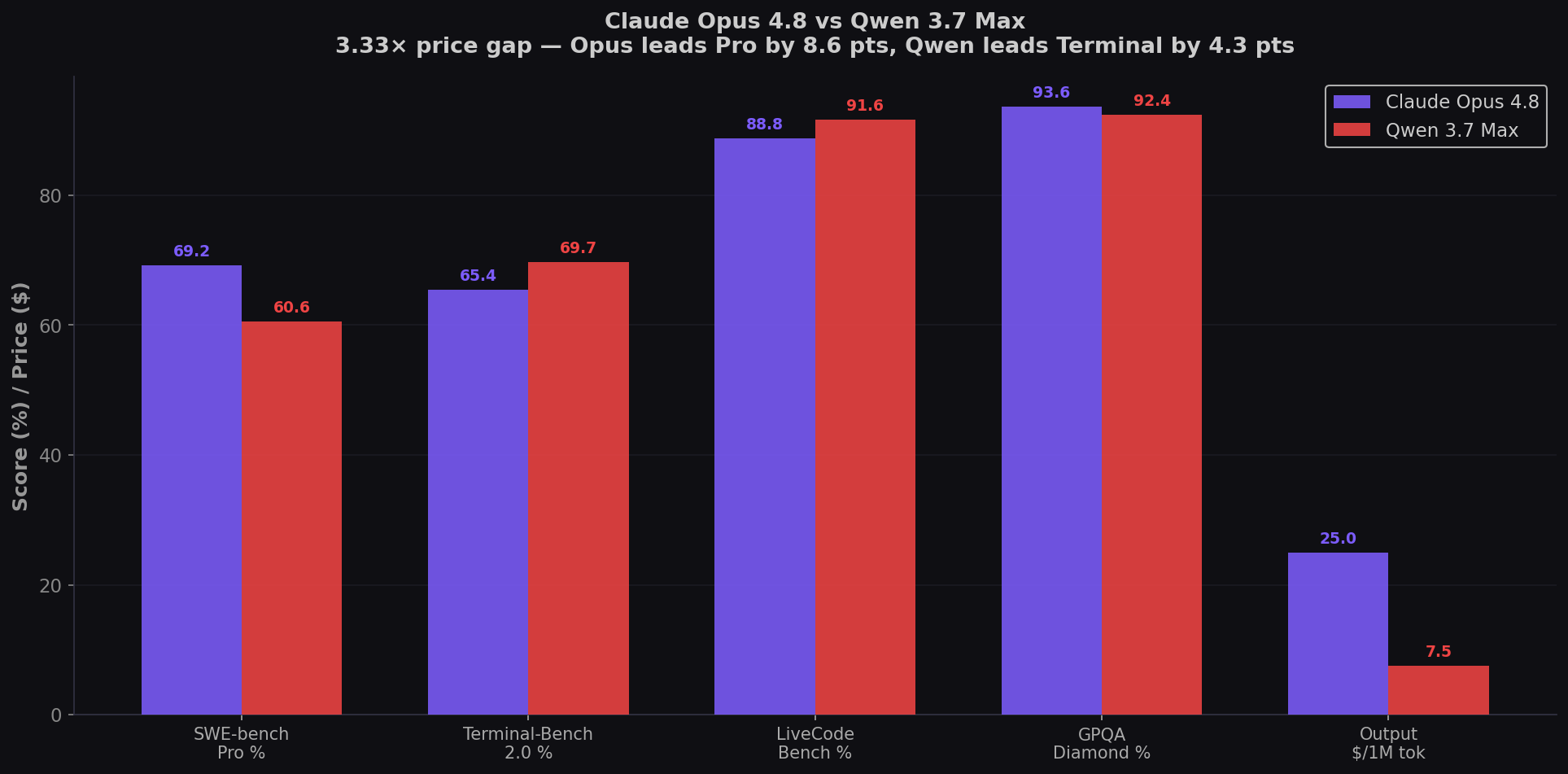
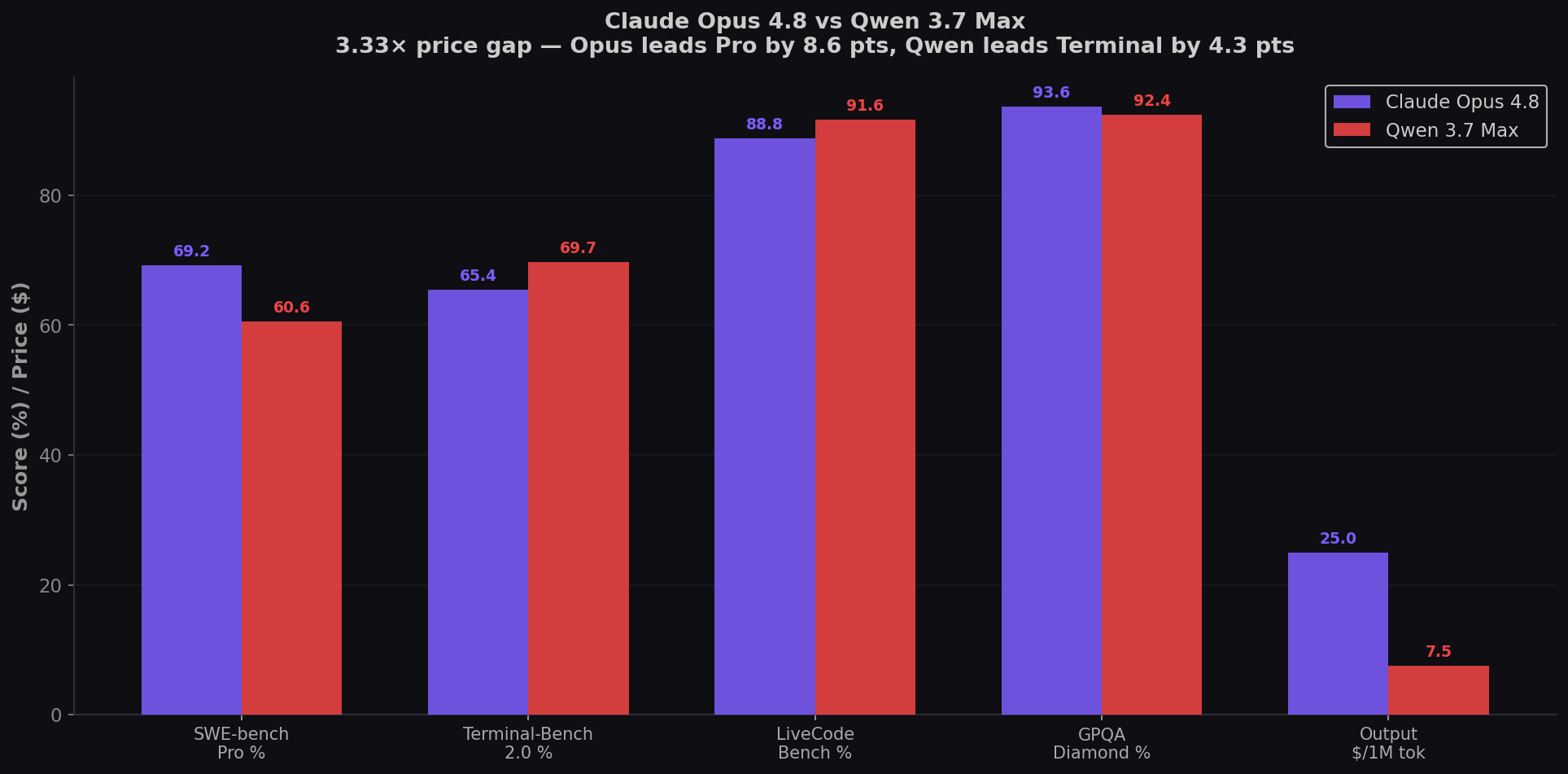
Claude Opus 4.8 is the best coding model in the world — 69.2% on SWE-bench Pro, 8.6 points ahead of Qwen 3.7 Max. It costs $25 per million output tokens. Qwen 3.7 Max costs $7.50 — a 3.33× price gap. But here's what makes this comparison unlike any other: Qwen 3.7 Max speaks the Anthropic Messages API natively. You can point your existing Claude Code setup at Qwen with just a base URL and model ID change. No code changes. The coding king vs the drop-in challenger — can Alibaba's "Agent Frontier" dethrone Anthropic's flagship? Test both on CodingFleet.
📊 Key Findings
- Opus 4.8 leads SWE-bench Pro by 8.6 points (69.2% vs 60.6%). For real-world bug fixes and multi-file refactors, Opus remains the king. The gap is structural, not marginal.
- Qwen leads Terminal-Bench (69.7% vs 65.4%) and LiveCodeBench (91.6% vs 88.8%). For CLI agent coding and algorithms, Qwen is measurably better — at 3.33× lower cost.
- Qwen 3.7 Max is a drop-in Claude Code replacement. Set
ANTHROPIC_MODEL="qwen3.7-max"and keep using Claude Code, Continue, Aider — unchanged. No model has done this before. - Opus 4.8 is ~4× more honest about its own code than Opus 4.7. Dynamic Workflows spawn hundreds of parallel subagents. Qwen counters with 35-hour autonomous runs and 1,000+ tool calls.
Compare models on your own code at CodingFleet — 20+ LLMs, side-by-side.
Benchmark Comparison
| Benchmark | Claude Opus 4.8 | Qwen 3.7 Max | Winner |
|---|---|---|---|
| SWE-bench Pro | 69.2% | 60.6% | Opus (+8.6) |
| SWE-bench Verified | 88.6% | 80.4% | Opus (+8.2) |
| SWE-bench Multilingual | 84.4% | 78.3% | Opus (+6.1) |
| Terminal-Bench 2.0 | 65.4% | 69.7% | Qwen (+4.3) |
| LiveCodeBench | 88.8% | 91.6% | Qwen (+2.8) |
| Apex Math Reasoning | 34.5 | 44.5 | Qwen (+10.0) |
| MCP-Atlas | 75.8% | 76.4% | Qwen (+0.6) |
| GPQA Diamond | 93.6% | 92.4% | Opus (+1.2) |
| OSWorld-Verified | 83.4% | — | Opus |
| Output Price /1M tokens | $25.00 | $7.50 | Qwen (3.33×) |
| Context Window | 1M | 1M | Tie |
| Max Output Tokens | 128K | 65K | Opus |
| API Compatibility | Anthropic native | Anthropic + OpenAI specs | Qwen |
Sources: Vellum; Anthropic System Card; Yotta Labs; VentureBeat. Qwen scores vendor-published vs Opus 4.6. Opus 4.8 scores used where available.
Architecture & Ecosystem
Claude Opus 4.8: Honest Workhorse with an Army of Subagents
Shipped May 28, 2026 — 42 days after Opus 4.7, the shortest gap between Opus releases. Anthropic calls it "a modest but tangible improvement." The headlining upgrade: Opus 4.8 is ~4× less likely than Opus 4.7 to let flaws in its own code pass unremarked. Simon Willison highlighted this as his favorite part — an AI lab honestly describing a release as incremental while delivering a model that catches its own mistakes. The system card notes Opus 4.8 is "more likely to flag uncertainties about its work and less likely to make unsupported claims."
The companion launch: Dynamic Workflows in Claude Code, spawning hundreds of parallel subagents with adversarial verification — one agent refutes another's findings before results reach the user. Workflows save and resume, so interrupted jobs don't restart. Anthropic's exemplar: a codebase-scale migration across hundreds of thousands of lines, from kickoff to merge. Other improvements: mid-conversation system messages (update instructions without breaking prompt cache), effort control in claude.ai, lower prompt-cache threshold (1,024 tokens — short RAG patterns now hit cache), and Fast mode (2.5× faster, $10/$50, 3× cheaper than previous Fast tier). 84% Online-Mind2Web — best-in-class browser agent. First model to break 10% on Legal Agent Benchmark all-pass. Available on Anthropic API, Bedrock, Vertex AI, and Microsoft Foundry.
Qwen 3.7 Max: The Agent Frontier That Speaks Claude's Language
Launched May 19, 2026 — nine days before Opus 4.8. Built for long-horizon autonomous execution with up to 35 hours of continuous operation and 1,000+ sequential tool calls. The architecture emphasizes "cross-harness generalization" — working across diverse agent frameworks rather than optimizing for one. The headline feature: native Anthropic API protocol support at the endpoint level. Not a shim or translation layer. Qwen speaks the Anthropic Messages API natively. Set ANTHROPIC_MODEL="qwen3.7-max", point at DashScope or OpenRouter, and Claude Code, Continue, Aider, or OpenClaw work unchanged. Qwen also supports the OpenAI API spec for dual-ecosystem compatibility.
On Kernel Bench L3: 1.98× median kernel speedup with 96% win rate — competitive with Opus 4.6 on low-level optimization. AA Intelligence Index: 56.6 (fifth overall, highest-ranked Chinese model at launch, within noise of Opus 4.7's 57.3). One notable limitation: a 52% abstention rate on factual retrieval — Qwen declines to answer factual questions it's uncertain about roughly half the time. This reduces hallucinations but limits knowledge-work utility. For coding tasks grounded in a codebase (rather than external knowledge), this matters less. For research-heavy coding, Opus's lower abstention rate is preferable.
Where Each Model Wins at Coding
Claude Opus 4.8 — The Bug Fixer
- 8.6-point SWE-bench Pro lead. Fixes ~7 of 10 real-world bugs vs Qwen's ~6. On 4+ file changes with 100+ lines, the gap widens — Opus tracks cascading dependency changes that stall other models.
- 4× honesty improvement. Fewer "looks right but secretly broken" outputs. The model flags its own uncertainties. For production debugging where missed bugs cost real money, this compounds.
- Dynamic Workflows. Plan → spawn hundreds of parallel subagents → verify adversarially → merge. No other model has a comparable orchestration layer. For monorepos and multi-service architectures, this transcends benchmarks.
- 128K max output. Twice Qwen's 65K. For generating entire files, documentation, or test suites in one pass. 84% Online-Mind2Web for browser-based coding. Best-in-class computer use (83.4% OSWorld-Verified).
Qwen 3.7 Max — The Agent Operator
- Terminal-Bench leader (69.7% vs 65.4%). For CLI agent coding — read repo, run commands, interpret output, iterate — Qwen is better and cheaper. The economics compound: more iterations, more fixes, lower total cost.
- LiveCodeBench leader (91.6% vs 88.8%). For algorithm implementation, competitive programming, and data structures. Combined with Terminal-Bench leadership, Qwen excels at autonomous coding that prioritizes execution.
- Anthropic API compatibility. Drop into Claude Code with zero migration. First model to offer this. For teams that love the Claude ecosystem but want higher Terminal-Bench scores at lower cost. See our Qwen 3.7 Max vs GPT-5.5.
- Apex Math +10 points (44.5 vs 34.5). For scientific computing, ML engineering, quantitative development. 35-hour autonomous runs with 1,000+ tool calls — vendor-reported, not independently verified as of June 2026.
The Drop-In Decision
| If your workflow is... | Stay with Opus 4.8 | Try Qwen 3.7 Max |
|---|---|---|
| Production bug fixing | ✓ 8.6-point Pro lead | Good, but Opus catches more |
| Codebase-scale migrations | ✓ Dynamic Workflows unique | 35-hr runs but no parallel subagents |
| Trust-sensitive code | ✓ 4× honesty improvement | 52% abstention is a feature |
| CLI agent coding | Solid at 65.4% | ✓ Leads at 69.7% |
| Algorithm & data structures | Strong at 88.8% | ✓ Leads at 91.6% |
| Claude Code/Aider/Continue | Native, full-featured | ✓ Drop-in — 3.33× cheaper |
| STEM/scientific computing | Solid at 34.5 Apex | ✓ Dominates at 44.5 (+10 pts) |
| Browser-based coding | ✓ 84% Online-Mind2Web | No comparable score |
The 3.33× Economics
- Headline rates: Qwen $7.50 vs Opus $25.00 per 1M output — 3.33× cheaper on paper.
- Verbosity caveat: Qwen can be verbose on long sessions. Production testing shows verbosity can push effective costs to 3-4× headline rates, potentially approaching Opus pricing. Cap
max_tokensto control this. - Cache discounts: Opus 4.8's lower prompt-cache threshold (1,024 tokens) means short RAG patterns now hit cache. Qwen offers 90% cache read discounts on DashScope.
- Fast mode: Opus 4.8 Fast mode runs 2.5× faster at $10/$50 per 1M. For latency-sensitive coding, Fast mode may be the better comparison point against Qwen's default speed.
Practical strategy: Use Qwen for high-volume, cost-sensitive coding (cap max_tokens). Fall back to Opus for production debugging, migrations, and trust-sensitive work. This mirrors the tiered approach in our heavy user's guide.
Verdict: The King Keeps His Crown — But the Court Is Shrinking
Claude Opus 4.8 remains the best coding model in the world. The 8.6-point SWE-bench Pro lead is structural. The 4× honesty improvement is practical. Dynamic Workflows are unique. For production debugging, codebase migrations, and trust-sensitive code, Opus is worth the premium.
But Qwen 3.7 Max wins enough battles to matter: Terminal-Bench, LiveCodeBench, Apex Math, MCP-Atlas. The Anthropic API compatibility — drop Qwen into Claude Code with zero migration — is a strategic advantage no other model offers. For CLI agent coding, algorithm work, and STEM-heavy development, Qwen is measurably better at lower cost.
The real story: The gap between the coding king and challengers is closing faster than benchmarks suggest. Eight months ago, no model was within 15 points of Claude on Pro. Today, Qwen is within 8.6 — and leads on agentic and algorithmic benchmarks. Opus still wears the crown. But for the first time, there's a model you can drop into your Claude Code workflow that beats it on enough dimensions to justify the switch. Test both on your actual code.
20+ LLMs available. Side-by-side testing. Both models ready.
Sources: Vellum — Opus 4.8 Benchmarks | Anthropic System Card | Simon Willison Review | Yotta Labs — Qwen 3.7 Max | VentureBeat | ZenVanriel Drop-In Guide | Overchat.