
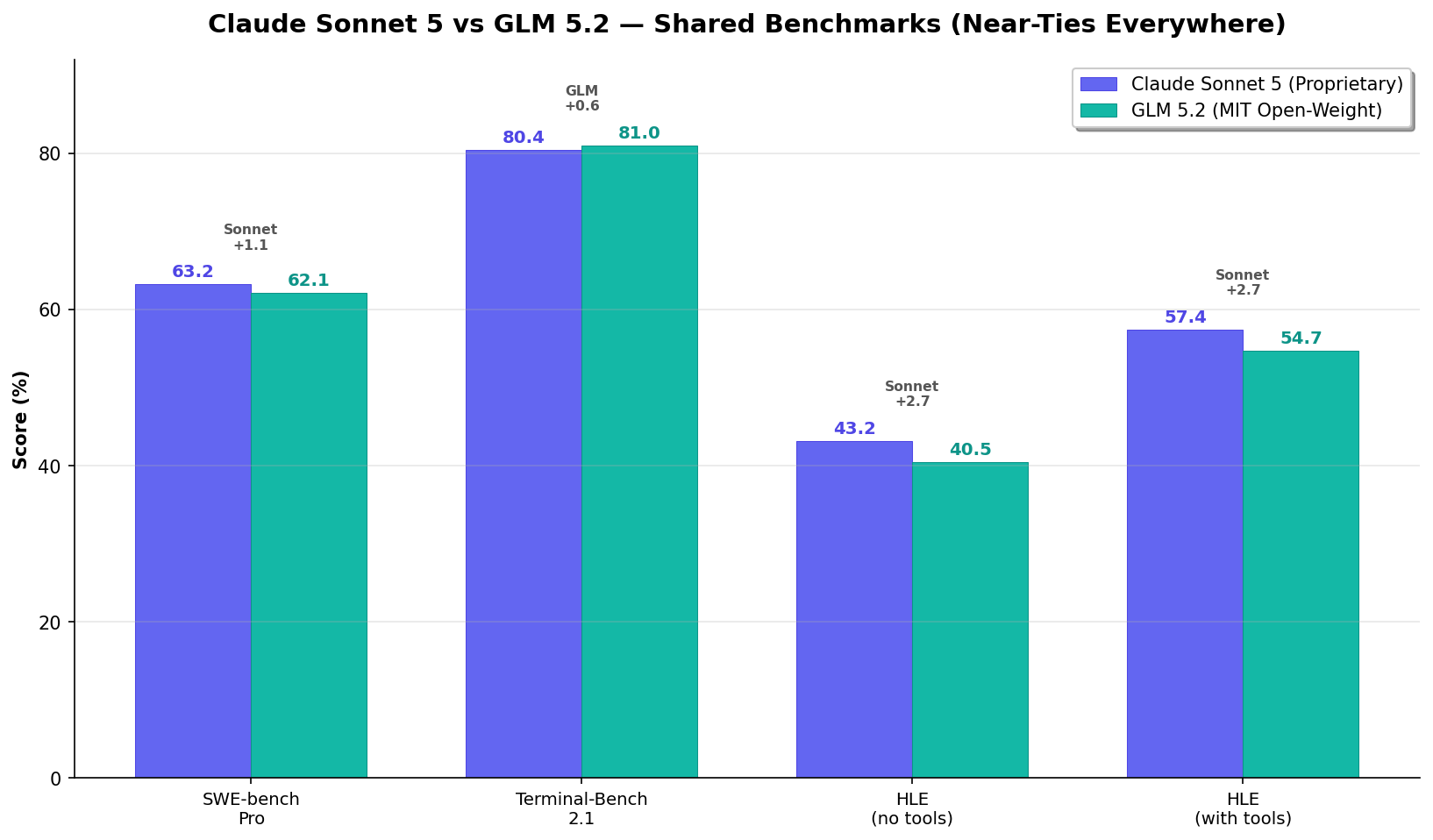
Two models. Two philosophies. One benchmark result: near-ties everywhere. Claude Sonnet 5 (63.2% Pro, proprietary, $3/$15) and GLM 5.2 (62.1% Pro, MIT open-weight, $1.40/$4.40) land within 1-3 points of each other on every shared benchmark. On SWE-bench Pro: Sonnet leads by 1.1. On Terminal-Bench 2.1: GLM leads by 0.6. On HLE: Sonnet leads by 2.7. These are not decisive gaps — they're margin-of-error differences. The real decision is about licensing, ecosystem, and cost. One model is 3.4× cheaper on output and you can self-host it. The other has the full Anthropic ecosystem, Claude Code, computer use, and better safety properties. Here's the complete comparison, sourced from Anthropic's Sonnet 5 System Card and Z.ai's GLM-5.2 launch blog. Test both on CodingFleet.
TL;DR — Sonnet 5 vs GLM 5.2
- Near-ties on all shared benchmarks: ±0.6 to ±2.7 point differences. Functionally equivalent coding capability.
- GLM leads Terminal-Bench by 0.6 pts: 81.0% vs 80.4%. The MIT model edges the proprietary one on CLI agentic coding.
- Sonnet leads SWE-bench Pro by 1.1 pts: 63.2% vs 62.1%. The narrowest possible Pro gap.
- GLM is 3.4× cheaper on output: $4.40 vs $15 per 1M. 2.1× cheaper on input ($1.40 vs $3).
- MIT vs Proprietary: GLM is fully open-weight, self-hostable. Sonnet is Anthropic API only.
- Ecosystem split: Sonnet has OSWorld, BrowseComp, GDPval, Claude Code. GLM has DeepSWE, FrontierSWE, MCP Atlas.
- Sonnet 5 wins on HLE (+2.7): Raw reasoning is the one area where the proprietary edge is clear.
Full Benchmark Comparison
| Benchmark | Claude Sonnet 5 | GLM 5.2 | Winner |
|---|---|---|---|
| SWE-bench Pro | 63.2% | 62.1% | Sonnet (+1.1) |
| Terminal-Bench 2.1 | 80.4% | 81.0% | GLM (+0.6) |
| HLE (no tools) | 43.2% | 40.5% | Sonnet (+2.7) |
| HLE (with tools) | 57.4% | 54.7% | Sonnet (+2.7) |
Shared benchmarks where both models have published scores. Sonnet 5 from Anthropic System Card. GLM 5.2 from Z.ai official blog cross-model comparison table. Both use vendor-reported scores — directly comparable within each vendor's harness, but different scaffolds between vendors introduce some uncertainty.
| Benchmark (non-shared) | Claude Sonnet 5 | GLM 5.2 |
|---|---|---|
| Computer use (OSWorld-Verified) | 81.2% | — (not published) |
| Agentic search (BrowseComp) | 84.7% | — (not published) |
| Knowledge work (GDPval-AA v2) | 1618 Elo | — (not published) |
| DeepSWE (deep engineering) | — (not published) | 46.2% |
| FrontierSWE (Dominance) | — (not published) | 74.4% |
| GPQA Diamond (PhD science) | — (not published) | 91.2% |
| MCP Atlas (tool orchestration) | — (not published) | 77.0% |
| AIME 2026 (competition math) | — (not published) | 99.2% |
| CritPt (critical reasoning) | — (not published) | 16.7 |
| ProgramBench (compiled-from-source) | 76-86% | 63.7% |
Each vendor publishes different benchmark suites. Anthropic emphasizes OSWorld, BrowseComp, GDPval, and safety evaluations. Z.ai emphasizes DeepSWE, FrontierSWE, GPQA, and MCP Atlas. Direct comparison on these is impossible — but the pattern is clear: Sonnet 5 leads on knowledge work and computer use; GLM 5.2 leads on deep engineering and specialized agentic tasks.
The Big Story: Functionally Tied on Coding
On the two benchmarks that matter most for developers — SWE-bench Pro (real GitHub bugs) and Terminal-Bench 2.1 (CLI agentic tasks) — these two models are separated by 0.6 and 1.1 points respectively. That's margin-of-error territory. If you're choosing between them based purely on coding benchmark numbers, you're splitting hairs.
SWE-bench Pro: Sonnet 5 at 63.2% vs GLM 5.2 at 62.1%. A 1.1-point difference. Z.ai's own comparison table places GLM 5.2's Pro score ahead of GPT-5.5 (58.6%) and just behind Qwen 3.7 Max (60.6%). Sonnet 5 edges it out, but the practical difference on a 1,865-task benchmark is ~20 tasks. For most development workflows, you wouldn't notice.
Terminal-Bench 2.1: GLM 5.2 at 81.0% vs Sonnet 5 at 80.4%. GLM leads by 0.6 points. This is the benchmark for real CLI work — package management, git operations, build debugging. Semgrep's independent testing found GLM 5.2 "genuinely competitive on coding" and noted it "posts the strongest open-weight numbers going." An MIT-licensed model matching a proprietary Anthropic model on terminal-based agentic coding is remarkable.
The Price Gap: GLM is 3.4× Cheaper on Output
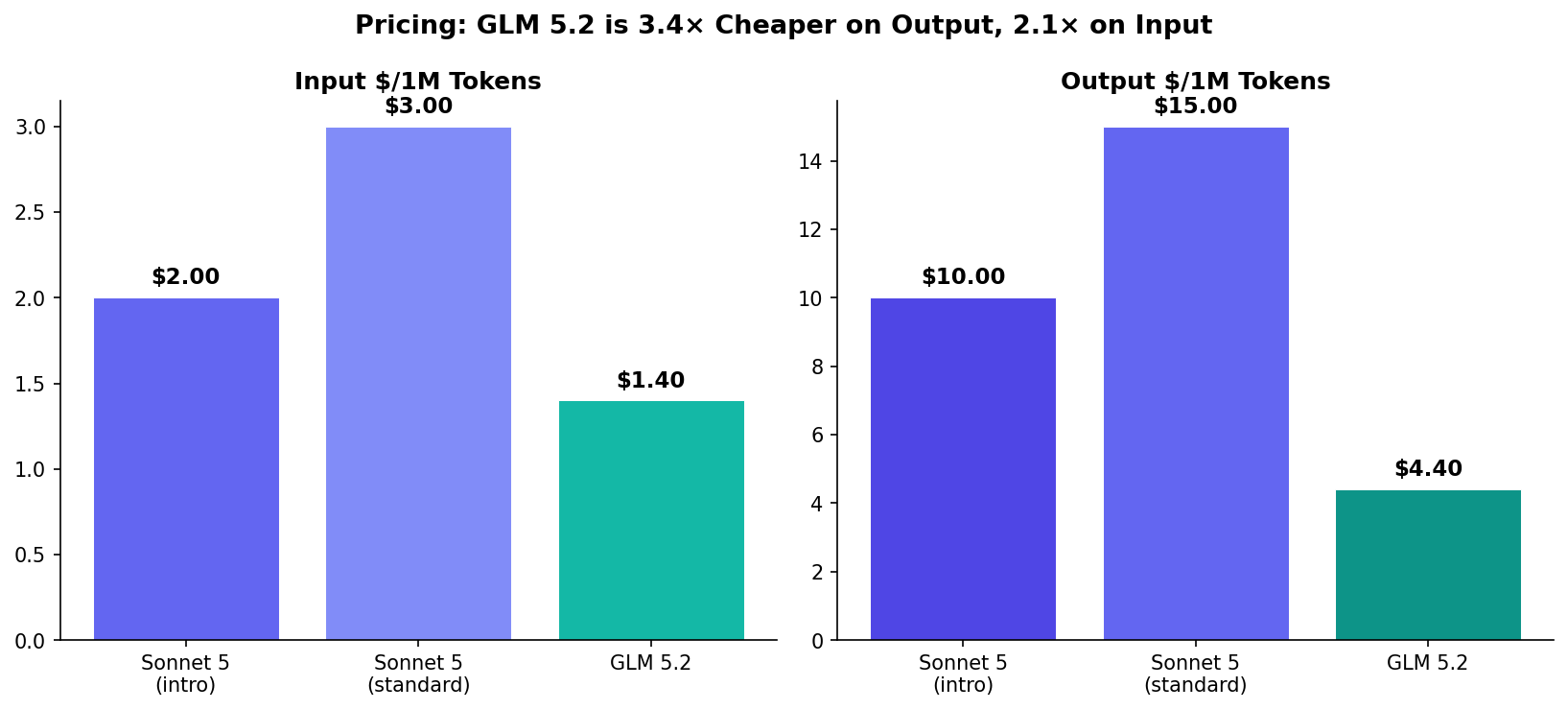
For a workload processing 10M input + 1M output tokens per day:
| Model | Daily Cost | Monthly Cost |
|---|---|---|
| GLM 5.2 | $18.40 | ~$552 |
| Sonnet 5 (introductory) | $30.00 | ~$900 |
| Sonnet 5 (standard) | $45.00 | ~$1,350 |
| Claude Opus 4.8 | $75.00 | ~$2,250 |
Assumes 90% input / 10% output split, 0.5× thinking multiplier, no caching. Real costs vary with workload patterns.
At $552/month for GLM 5.2 vs $1,350/month for Sonnet 5 (standard pricing), the annual difference is ~$9,600 — enough to hire a junior developer for a month. For teams running multiple agents or high-volume pipelines, GLM's cost advantage is compelling.
MIT vs Proprietary: The Fork in the Road
This is the decision that matters more than 1-point benchmark differences. GLM 5.2 is fully open-weight under the MIT license — you can download the weights, fine-tune it on your data, run it on your infrastructure, and never pay a per-token fee. Sonnet 5 is proprietary — Anthropic API only, no self-hosting, no fine-tuning, per-token pricing forever.
Choose GLM 5.2 if:
- You need to self-host or air-gap your models
- You want to fine-tune on proprietary codebases
- You're running high-volume agents where cost dominates
- You need MIT license for redistribution or embedding
Choose Sonnet 5 if:
- You need Claude Code / Anthropic ecosystem integration
- Computer use (OSWorld 81.2%) is core to your workflow
- You value Anthropic's safety research and alignment work
- You need BrowseComp-level web research (84.7%)
Ecosystem: Anthropic's Moat
GLM 5.2 is Anthropic API compatible — you can drop it into Claude Code by changing one environment variable. DataCamp's guide: "Z.ai explicitly recommends max effort for coding tasks." The dual thinking mode (High / Max) gives developers control over the cost-vs-depth tradeoff. And the 1M context window handles entire codebases in a single session.
But compatibility isn't the same as native integration. Sonnet 5 is the default model on claude.ai Free and Pro plans. It's deeply integrated into Claude Code, Claude Cowork, and the broader Anthropic platform. It has computer use (GUI automation), BrowseComp-grade web research, and Anthropic's safety infrastructure — prompt injection resistance at 0.31% ASR, sycophancy at 3.1%.
GLM 5.2 has its own strengths: Semgrep found it "surpassed a frontier coding agent" on their internal security benchmarks. Graphistry's testing showed GLM 5.2 "matches Opus on quality" for CyBT-CTF security investigations and "defeats Sonnet" on the same benchmark. GLM's FrontierSWE score (74.4%) and DeepSWE (46.2%) suggest strengths in long-horizon software engineering that Anthropic doesn't benchmark Sonnet 5 against.
Safety: The Unspoken Differentiator
Anthropic publishes extensive safety evaluations. Sonnet 5's System Card is 145 pages covering RSP evaluations, cyber capabilities, agentic safety, alignment assessment, and model welfare. GLM 5.2's safety profile is less documented.
Key Sonnet 5 safety metrics vs Sonnet 4.6 (no GLM comparison available):
- Sycophancy: 3.1% (lowest of any Claude model)
- Prompt injection ASR (coding): 0.31%
- Malicious request refusal: 92.4%
- Factual hallucination: 26.5%
For enterprises in regulated industries or those with strict safety requirements, Anthropic's safety infrastructure and transparency may justify the premium on its own.
Speed: GLM is Faster
BetterClaw's testing (comparing GLM 5.2 to Sonnet 4.6): GLM 5.2 generates output at 113 tokens/second with 2.24s time-to-first-token. Sonnet models run at approximately 50-80 tok/s. On High mode, GLM is consistently faster. On Max mode, the reasoning step adds latency but total generation remains competitive.
For real-time chat or interactive coding, GLM 5.2 on High mode delivers lower latency and faster generation. For background batch processing, both models perform well, but GLM's speed advantage compounds with the cost advantage.
Specification Comparison
| Feature | Claude Sonnet 5 | GLM 5.2 |
|---|---|---|
| Provider | Anthropic (San Francisco) | Z.AI / Zhipu AI (Beijing) |
| Released | June 30, 2026 | June 13, 2026 |
| License | Proprietary | MIT (open-weight) |
| Architecture | — (undisclosed) | 753B MoE (~40B active) |
| Context Window | 1,000,000 tokens | 1,000,000 tokens |
| Max Output | 128K (300K batch) | 131,072 tokens |
| Thinking Modes | Adaptive (effort levels) | Dual: High / Max |
| Multimodal | Text + Image input | Text only |
| API Compatibility | Native Anthropic API | Anthropic API native |
| Inference Speed | ~50-80 tok/s | ~113 tok/s |
| Input Price | $2/$10 intro; $3/$15 std | $1.40 / $4.40 |
| Self-hostable | No | Yes (MIT) |
Sources: Claude Platform Docs, Z.ai GLM-5.2 blog, DataCamp spec comparison. Inference speed from BetterClaw testing (Sonnet 4.6 proxy; Sonnet 5 expected comparable).
Should You Use Sonnet 5 or GLM 5.2?
| If you... | Decision |
|---|---|
| Need the cheapest near-frontier coding model | ✅ GLM 5.2. 3.4× cheaper output. MIT license. |
| Want to self-host or fine-tune | ✅ GLM 5.2. Open weights. Run anywhere. |
| Use Claude Code / Anthropic ecosystem daily | 🔷 Sonnet 5. Native integration matters. |
| Need computer use (GUI automation) | 🔷 Sonnet 5. 81.2% OSWorld. GLM unpublished. |
| Run high-volume terminal agents | ✅ GLM 5.2. Leads TB 2.1. Much cheaper at scale. |
| Value safety transparency / alignment research | 🔷 Sonnet 5. 145-page System Card. Proven safety. |
| Need the best raw reasoning (HLE, math) | 🔷 Sonnet 5. +2.7 on HLE. Better documented reasoning. |
| Are in a regulated industry (finance, healthcare) | 🔷 Sonnet 5. Anthropic's compliance infrastructure. |
| Build for the open-source ecosystem | ✅ GLM 5.2. MIT license. Embed anywhere. |
Conclusion: The Commoditization of Frontier Coding
Claude Sonnet 5 and GLM 5.2 are the strongest evidence yet that frontier coding capability is commoditizing. A proprietary model from a San Francisco lab and an MIT open-weight model from Beijing deliver functionally identical performance on the two benchmarks developers care about most. The 1.1-point Pro gap and 0.6-point TB gap are statistical noise.
The decision between them is not about capability — it's about everything else. Cost (GLM wins decisively). Licensing (MIT vs proprietary). Ecosystem (Anthropic's integrated platform vs open-weight flexibility). Safety (Anthropic's documented edge). Speed (GLM's 113 tok/s). Computer use (Sonnet's exclusive domain).
Z.ai's positioning: "GLM-5.2 marks a substantial leap in long-horizon task capability." Anthropic's positioning: "Its performance is close to that of Opus 4.8, but at lower prices." Both are telling the truth. The question is which truth matters more for your workflow — and your budget.
🔬 Side-by-Side Test
Run Claude Sonnet 5 and GLM 5.2 on your own code. See if you can tell the difference. MIT open-weight vs Anthropic proprietary — your codebase is the real benchmark.
🔄 Compare Side by Side →Sources & Links
- Anthropic — Claude Sonnet 5 System Card — Table 8.1.A capability evaluation summary
- Anthropic — Introducing Claude Sonnet 5 — official launch announcement
- Z.ai — GLM-5.2: Built for Long-Horizon Tasks — cross-model benchmark table
- Apidog — GLM-5.2 Benchmarks and Specs
- Semgrep — GLM 5.2 beats Claude in our cyber benchmarks
- Graphistry — GLM 5.2 Open Model: Beats Sonnet, Matches Opus in Cyber Evals
- BetterClaw — GLM 5.2 vs Sonnet 4.6: 7 Agent Tasks Tested
- Hugging Face — GLM-5.2 Blog — full benchmark table
- DataCamp — GLM-5.2 features, setup, spec comparison
- Claude Platform Docs — Models Overview
Read This Next
- Claude Sonnet 5 vs Opus 4.8 — 93% of the power at 60% of the price
- Claude Sonnet 5 vs Sonnet 4.6 — the biggest Sonnet leap ever
- GLM-5.2 vs GLM-5.1 — +28 DeepSWE, 5× context