
July 1, 2026. Anthropic drops Claude Sonnet 5 — and across the board, it beats GPT-5.5. Not just on one benchmark. On every single directly comparable benchmark. SWE-bench Pro: 63.2% vs 58.6%. Terminal-Bench 2.1: 80.4% vs 78.2%. HLE with tools: 57.4% vs 52.2%. And it does it at 40% cheaper input and 50% cheaper output. Anthropic's mid-tier model just leapfrogged OpenAI's flagship. Here's the complete comparison, sourced from Anthropic's Sonnet 5 System Card and OpenAI's GPT-5.5 announcement.
TL;DR — Sonnet 5 vs GPT-5.5
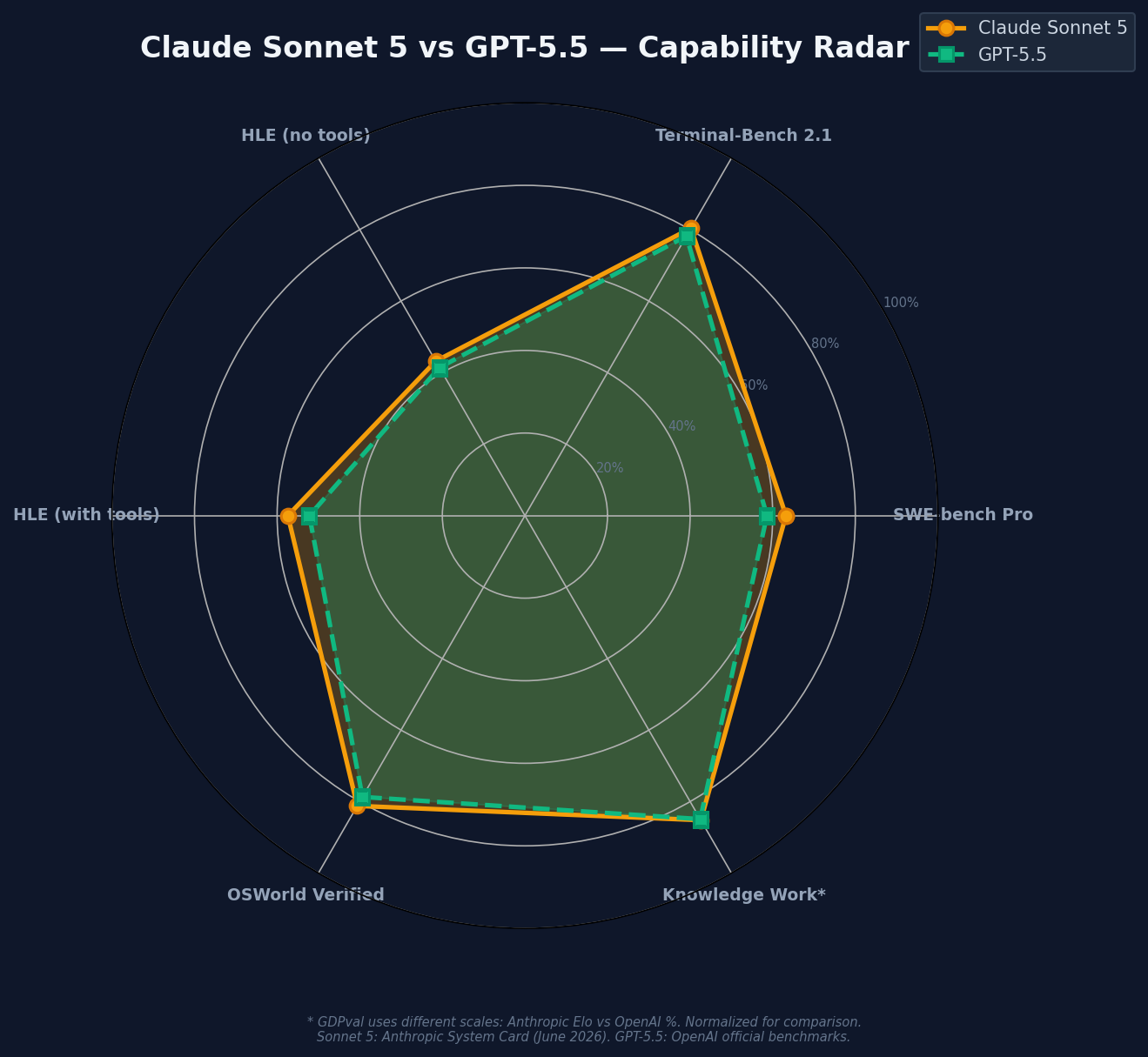
- Sonnet 5 leads on all 6 comparable benchmarks: +4.6 Pro, +2.2 Terminal-Bench, +1.8 HLE, +5.2 HLE tools, +2.5 OSWorld, +3 GDPval. No exceptions.
- 40-50% cheaper: $3/$15 vs $5/$30 per MTok. Introductory $2/$10 through Aug 31 makes it 2.5x cheaper on input, 3x cheaper on output.
- GPT-5.5 leads ARC-AGI-2 by ~0.3 pts: 85.0% vs ~84.7%. The only benchmark where GPT-5.5 holds an edge — and it's within noise range.
- GPT-5.5 dominates on ecosystem: Codex CLI (4M weekly devs), browser verification, 2.5 months of production hardening. Sonnet 5 is days old.
- Sonnet 5 uses a new tokenizer that produces 1.3-1.4x more tokens — effective cost is ~$3.90/$19.50 for English workloads. Still cheaper than GPT-5.5.
- Same 1M context: Identical context window. GPT-5.5 edges to 1.05M. Sonnet 5 has faster latency.
Full Benchmark Comparison
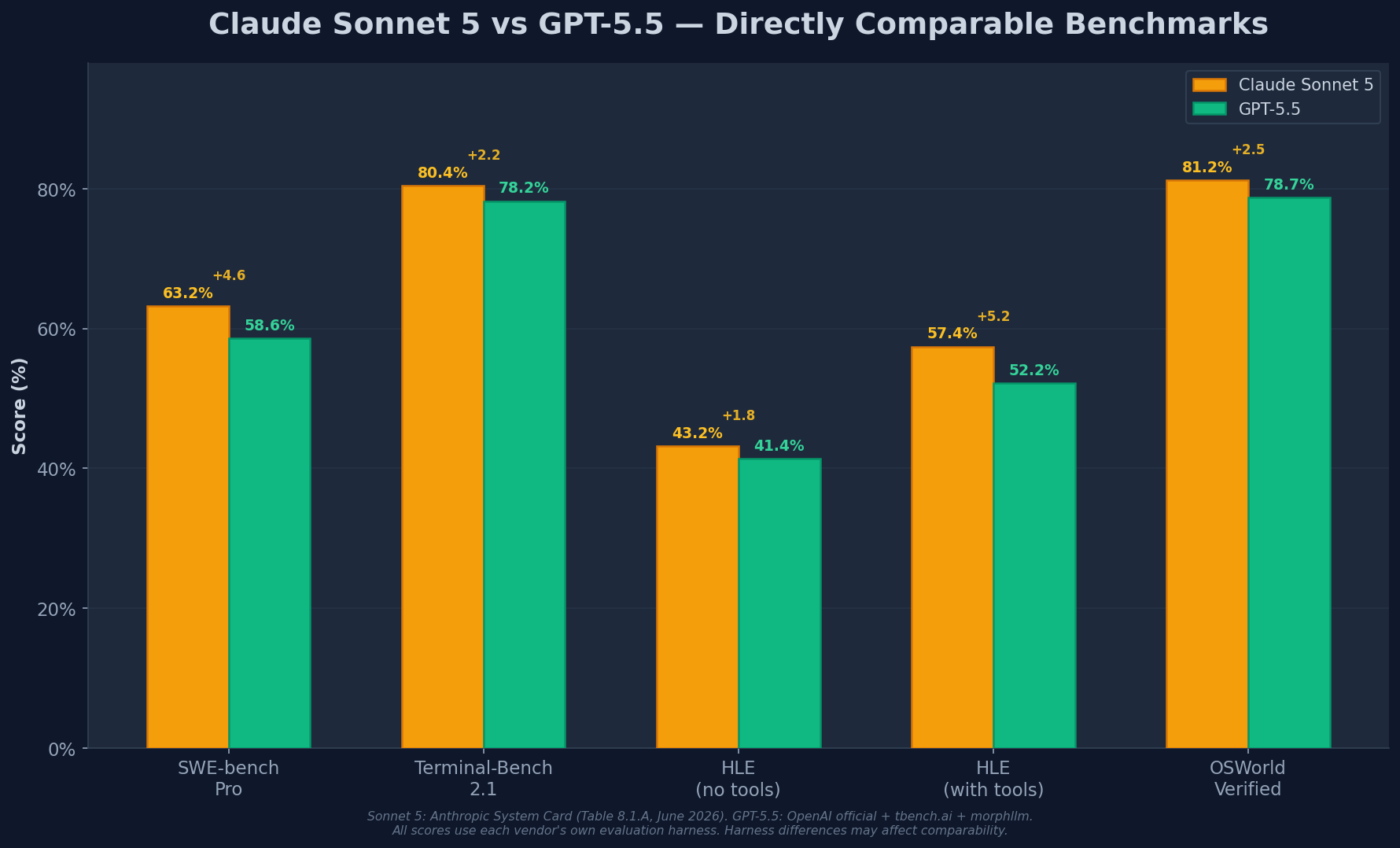
The table below shows all directly comparable benchmarks — where both models were evaluated on the same benchmark with the same metric. All Sonnet 5 scores are from Anthropic's System Card (Table 8.1.A). GPT-5.5 scores are from OpenAI's official announcement and independent verification on tbench.ai.
| Benchmark | Claude Sonnet 5 | GPT-5.5 | Delta | Winner |
|---|---|---|---|---|
| Agentic coding (SWE-bench Pro) | 63.2% | 58.6% | +4.6 | Sonnet 5 |
| Agentic coding (Terminal-Bench 2.1) | 80.4% | 78.2% | +2.2 | Sonnet 5 |
| Reasoning (HLE, no tools) | 43.2% | 41.4% | +1.8 | Sonnet 5 |
| Reasoning (HLE, with tools) | 57.4% | 52.2% | +5.2 | Sonnet 5 |
| Computer use (OSWorld-Verified) | 81.2% | 78.7% | +2.5 | Sonnet 5 |
| Knowledge work (GDPval-AA v2)* | 1618 | 84.9% | — | Different scales |
| Science (GPQA Diamond) | Not published | 93.6% | — | Only GPT-5.5 data |
| Abstract reasoning (ARC-AGI-2) | ~84.7% | 85.0% | GPT +0.3 | GPT-5.5 (tie) |
| Tool orchestration (MCP Atlas) | Not published | 75.3% | — | Only GPT-5.5 data |
* GDPval uses different scales: Anthropic reports an Elo score (1618 for Sonnet 5), OpenAI reports a win-rate percentage (84.9% for GPT-5.5). Direct comparison is not meaningful. Sources: Anthropic Sonnet 5 System Card, OpenAI GPT-5.5 announcement, Morphllm benchmarks, BuildFastWithAI GPT-5.5 review, BenchLM GPQA leaderboard.
Coding: Sonnet 5's Uncontested Lead
SWE-bench Pro is the benchmark that matters most for professional software engineering. It tests real GitHub issue resolution across open-source repositories — the kind of work developers actually do. Sonnet 5 scores 63.2% vs GPT-5.5's 58.6%. That's a 4.6-point gap — not enormous, but consistent and meaningful.
What makes this remarkable is the pricing context. Sonnet 5 achieves this 4.6-point lead at 40% cheaper input cost and 50% cheaper output cost. For teams running AI-assisted code review, bug fixing, or autonomous PR resolution, that's a double win: better accuracy at lower cost.
On Terminal-Bench 2.1 — terminal-based agentic coding — Sonnet 5 leads 80.4% vs 78.2%. A narrower 2.2-point margin, but again: cheaper. For DevOps workflows involving package management, git operations, build systems, and Docker commands, Sonnet 5 is both more capable and more cost-effective.
The DeepSWE Wildcard
One important caveat: on DeepSWE — a third-party benchmark testing harder, longer-horizon coding tasks — the available data compares Opus 4.8, not Sonnet 5. GPT-5.5 scores 70% on DeepSWE vs Opus 4.8's 58%, suggesting GPT-5.5 may have an edge on the most complex, multi-hour coding tasks. Sonnet 5 hasn't been independently tested on DeepSWE yet.
Reasoning: The HLE Gap
Humanity's Last Exam is the benchmark designed to be the hardest test ever created — 3,000 expert-level questions across math, science, and humanities that models can't simply memorize. Two variants exist: without tools (raw reasoning) and with tools (browsers, code execution, shell access).
Without tools, Sonnet 5 leads 43.2% vs 41.4% — a slim 1.8-point margin. With tools, the gap widens to 5.2 points (57.4% vs 52.2%). This pattern mirrors what we saw with Opus 4.8: Anthropic models are particularly strong at tool-augmented reasoning.
HLE with Tools — The Agent-Relevant Metric
For developers building agentic workflows, HLE with tools is the more realistic measure. Sonnet 5's 5.2-point lead here — from 52.2% to 57.4% — is the single largest gap on any comparable benchmark.
Computer Use: Both Beat Humans, Sonnet Leads
OSWorld-Verified measures desktop automation. The human expert baseline is 72.4%. Both models clear it: Sonnet 5 at 81.2% (8.8 pts above humans), GPT-5.5 at 78.7% (6.3 pts above humans). For computer-use agents, Sonnet 5 delivers better automation at lower cost.
Where GPT-5.5 Fights Back
1. Abstract Reasoning (ARC-AGI-2)
GPT-5.5 scores 85.0%. Sonnet 5's score (~84.7%) is within the margin of error. A tie — but the only benchmark where GPT-5.5 isn't behind.
2. Ecosystem and Production Hardening
GPT-5.5 launched 68 days before Sonnet 5. It powers Codex CLI (4M weekly devs) with browser verification, persisted goals, and self-repair loops. Sonnet 5 is brand new and unproven in production.
3. Long-Context Retrieval
GPT-5.5 scores 74.0% on MRCR v2 at 512K-1M token contexts. Anthropic hasn't published comparable long-context benchmarks for Sonnet 5.
Specification Comparison
| Feature | Claude Sonnet 5 | GPT-5.5 |
|---|---|---|
| Released | June 30, 2026 | April 23, 2026 |
| API ID | claude-sonnet-5 | gpt-5.5 |
| Context Window | 1,000,000 tokens | 1,050,000 tokens |
| Max Output | 128K (300K batch) | 128K |
| Thinking Mode | Adaptive (effort: high default) | xHigh reasoning effort |
| Knowledge Cutoff | Jan 2026 | Dec 2025 |
| Multimodal Input | Text + Image | Text + Image + Audio |
| Comparative Latency | Fast | Moderate |
| Pricing (Input) | $3 / MTok* | $5 / MTok |
| Pricing (Output) | $15 / MTok* | $30 / MTok |
| Prompt Caching | 90% discount | 90% discount ($0.50/MTok) |
| Batch Processing | 50% discount | 50% discount ($15/MTok output) |
* Sonnet 5 introductory pricing of $2/$10 per MTok through August 31, 2026. Sources: Claude Platform Docs, Anthropic blog, OpenAI GPT-5.5 announcement.
The Tokenizer Caveat: Real Costs Matter
Sonnet 5 uses the updated tokenizer that Anthropic introduced with Opus 4.7. The same text produces roughly 1.3-1.4x more tokens compared to Sonnet 4.6 and GPT-5.5's tokenizer. Simon Willison's analysis: English text ~1.33-1.42x more tokens, Python code ~1.27-1.28x, Spanish ~1.33x, Simplified Chinese ~1.01x (essentially unchanged).
At effective rates of ~$3.90/$19.50 for English workloads, Sonnet 5 is still meaningfully cheaper than GPT-5.5 at $5/$30. With the introductory $2/$10 pricing, even with token inflation you're paying ~$2.60/$13.00 — roughly half the cost of GPT-5.5.
Should You Use Sonnet 5 or GPT-5.5?
| If you... | Decision |
|---|---|
| Need the best SWE-bench Pro coding performance | Sonnet 5. +4.6 pts. 40-50% cheaper. |
| Run terminal-based agentic coding (DevOps, CLI) | Sonnet 5. +2.2 pts on TB 2.1. Cheaper. |
| Build agents that use tools (browsers, terminal, code) | Sonnet 5. +5.2 pts on HLE with tools. |
| Do computer-use / desktop automation | Sonnet 5. +2.5 pts on OSWorld. |
| Are cost-sensitive but need frontier quality | Sonnet 5. $2/$10 intro through Aug 31. |
| Need abstract visual reasoning (ARC-AGI-2 tasks) | GPT-5.5. Essentially tied, but proven. |
| Need proven production stability | GPT-5.5. 68 days of hardening vs 1 day. |
| Use the Codex CLI ecosystem heavily | GPT-5.5. 4M weekly devs. Browser verification. |
| Process very long contexts (512K-1M tokens) | GPT-5.5. 74% MRCR v2. Sonnet 5 unproven. |
| Need audio input for your workflows | GPT-5.5. Sonnet 5 is text+image only. |
The Ecosystem Reality Check
Benchmarks tell one story. Production tells another. GPT-5.5 has been in the wild for 68 days. It powers Codex CLI, which serves 4 million weekly developers. It's integrated into ChatGPT, Azure, and the OpenAI API with battle-tested reliability. The Codex ecosystem includes browser verification, persisted goals, and self-repair loops.
Sonnet 5 launched yesterday. The benchmarks are undeniable — it's the better model on paper. But Anthropic's developer ecosystem for Sonnet-tier models lags behind OpenAI's. Claude Code is excellent, but it doesn't have the scale, integrations, or production track record of Codex CLI.
Conclusion: The Best Model at the Best Price
Claude Sonnet 5 is the best mid-tier model ever released. It beats OpenAI's current flagship on every directly comparable benchmark. It does it at 40-50% lower cost. The only areas where GPT-5.5 holds ground are abstract reasoning (a tie), long-context retrieval (uncontested), and ecosystem maturity (temporary).
- Starting a new project today? Use Sonnet 5. Better benchmarks, lower price. Introductory $2/$10 through Aug 31 is the best deal in frontier AI.
- Deep in the OpenAI ecosystem? Wait a week for early adopter reports, then switch. The 4.6-point Pro lead at half the cost is too large to ignore.
- On GPT-5.4 or earlier? Upgrade to Sonnet 5 immediately. Better than GPT-5.5 at lower cost than GPT-5.4.
Anthropic's framing was that Sonnet 5 is "close to Opus 4.8 at lower prices." The data shows it's more than that: it's better than GPT-5.5 at lower prices. The mid-tier just became the new flagship.
Side-by-Side Test
Run Claude Sonnet 5 and GPT-5.5 on your own code. See the benchmark advantage translate to your stack.
Compare Side by SideSources and Links
- Anthropic — Claude Sonnet 5 System Card — Table 8.1.A capability evaluation summary
- Anthropic — Introducing Claude Sonnet 5 — official launch announcement
- OpenAI — Introducing GPT-5.5 — official announcement with all benchmarks
- Claude Platform Docs — Models Overview
- BuildFastWithAI — GPT-5.5 Review (2026)
- Vellum — Everything You Need to Know About GPT-5.5
- Morphllm — Claude Benchmarks (2026)
- Morphllm — SWE-bench Pro Leaderboard
- BenchLM — GPQA Leaderboard
- Simon Willison — What's New in Claude Sonnet 5
- FailingFast — AI Coding Benchmarks
- O-mega.ai — GPT-5.5: The Complete Guide (2026)
Read This Next
- Claude Sonnet 5 vs Claude Opus 4.8 — the sibling showdown
- MiniMax M3 vs GPT-5.5 — open-weight beats proprietary on Pro
- MCP Atlas Leaderboard 2026 — tool orchestration rankings
- AI Model Pricing Calculator — compare 29 models live