — | $15.00 (50% discount) |
| Cached Input | — | $0.50 (90% discount) |
| Self-Hosted | Free (once weights released) + hardware | Not possible |
💡 Real Session Cost: At 10M tokens/month with 90% input, M3 costs ~$1.62/month (promo pricing) vs ~$37.50/month for GPT-5.5. That's a 23× difference — enough to run M3 for nearly 2 years for what GPT-5.5 costs in 1 month. At standard pricing, M3 is still 12.5× cheaper. For teams with 10+ developers using AI daily, the annual savings are measured in tens of thousands of dollars.
Read more: Compare pricing across all 29 models → AI Model Pricing Calculator
What Developers Are Saying
Reddit and YouTube early feedback on M3 (June 1–12, 2026):
| Source | Quote / Finding |
|---|---|
| r/opencodeCLI | "Good context awareness, solid reasoning — but misunderstands instructions more often than I'd like. GLM-5.1 still feels more precise." — u/303Dave, compared M3 to Kimi K2.6 and GLM-5.1 across 8 agentic prompts |
| r/opencodeCLI | "M3 was ranked on the same level as GLM-5.1 and Kimi K2.6 across 8 prompts. Looks too good to be true but significantly better than M2.7." |
| r/LocalLLaMA | "I've tried it. Clear improvement over M2.7. Better than DeepSeek V4 Pro. Not sure about GLM 5.1. Not near GPT 5.5, but maybe on the level of GPT 5.4." — Developer running local agent harnesses with Qwen 3.6 and M3 |
| r/LocalLLaMA | "With M2.7 at Q4_K_M: 600-700 tokens prompt processing, 15-20 tps inference. M3 just feels more competent and solid. Definitely better than old GPT models." |
| YouTube (BridgeMind) | "It broke push-to-talk, produced a blank Remotion video, failed 8/12 UI tests. The whole session cost $4.09. You get what you pay for." — Tested M3 on BridgeBench gauntlet + production features in BridgeVoice |
The consensus: M3 is genuinely good for its price, but not battle-tested enough to replace GPT-5.5 for mission-critical workflows. It's a developer model — you'll need to iterate more, handle more failures, and verify output more carefully than with GPT-5.5.
Which Should You Use?
| Use Case | Best Model | Why |
|---|---|---|
| Multi-file Python bug fixing | MiniMax M3 | 59.0% Pro — edge case, but leads. Best open-weight for Django/Flask/scikit-learn. |
| Terminal / CLI / DevOps | GPT-5.5 | +16.7 Terminal-Bench gap is decisive. Package management, git, builds, Docker. |
| Computer use / GUI automation | GPT-5.5 | +8.7 OSWorld. Both have desktop operation, but GPT-5.5 executes better. |
| Best value / cost-sensitive | MiniMax M3 | $1.20/1M vs $30/1M. 25× cheaper. Self-hostable. MIT license. |
| Academic reasoning / STEM | GPT-5.5 | 93.0% GPQA. M3 hasn't published GPQA/HLE scores. |
| Multimodal coding (video/diagrams) | MiniMax M3 | Native video input. OmniDocBench 91.6%. GPT-5.5 is image+audio, no video. |
| Self-hosting / air-gapped | MiniMax M3 | Modified MIT. Weights coming soon. Runs on non-NVIDIA hardware. |
| Production agents (unattended) | GPT-5.5 | Codex ecosystem, browser verification, 4M devs, better instruction following. |
The Bottom Line
MiniMax M3 is the most interesting open-weight model of 2026. It's the first to genuinely threaten GPT-5.5 on coding benchmarks, at a price that makes high-volume AI coding accessible to indie developers and small teams. The MSA architecture is a legitimate innovation — 1M context at 1/20th the compute. The Huawei Ascend training story matters for a world fragmenting along chip supply lines.
But GPT-5.5 is the safer choice for production — and probably the smarter choice for most developers. The 16.7-point Terminal-Bench lead isn't just a number; it's the difference between an AI that can reliably manage your development environment and one that needs hand-holding. The ecosystem gap — Codex CLI, browser verification, 4 million weekly developers — means GPT-5.5 has been battle-tested at a scale M3 hasn't approached.
The smartest approach: use both. Route complex bug-fixing to M3 (0.4 Pro lead at 25× less cost). Route terminal tasks, DevOps, and unattended agents to GPT-5.5. M3 for the 40% of coding that benefits from open-weight flexibility and cost efficiency. GPT-5.5 for the 60% that demands reliability and ecosystem maturity.
🚀 Compare MiniMax M3 and GPT-5.5 on Your Own Code
Both models are available on CodingFleet. Test them side-by-side on the same task. See which writes better code for your stack — not just benchmarks.
Start a New Chat on CodingFleet →Sources & Links
- MiniMax — MiniMax M3: Frontier Coding, 1M Context, Native Multimodality (June 1, 2026). Official announcement and benchmark claims.
- BenchLM — GPT-5.5 vs MiniMax M3: AI Benchmark Comparison 2026. Aggregate scores: GPT-5.5 89, M3 79.
- MorphLLM — SWE-bench Pro Leaderboard. Full ranking with Verified and Pro scores.
- VentureBeat — MiniMax-M3 debuts, eclipsing GPT-5.5 and Gemini 3.1 Pro (June 1, 2026).
- MarkTechPost — MiniMax M3 with MSA Architecture (June 1, 2026). MSA sparse attention deep-dive.
- Lushbinary — MiniMax M3 Developer Guide. Architecture, pricing, benchmarks, deployment.
- Reddit r/opencodeCLI — Anyone already tested MiniMax M3? Community feedback thread.
- Reddit r/LocalLLaMA — MiniMax M3 open-source discussion. Local deployment experiences.
- YouTube (BridgeMind) — Vibe Coding With MiniMax M3. Production feature testing on BridgeVoice.
- The Decoder — MiniMax M3 open-weight challenges proprietary leaders (June 1, 2026).
📚 Related Articles
- Kimi K2.6 vs MiniMax M3 — Open-weight crown showdown
- MiniMax M3 vs DeepSeek V4 Pro
- Qwen 3.7 Max vs MiniMax M3
- SWE-bench Pro Leaderboard — All models ranked
- Terminal-Bench Leaderboard — CLI coding ranked
- AI Model Pricing Calculator — Compare 29 models
- Most Cost-Effective AI Models