
Two models. Two philosophies. Claude Sonnet 5 — Anthropic's new mid-tier king, 63.2% SWE-bench Pro, 80.4% Terminal-Bench, built for coding depth. Gemini 3.5 Flash — Google's speed demon, 83.6% MCP Atlas, 289 tok/s, built for tool orchestration at scale. On pure coding, Sonnet leads every shared benchmark by 3-8 points. On tool use and speed, Gemini runs circles around it. One costs $3/$15. The other costs $1.50/$9 and is 4× faster. This isn't about which model is better — it's about what kind of developer you are. Here's the complete comparison, sourced from Anthropic's Sonnet 5 System Card and Google's Gemini 3.5 Flash Model Card. Test both on CodingFleet.
TL;DR — Sonnet 5 vs Gemini 3.5 Flash
- Sonnet leads every coding benchmark: +8.1 Pro, +4.2 TB 2.1, +2.8 OSWorld, +3.0 HLE. Decisive across the board.
- Gemini leads MCP Atlas by a mile: 83.6% — the highest published score from any vendor. Sonnet 5's score is unpublished.
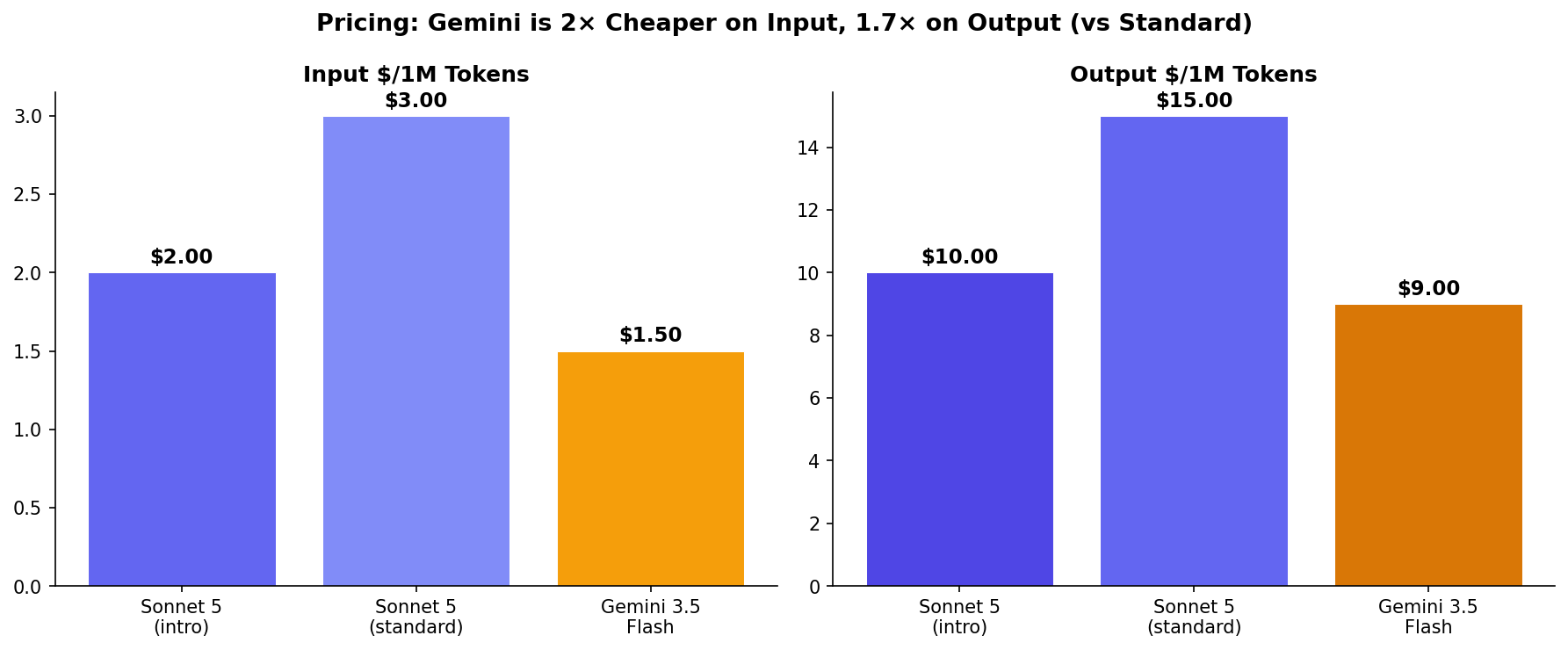
- Gemini is 2× cheaper and 4× faster: $1.50/$9 vs $3/$15. 289 tok/s vs ~65 tok/s.
- Both have 1M context: Gemini's is battle-tested on MRCR v2. Sonnet's is new.
- Gemini has multimodal advantages: CharXiv 84.2%, MMMU-Pro 83.6%. Sonnet hasn't published these.
- Sonnet has the Anthropic safety moat: 145-page System Card. Sycophancy 3.1%. Injection ASR 0.31%.
Head-to-Head: Shared Benchmarks
| Benchmark | Claude Sonnet 5 | Gemini 3.5 Flash | Winner |
|---|---|---|---|
| SWE-bench Pro (Public) | 63.2% | 55.1% | Sonnet (+8.1) |
| Terminal-Bench 2.1 | 80.4% | 76.2% | Sonnet (+4.2) |
| OSWorld-Verified | 81.2% | 78.4% | Sonnet (+2.8) |
| HLE (no tools) | 43.2% | 40.2% | Sonnet (+3.0) |
Sonnet 5 from Anthropic System Card (Table 8.1.A). Gemini 3.5 Flash from Google Model Card. Both vendor-reported. Different scaffolds — cross-vendor comparisons should be treated as directional.
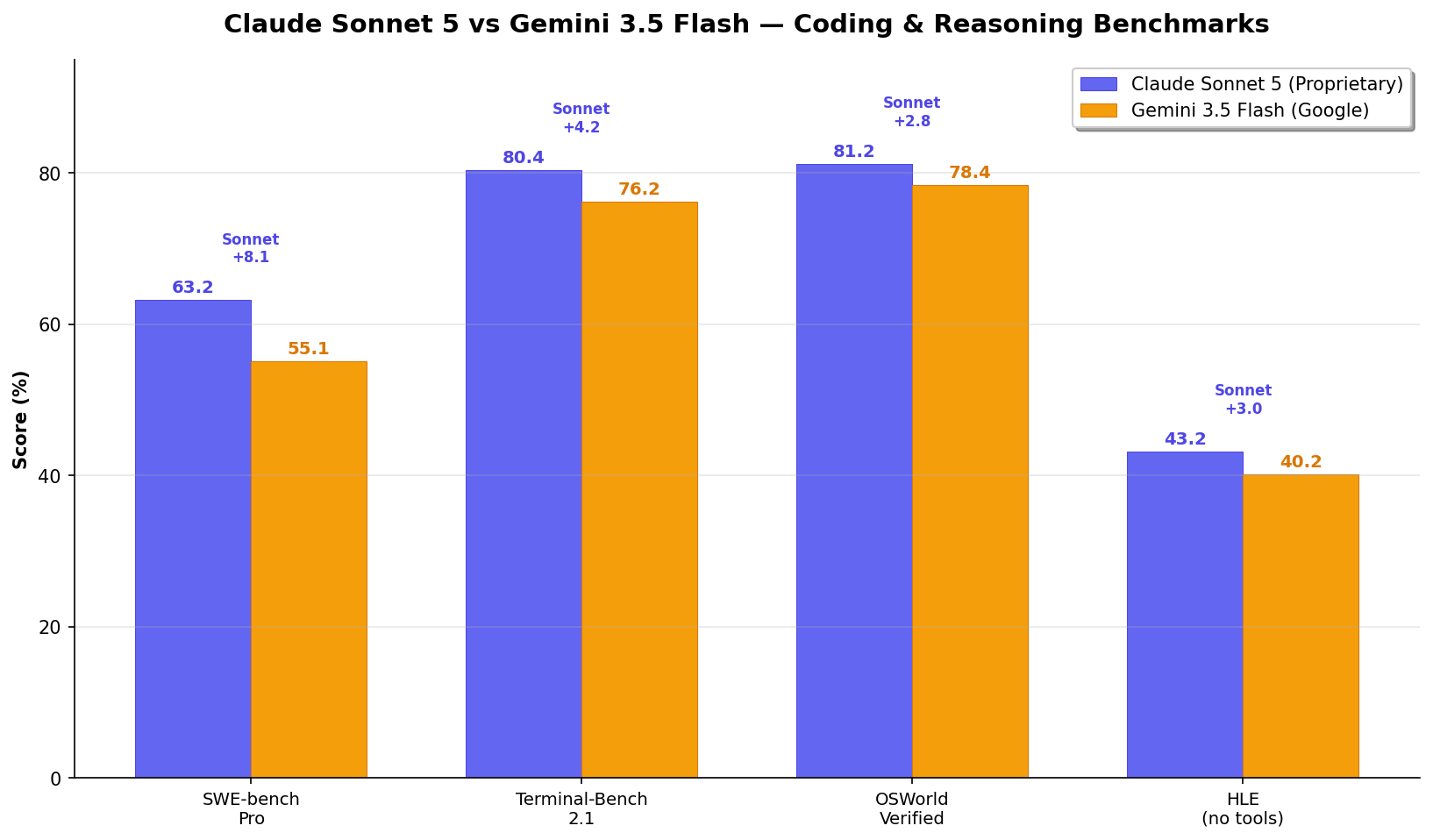
Coding: Sonnet's Decisive Lead
Every shared benchmark tells the same story. On SWE-bench Pro (1,865 real GitHub issues, multi-file diffs, 4 languages): Sonnet 5 at 63.2% vs Gemini 3.5 Flash at 55.1%. That's an 8.1-point gap — not marginal, decisive. On Terminal-Bench 2.1 (CLI agentic coding): Sonnet at 80.4% vs Gemini at 76.2% (+4.2). On OSWorld-Verified (desktop automation): Sonnet at 81.2% vs Gemini at 78.4% (+2.8).
For developers whose primary workflow is Claude Code, Cursor, or any coding-centric agent, Sonnet 5 is objectively stronger. The 8.1-point Pro gap represents roughly 150 additional GitHub issues solved correctly out of 1,865. That's not noise — it's a meaningful difference in daily productivity.
MCP Atlas: Gemini's Crown Jewel
Then there's MCP Atlas — the benchmark for multi-server tool orchestration. Gemini 3.5 Flash scores 83.6%, the highest published score from any vendor. It beats Claude Opus 4.7 (79.1%), Claude Opus 4.8 (82.2% on Anthropic's harness), and GPT-5.5 (75.3%). Sonnet 5 does not have a published MCP Atlas score — Anthropic didn't include it in the System Card.
This matters for agent builders. MCP Atlas measures how reliably a model chains tools across servers — discovering the right API, calling it with correct parameters, handling errors, and synthesizing results. It's the benchmark that most directly maps to production agent reliability. o-mega's analysis: "It leads the entire field (including Claude Opus 4.7 and GPT-5.5) on MCP Atlas, Toolathlon, Finance Agent v2, CharXiv Reasoning, and MMMU-Pro."
If your workflow involves orchestrating dozens of API calls across multiple services — the kind of work that defines enterprise AI agents — Gemini 3.5 Flash's MCP Atlas leadership is hard to ignore.
Speed: Gemini is 4× Faster
This is where the comparison gets lopsided. Google's announcement: "When looking at output tokens per second, it is 4 times faster than other frontier models." Independent measurements from Artificial Analysis put Gemini 3.5 Flash at ~289 tok/s. Claude Sonnet 4.6 runs at ~50-80 tok/s — and Sonnet 5 is expected to be comparable.
For interactive coding, real-time chat, and agent loops where latency compounds across dozens of turns, Gemini's speed advantage is transformative. A 10-turn agent conversation that takes 8 seconds on Sonnet might take 2 seconds on Gemini. That's the difference between feeling responsive and feeling sluggish.
| Metric | Claude Sonnet 5 | Gemini 3.5 Flash |
|---|---|---|
| Output speed | ~50-80 tok/s | ~289 tok/s (4× faster) |
| Time-to-first-token | ~1.3s | ~0.7s |
| Context window | 1M tokens | 1M tokens |
| Input price | $2 intro / $3 std | $1.50 |
| Output price | $10 intro / $15 std | $9.00 |
The Radar: Different Shapes, Different Strengths
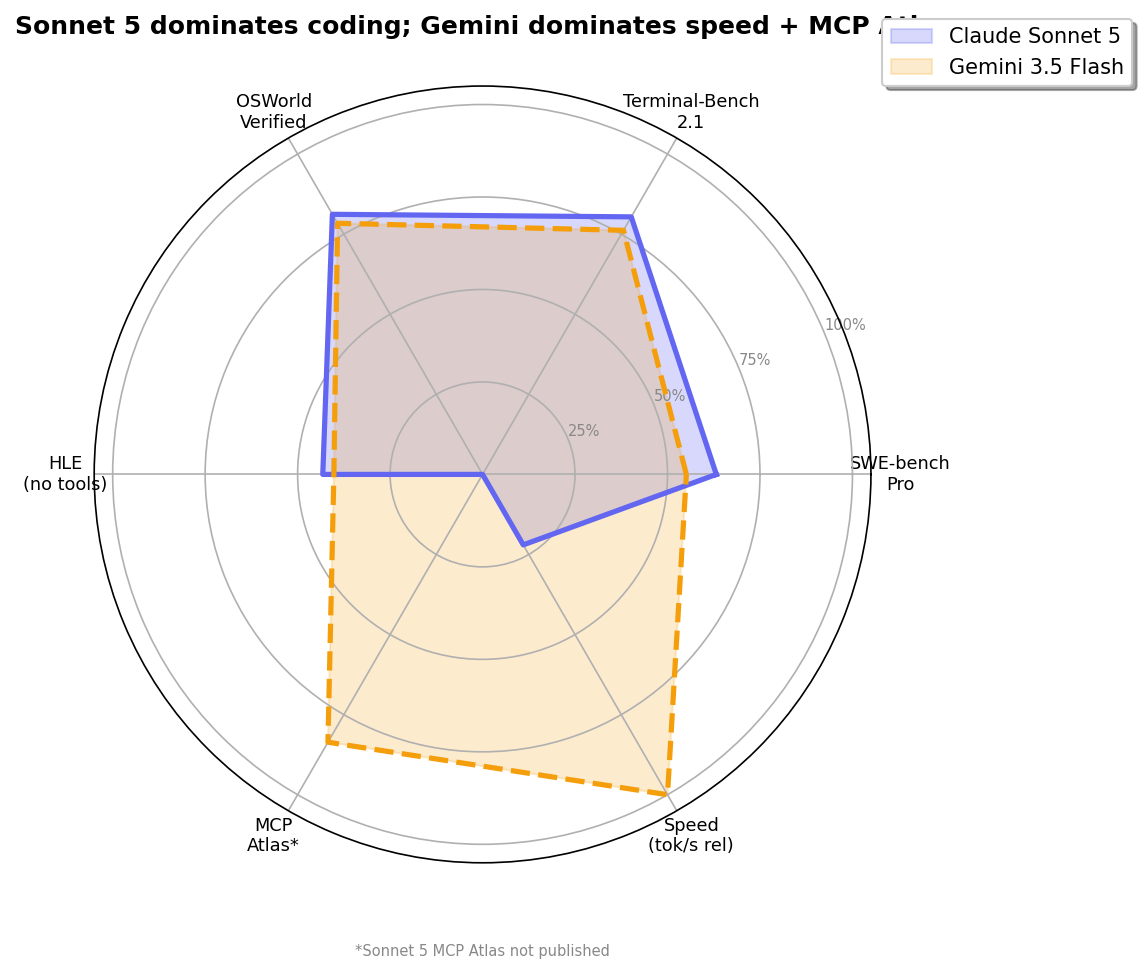
Where They Don't Overlap
| Benchmark | Claude Sonnet 5 | Gemini 3.5 Flash |
|---|---|---|
| BrowseComp (agentic search) | 84.7% | — (not published) |
| Knowledge work (GDPval-AA v2) | 1618 Elo | 1656 Elo (GDPval-AA, different version) |
| FrontierCode v1 | 38.8% | — (not published) |
| MCP Atlas | — (not published) | 83.6% — #1 vendor score |
| MMMU-Pro (multimodal) | — (not published) | 83.6% |
| CharXiv Reasoning | 88.3% (with tools) | 84.2% (no tools) |
| Finance Agent v2 | — (not published) | 57.9% |
| Toolathlon | 54.3% | 56.5% |
| ARC-AGI-2 | — (not published) | 72.1% |
| MRCR v2 (128k long context) | — (not published) | 77.3% |
Each vendor publishes different benchmarks. Anthropic emphasizes BrowseComp, FrontierCode, and safety. Google emphasizes MCP Atlas, multimodal benchmarks, and long-context evaluations. GDPval-AA versions differ — Anthropic uses v2 (220 tasks), Google uses an earlier version. Direct Elo comparison is unreliable across versions.
Safety: Anthropic's Unmatched Transparency
Anthropic's Sonnet 5 System Card is 145 pages. It covers RSP evaluations, cyber capabilities (ExploitBench, OSS-Fuzz, CyberGym, Firefox 147), agentic safety (malicious Claude Code use, computer use, prompt injection robustness), alignment assessment, and model welfare. Key metrics:
- Sycophancy: 3.1% (lowest of any Claude model)
- Prompt injection ASR (coding): 0.31%
- Malicious request refusal: 92.4%
- Factual hallucination: 26.5%
Google's Gemini 3.5 Flash Model Card is thorough by industry standards but doesn't match Anthropic's depth. For enterprises in regulated industries — finance, healthcare, government — Anthropic's safety documentation and compliance infrastructure is a genuine competitive advantage.
Should You Use Sonnet 5 or Gemini 3.5 Flash?
| If you... | Decision |
|---|---|
| Do heavy coding / Claude Code daily | 🔷 Sonnet 5. +8.1 Pro, +4.2 TB. Decisive. |
| Build MCP-heavy multi-tool agents | ✅ Gemini 3.5 Flash. 83.6% MCP Atlas. #1 score. |
| Need maximum speed and low latency | ✅ Gemini 3.5 Flash. 289 tok/s, 4× faster. |
| Want the cheapest per-token cost | ✅ Gemini 3.5 Flash. 2× cheaper on input. |
| Need computer use / GUI automation | 🔷 Sonnet 5. 81.2% OSWorld. Leads by 2.8. |
| Do multimodal work (charts, vision) | ✅ Gemini 3.5 Flash. CharXiv 84.2%, MMMU-Pro 83.6%. |
| Build for regulated industries | 🔷 Sonnet 5. 145-page System Card. Compliance infra. |
| Run high-volume agent pipelines | ✅ Gemini 3.5 Flash. Cheaper, faster, great at tool use. |
| Use both strategically (routing) | ✅ Best of both worlds. Sonnet for code, Gemini for orchestration. |
Conclusion: Depth vs Speed — Pick Your Weapon
Claude Sonnet 5 and Gemini 3.5 Flash represent two competing visions of what a mid-tier AI model should be. Sonnet 5 is the coding specialist — deeper reasoning, better SWE-bench scores, Anthropic's safety infrastructure, and the ecosystem that powers Claude Code. It's the model you want writing your code.
Gemini 3.5 Flash is the speed-and-tools generalist — faster, cheaper, the best MCP Atlas score in the industry, and multimodal capabilities that Sonnet hasn't demonstrated. It's the model you want orchestrating your tools.
Google's positioning: "Frontier intelligence at Flash speed." Anthropic's positioning: "The best combination of speed and intelligence." Both are telling the truth — they just define "best" differently. For coding, it's Sonnet. For everything else at scale, it's Gemini.
🔬 Side-by-Side Test
Run Claude Sonnet 5 and Gemini 3.5 Flash on your own code and agent workflows. Depth vs speed — your benchmarks are the only ones that matter.
🔄 Compare Side by Side →Sources & Links
- Anthropic — Claude Sonnet 5 System Card — Table 8.1.A capability evaluation summary
- Anthropic — Introducing Claude Sonnet 5 — official launch announcement
- Google DeepMind — Gemini 3.5 Flash Model Card — benchmark comparison table
- Google Blog — Gemini 3.5: Frontier Intelligence with Action
- o-mega — Gemini 3.5 Flash: Benchmarks, Cost & Guide
- NxCode — Gemini 3.5 Flash Complete Guide
- AI Builder Club — Gemini 3.5 Flash vs Claude Sonnet
- Avinash Sangle — Gemini 3.5 Flash for Agentic Coding
- Claude Platform Docs — Models Overview
Read This Next
- Claude Sonnet 5 vs Opus 4.8 — 93% of the power at 60% of the price
- Claude Sonnet 5 vs Sonnet 4.6 — the biggest Sonnet leap ever
- Claude Sonnet 5 vs GLM 5.2 — MIT vs Proprietary, near-ties everywhere