
Here's a sentence nobody expected to read in 2026: Alibaba's Qwen 3.7 Max beats OpenAI's GPT-5.5 on the hardest coding benchmark. SWE-bench Pro: Qwen 60.6%, GPT-5.5 58.6%. LiveCodeBench: Qwen 91.6%, GPT-5.5 ~91%. MCP-Atlas tool use: Qwen 76.4%, GPT-5.5 75.3%. And it costs 4× less — $7.50 vs $30 per million output tokens. But GPT-5.5 doesn't roll over: it dominates Terminal-Bench by 13 points (82.7% vs 69.7%), leads DeepSWE (70% vs untested), crushes ARC-AGI-2 (85% vs unknown), and brings omnimodal + cybersecurity + the Codex ecosystem. The coding crown is contested. The budget argument is settled. Here's the complete data. Test both on CodingFleet.
📊 Key Findings
- Qwen 3.7 Max beats GPT-5.5 on SWE-bench Pro (60.6% vs 58.6%). The hardest coding benchmark — real GitHub issues, multi-file diffs, production repositories. Qwen is +2.0 points ahead. This is the highest proprietary score on Pro. For bug-fixing in Python repos, Qwen is measurably better.
- GPT-5.5 dominates Terminal-Bench by 13 points (82.7% vs 69.7%). For CLI agent coding — installing packages, debugging configs, chaining commands — GPT-5.5 is in a different league. Plus DeepSWE at 70% and Expert-SWE at 73.1%.
- 4× price gap: Qwen $7.50 vs GPT-5.5 $30 per 1M output. With June promotion ($3.75/1M), it's 8× cheaper. Qwen is far more verbose — 97M tokens on the AA Intelligence Index vs a 24M token average — so cap
max_tokensto control real costs. - Qwen hallucinates 3.8× less (22.9% vs 86%). When GPT-5.5 doesn't know, it fabricates 86% of the time. Qwen stays quiet. For unattended coding agents, this calibration gap is decisive.
Compare models on your own code at CodingFleet — 20+ LLMs, side-by-side.
Benchmark Comparison
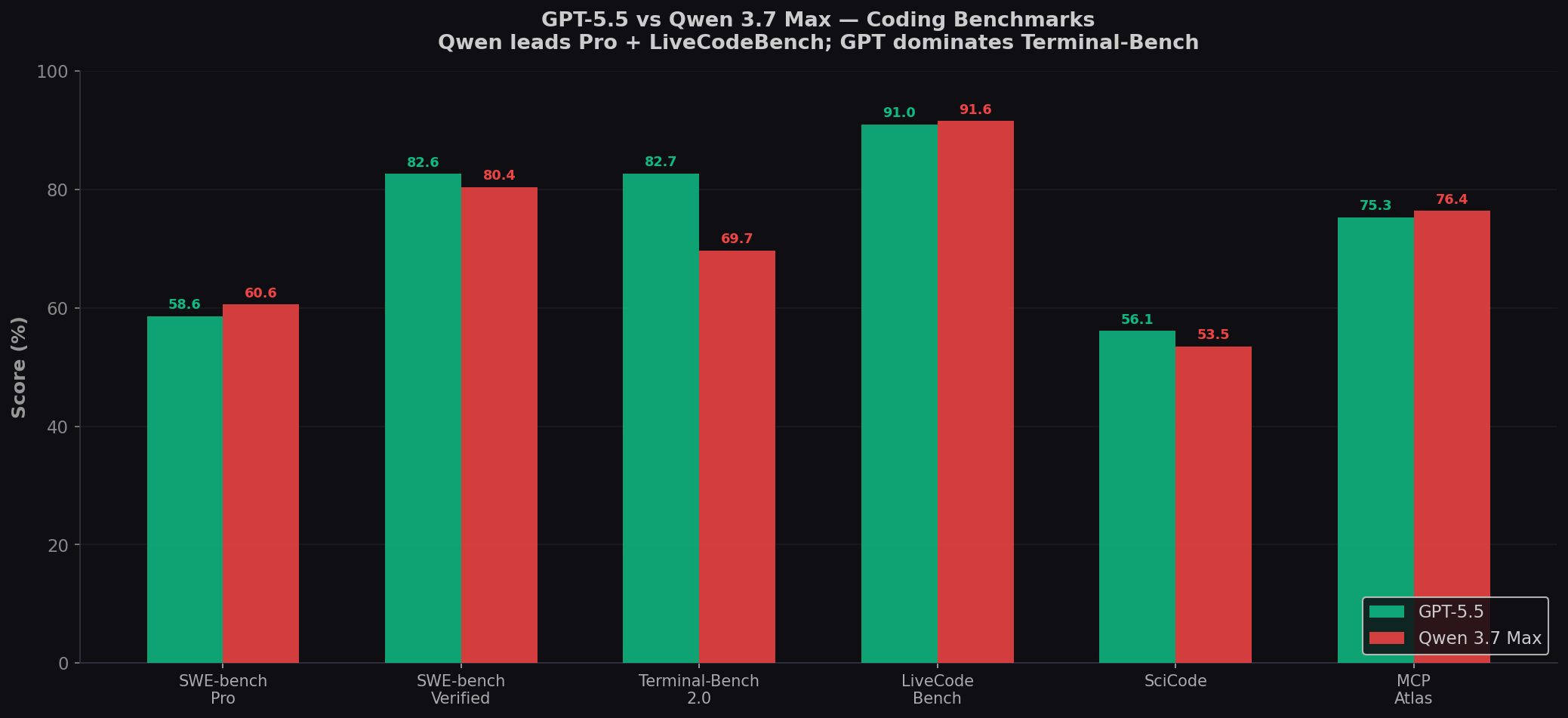
| Benchmark | GPT-5.5 | Qwen 3.7 Max | Winner |
|---|---|---|---|
| SWE-bench Pro | 58.6% | 60.6% | Qwen (+2.0) |
| SWE-bench Verified | ~82.6% | 80.4% | GPT (+2.2) |
| Terminal-Bench 2.0 | 82.7% | 69.7% | GPT (+13.0) |
| LiveCodeBench | ~91.0% | 91.6% | Qwen (+0.6) |
| SciCode | 56.1% | 53.5% | GPT (+2.6) |
| DeepSWE | 70% | — | GPT |
| MCP-Atlas (tool use) | 75.3% | 76.4% | Qwen (+1.1) |
| GPQA Diamond | 93.6% | 92.4% | GPT (+1.2) |
| HLE (no tools) | 41.4% | 41.4% | Tie |
| HMMT 2026 Feb | — | 97.1% | Qwen |
| Apex Math Reasoning | — | 44.5 | Qwen |
| ARC-AGI-2 (xHigh/High) | 85.0% | — | GPT |
| AA Intelligence Index | 60.2 (#2) | 56.6 (#5) | GPT (+3.6) |
| AA-Omniscience Hallucination | 86% | 22.9% | Qwen (3.8× lower) |
| Output Price /1M tok | $30.00 | $7.50 | Qwen (4× cheaper) |
| Input Price /1M tok | $5.00 | $2.50 | Qwen (2× cheaper) |
| Context Window | 1M (400K in Codex) | 1M | Tie |
| Max Output | 128K | 65K | GPT |
| API Compatibility | OpenAI spec | OpenAI + Anthropic specs | Qwen |
| Multimodal | Text + Image + Audio + Video | Text only | GPT |
Sources: Yotta Labs — Qwen 3.7 Max; Overchat — Qwen Scores; BenchLM — GPT vs Qwen; DeepSWE Leaderboard; Artificial Analysis; ARC Prize. Qwen scores vendor-published vs Opus 4.6. GPT-5.5 scores from Anthropic system card, AA, and Datacurve. Qwen DeepSWE and ARC-AGI-2 not published.
Agentic Coding Radar
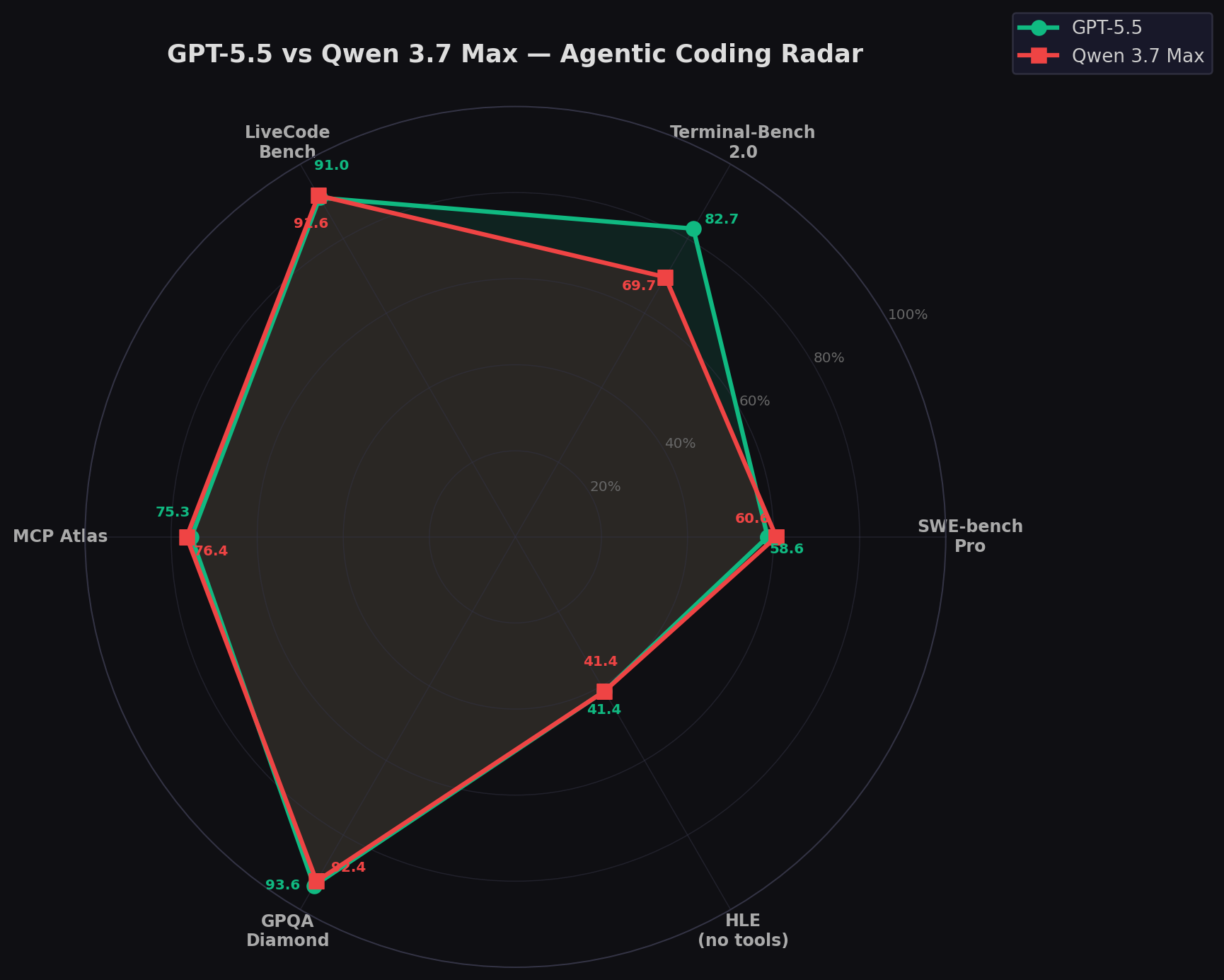
The radar tells the visual story immediately: Qwen's purple peak on SWE-bench Pro and LiveCodeBench vs GPT-5.5's green spike on Terminal-Bench. They mirror each other on GPQA, HLE, and MCP-Atlas. This isn't a winner-takes-all comparison — it's two models optimized for different coding philosophies.
Architecture & Ecosystem
GPT-5.5: The Generalist Powerhouse
Released April 23, 2026 — 49 days after GPT-5.4. GPT-5.5 is OpenAI's most capable general-purpose model, dethroned only recently by Claude Opus 4.8 on the AA Intelligence Index (60.2 vs 61.4). It's natively omnimodal — text, images, audio, and video in a single unified architecture. Co-designed with NVIDIA's GB200/GB300 NVL72 systems, it matches GPT-5.4's latency while being significantly more capable. The model rewrote OpenAI's own serving infrastructure, writing custom load-balancing heuristics that increased token speeds by 20%+.
GPT-5.5 powers Codex — OpenAI's unified agentic coding system spanning terminal CLI, IDE extensions, GitHub bot, and screen-reading capabilities. Codex features persisted goals, browser verification, parallel sandboxing, and a plugin marketplace. Over 4 million developers use Codex weekly; NVIDIA has 10,000+ employees on GPT-5.5-powered Codex. The cybersecurity capability is rated "High" under OpenAI's Preparedness Framework: 93.3% cyber range pass rate, 81.8% CyberGym. GPT-5.5 also leads ARC-AGI-2 at 85.0% — the strongest abstract reasoning score of any model.
Qwen 3.7 Max: The Agent Frontier
Launched May 19, 2026 at Alibaba Cloud Summit — nine days before Opus 4.8. Qwen Team calls it "The Agent Frontier," built for long-horizon autonomous execution with up to 35 hours of continuous operation and 1,000+ sequential tool calls. The architecture emphasizes "cross-harness generalization" — working across diverse agent frameworks without framework-specific tuning. Training methodology uses decoupled tasks, execution frameworks, and validators with cross-framework reinforcement learning to avoid shortcut overfitting.
The headline feature: native Anthropic API protocol support at the endpoint level. Set ANTHROPIC_MODEL="qwen3.7-max", configure the base URL to DashScope or OpenRouter, and Claude Code, Continue, Aider, or OpenClaw work unchanged. Qwen also supports the OpenAI API spec — dual-ecosystem compatibility. On Kernel Bench L3: 1.98× median kernel speedup with 96% win rate — competitive with Opus 4.6 on low-level GPU optimization. The model is proprietary (API-only via Alibaba Cloud Model Studio), not open-weight. 1M context window, 65K max output tokens.
Where Each Model Wins at Coding
GPT-5.5 — The DevOps & CLI King
- Terminal-Bench 82.7% vs 69.7% (+13 points). The widest gap between these models on any benchmark. For CLI agent coding — installing packages, debugging configurations, chaining commands, environment interaction — GPT-5.5 is in a different league. Under its native Codex CLI harness, it reportedly reaches 83.4%.
- DeepSWE 70% (vs Qwen untested). On the hardest independent coding benchmark — 113 tasks averaging 668 lines across 7 files — GPT-5.5 leads all models tested. Qwen hasn't been evaluated on DeepSWE yet, which is itself a data point.
- SciCode 56.1% vs 53.5%. For scientific coding — physics simulations, mathematical models, domain-specific algorithms — GPT-5.5 has a narrow edge.
- Codex ecosystem: Persisted goals, browser verification, parallel sandboxing, plugin marketplace, 4M weekly developers. The most mature agentic coding platform. See our full GPT-5.5 vs Opus 4.8 analysis.
- Token efficiency: GPT-5.5 uses far fewer tokens per task. On DeepSWE: 47K output vs Opus 4.8's 136K. In AA testing, GPT-5.5 is significantly leaner than Qwen's 97M token verbosity.
Qwen 3.7 Max — The Bug Fixer & Algorithm Specialist
- SWE-bench Pro 60.6% vs 58.6% (+2.0 points). The highest proprietary score on the hardest coding benchmark. Qwen correctly resolves more real-world GitHub issues end-to-end. For production bug fixing in Python repos, Qwen is measurably better — at 4× lower cost.
- LiveCodeBench 91.6% — highest of any model. For algorithm implementation, competitive programming, data structures, and graph problems, Qwen is the best model available. Combined with 97.1% HMMT and 44.5 Apex Math, Qwen is a STEM powerhouse.
- Anthropic API compatibility — drop into Claude Code with zero migration. For teams invested in the Claude ecosystem but wanting higher Pro scores at 4× lower cost, Qwen is a drop-in upgrade. No other model offers both Anthropic and OpenAI API compatibility. See our Opus 4.8 vs Qwen comparison.
- 22.9% hallucination rate vs GPT-5.5's 86%. For unattended coding agents where a silent error costs real money, Qwen's calibration is dramatically safer. The model declines to answer when uncertain rather than fabricating. This is the single most important operational difference.
- 35-hour autonomous runs, 1,000+ tool calls. Qwen can work while you sleep. Vendor-reported — not independently verified as of June 2026 — but the architectural design supports sustained multi-hour execution.
The 4× Economics (and the Verbosity Tax)
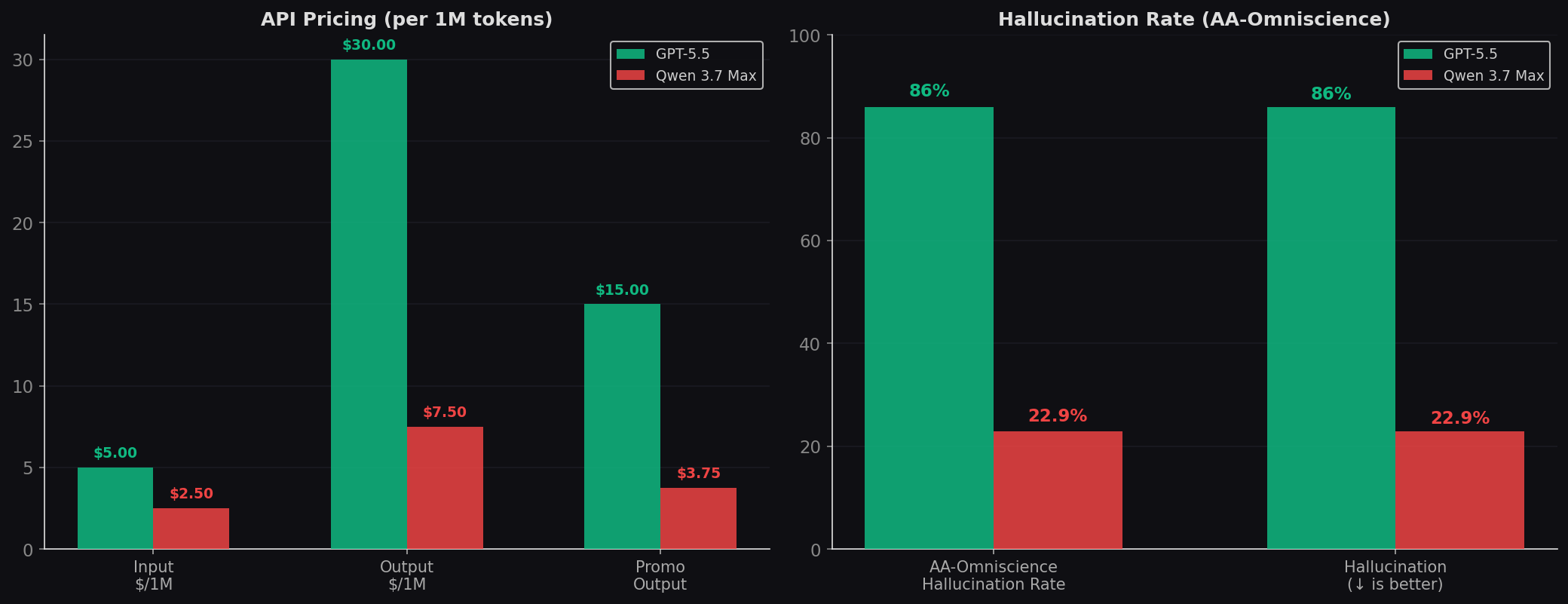
| Pricing Detail | GPT-5.5 | Qwen 3.7 Max |
|---|---|---|
| Input (list) | $5.00 / 1M | $2.50 / 1M |
| Output (list) | $30.00 / 1M | $7.50 / 1M |
| Input (with promo/cache) | $2.50 / 1M (Batch) | $1.25 / 1M (promo thru June 22) |
| Output (with promo) | $15.00 / 1M (Batch) | $3.75 / 1M |
| Cached input | — | $0.25 / 1M (90% discount) |
| Verbosity (AA Index tokens) | Lean (~30M est) | 97M (4× avg of 24M) |
| Effective cost per task | Lower (token-lean) | Higher than sticker suggests |
Headline rates: Qwen is 2× cheaper on input, 4× cheaper on output. With June promotion pricing ($1.25/$3.75), it's up to 8× cheaper than GPT-5.5's list rates.
The verbosity tax: Qwen 3.7 Max generated 97 million tokens to complete the AA Intelligence Index — 4× the 24 million token average. This verbosity applies to coding tasks: Qwen produces longer explanations, more commentary, and more thinking tokens. GPT-5.5 is dramatically leaner. On DeepSWE, GPT-5.5 uses 47K tokens vs Opus's 136K. While Qwen's DeepSWE data isn't available, the AA verbosity data suggests similar patterns. Cap max_tokens to control real costs. At effective per-task pricing, GPT-5.5's token efficiency may partially offset Qwen's per-token advantage for some workloads. See our budget models ranking.
When to Use Which
| Scenario | Use | Why |
|---|---|---|
| Python bug fixing (multi-file, real repos) | Qwen 3.7 Max | 60.6% Pro vs 58.6%. Highest proprietary score. |
| Algorithm & data structure problems | Qwen 3.7 Max | 91.6% LiveCodeBench. Best model available. |
| Claude Code / Aider / Continue users | Qwen 3.7 Max | Drop-in Anthropic API replacement. 4× cheaper. |
| Trust-sensitive unattended agents | Qwen 3.7 Max | 22.9% hallucination vs 86%. Won't silently ship broken code. |
| STEM / math-heavy coding | Qwen 3.7 Max | 97.1% HMMT. 44.5 Apex Math. Multilingual advantage. |
| Terminal/CLI/DevOps automation | GPT-5.5 | 82.7% vs 69.7% Terminal-Bench. +13 pts. |
| Codebase-scale migrations (DeepSWE) | GPT-5.5 | 70% DeepSWE. Qwen untested on this benchmark. |
| Abstract visual reasoning | GPT-5.5 | 85.0% ARC-AGI-2. Qwen score not published. |
| Cybersecurity & red teaming | GPT-5.5 | 93.3% cyber range. 81.8% CyberGym. Rated "High." |
| Multimodal coding (images, video) | GPT-5.5 | Omnimodal. Qwen is text-only. |
| Token-efficient high-volume | GPT-5.5 | Far leaner. Qwen verbosity offsets per-token savings. |
| Codex ecosystem users | GPT-5.5 | Unified agent platform. 4M weekly developers. |
Conclusion: The Challenger Wins Where It Counts
Qwen 3.7 Max vs GPT-5.5 is the most counterintuitive comparison of 2026. On the benchmark that matters most for production coding — SWE-bench Pro — the cheaper model wins. On LiveCodeBench, the cheaper model wins. On tool use (MCP-Atlas), the cheaper model wins. On hallucination calibration, the cheaper model wins dramatically. And it drops into Claude Code as a native replacement.
But GPT-5.5's strengths are structural, not marginal. The 13-point Terminal-Bench lead, 70% DeepSWE, 85% ARC-AGI-2, omnimodality, cybersecurity, Codex ecosystem, and token efficiency make it the better choice for DevOps, abstract reasoning, security, and any multimodal workflow. GPT-5.5 is the more complete platform. Qwen is the sharper coding tool.
The tiered stack: For Python bug fixing, algorithm work, and trust-sensitive agents — use Qwen at $7.50/1M. For terminal automation, security, multimodal tasks, and the Codex ecosystem — use GPT-5.5 at $30/1M. The models are complementary, not competing. At these prices, you can afford both.
20+ LLMs available. Side-by-side testing. Both models ready.
Sources: Yotta Labs — Qwen 3.7 Max Benchmarks | Overchat — Qwen vs Rivals | BenchLM — Head-to-Head | DeepSWE Leaderboard | Artificial Analysis | ARC Prize Leaderboard | Suprmind — Hallucination Rates | FelloAI — Best Models June 2026.