📊 TL;DR — Key Findings
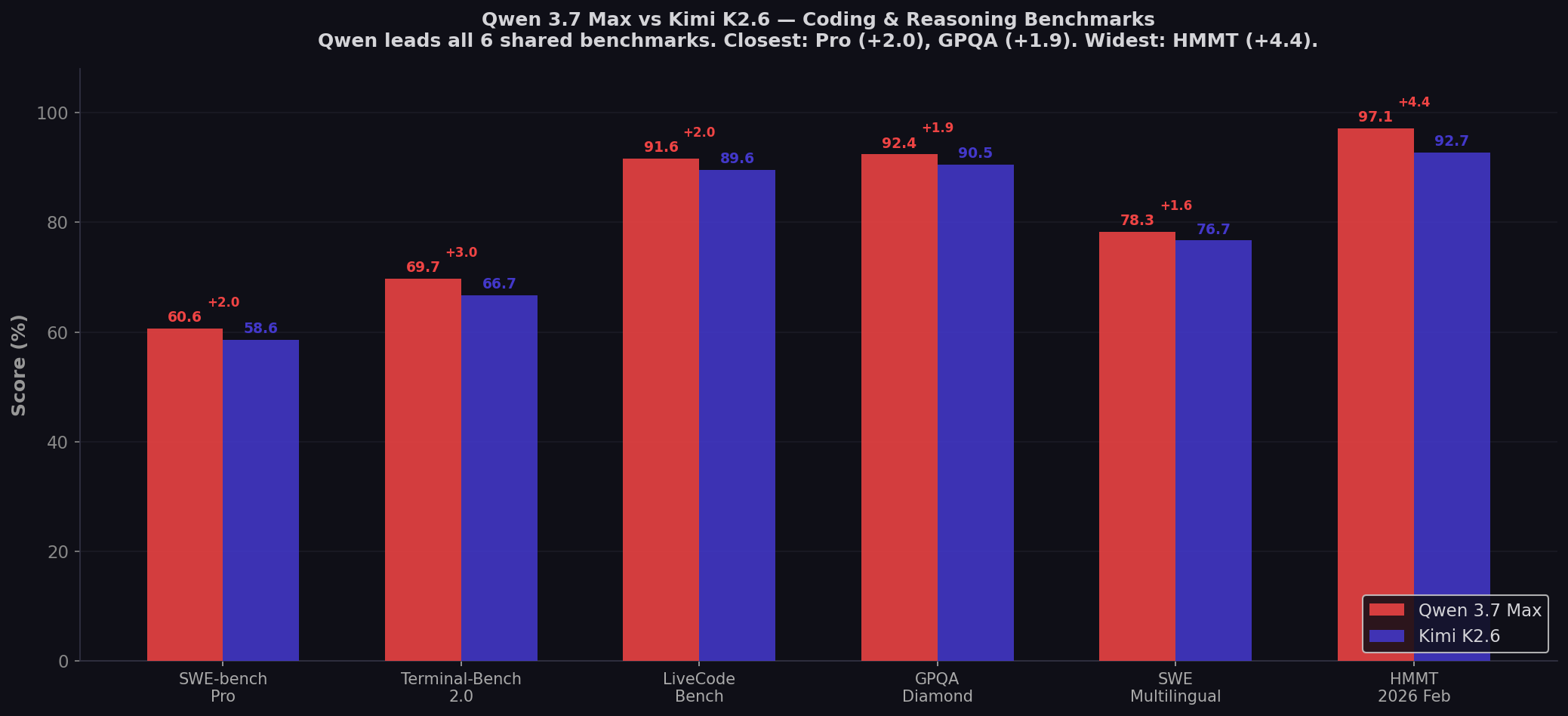
- Qwen leads all 6 shared benchmarks: Pro (+2.0), Terminal (+3.0), LiveCode (+2.0), GPQA (+1.9), Multilingual (+1.6), HMMT (+4.4). Clean sweep.
- Kimi's HLE w/tools: 54.0% — Qwen doesn't publish HLE w/tools (only no-tools 41.4%). On the hardest tool-using exam, Kimi may actually lead.
- Agent Swarm vs Agent Frontier: Kimi deploys 300 sub-agents synchronously. Qwen runs 35-hour autonomous sessions. Different approaches to the same goal.
- Qwen is Anthropic API compatible: Drop-in Claude Code replacement. Kimi is OpenAI + Anthropic compatible with open weights on HuggingFace.
- 1.9× price gap: Qwen $7.50/1M output (promo $3.75 until June 22). Kimi $4.00/1M. Both cheaper than GPT-5.5 ($30) and Opus 4.8 ($25).
Try both models side-by-side on your own code at CodingFleet →
Benchmark Comparison
| Benchmark | Qwen 3.7 Max | Kimi K2.6 | Winner |
|---|---|---|---|
| SWE-bench Pro ★ | 60.6% | 58.6% | Qwen (+2.0) |
| SWE-bench Verified ⚠️ | 80.4% | 80.2% | Qwen (+0.2 — virtual tie) |
| Terminal-Bench 2.0 | 69.7% | 66.7% | Qwen (+3.0) |
| LiveCodeBench | 91.6% | 89.6% | Qwen (+2.0) |
| GPQA Diamond | 92.4% | 90.5% | Qwen (+1.9) |
| SWE-bench Multilingual | 78.3% | 76.7% | Qwen (+1.6) |
| HMMT 2026 Feb | 97.1% | 92.7% | Qwen (+4.4) |
| HLE (no tools) | 41.4% | — (not published) | Qwen — Kimi publishes HLE w/tools only |
| HLE (with tools) | — (not published) | 54.0% | Kimi — Qwen publishes no-tools only |
| BrowseComp (Agent Swarm) | — | 86.3% | Kimi — not a shared benchmark |
| SciCode | 53.5% | — | Qwen — not published by Kimi |
| MCP-Atlas | 76.4% | — | Qwen — not published by Kimi |
| OSWorld-Verified | — | 73.1% | Kimi — not published by Qwen |
| MMLU-Pro | 89.6 | 79.4 | Qwen (+10.2) |
| Output Price /1M tok | $7.50 (promo $3.75) | $4.00 | Kimi (1.9× cheaper) |
Sources: Qwen official blog | DeepInfra Kimi K2.6 analysis | Lushbinary Kimi guide | Yotta Labs Qwen analysis | Amit Ray Qwen benchmarks. All scores vendor-reported except where noted. ⚠️ Verified deprecated by OpenAI Feb 2026.

The Shared Benchmarks: A Clean Sweep (But Not a Knockout)
Qwen 3.7 Max leads on every benchmark where both models publish scores. But the margins tell a more nuanced story:
- SWE-bench Pro (+2.0): Within harness variation. Different scaffolds, different prompts — a 2-point gap on Pro is real but not decisive.
- Terminal-Bench (+3.0): Both models use the Terminus-2 harness — making this the cleanest apples-to-apples comparison. Qwen's lead here is meaningful.
- HMMT (+4.4): The widest gap on any shared benchmark. Qwen's math capabilities consistently outscore Kimi across multiple math benchmarks (HMMT +4.4, IMOAnswerBench 90.0, Apex 44.5).
- LiveCodeBench (+2.0) and GPQA (+1.9): Both models cluster in the 90-92% range. Functionally equivalent for most practical purposes.
The HLE Asymmetry: Two Different Tests
This is where the comparison gets tricky. Qwen publishes HLE (no tools): 41.4%. Kimi publishes HLE (with tools): 54.0%. These are different tests — tools access adds significant capability on HLE. Kimi's 54.0% with tools is one of the highest published HLE scores on record, ahead of GPT-5.4 (52.1%) and Claude Opus 4.6 (53.0%). Qwen's 41.4% without tools is competitive with GPT-5.5 (41.4%) — a virtual tie. But you can't directly compare the two numbers. The honest read: Kimi may lead on HLE with tool access, but we don't have a shared baseline to confirm.
The BrowseComp Gap: Kimi's Secret Weapon
Kimi K2.6's Agent Swarm mode scores 86.3% on BrowseComp — up from 78.4% on K2.5 and ahead of GPT-5.4's 82.7%. Qwen hasn't published BrowseComp scores. For web-browsing agents that need to search, navigate, and synthesize information across multiple pages, Kimi's Agent Swarm architecture provides a structural advantage that Qwen's sequential tool-calling can't match.
Architecture & Ecosystem
| Feature | Qwen 3.7 Max | Kimi K2.6 |
|---|---|---|
| Release Date | May 21, 2026 | April 20, 2026 |
| Developer | Alibaba (Qwen Team) | Moonshot AI |
| Model Class | Proprietary Frontier | Open-Weight (Modified MIT) |
| Context Window | 1,000,000 tokens | 262,144 tokens |
| Input Modalities | Text only | Text + Image |
| Weights Available | No | Yes — HuggingFace |
| API Compatibility | Anthropic API (drop-in Claude Code replacement) | OpenAI + Anthropic compatible |
| Agent Architecture | Sequential 35-hour runs, 1000+ tool calls | Agent Swarm: 300 sub-agents, 4,000 steps |
| Max Autonomous Runtime | 35 hours (vendor claim) | 12 hours (vendor claim) |
| Kernel Bench L3 | 96% win rate, 1.98× speedup | — (not published) |
| AA Intelligence Index | 56.6 (#5) | ~54 (Cerebras comparison) |
Why Qwen 3.7 Max Wins on Raw Benchmarks
Qwen 3.7 Max is Alibaba's "Agent Frontier" — designed explicitly for long-horizon autonomous coding. The model was trained to sustain coherence across 35-hour sessions with 1,000+ sequential tool calls without degrading. The architecture optimizes for sustained reasoning depth: strong performance on math benchmarks (HMMT 97.1%, IMOAnswerBench 90.0%, Apex 44.5) translates to better multi-step bug diagnosis, and the 1M context window handles full codebase analysis. The Anthropic API compatibility is a strategic masterstroke — Qwen 3.7 Max drops into Claude Code, OpenClaw, and Qwen Code as a native replacement with zero harness changes. A Reddit r/singularity thread on the 60.6% Pro score generated significant discussion, with developers noting Qwen's strength on real engineering tasks versus "benchmaxxed" competitors.
Why Kimi K2.6 Wins on Agentic Freedom
Kimi K2.6's defining feature is Agent Swarm — the ability to decompose complex tasks into hundreds of parallel, domain-specialized sub-agents and coordinate them across thousands of steps. This architecture shows its strength on BrowseComp Agent Swarm (86.3%), DeepSearchQA (92.5%), and HLE w/tools (54.0%). But the real differentiator is openness: Kimi K2.6 weights are available on HuggingFace under a Modified MIT license, with native INT4 quantization, a 160K-token vocabulary, and compatibility with vLLM, SGLang, and KTransformers. For teams that want full control — fine-tuning, self-hosting, air-gapped deployment — Kimi is the only option in this comparison. The 256K context window is a limitation compared to Qwen's 1M, but for most agentic coding tasks, it's sufficient.
Pricing: Both Affordable, Different Tradeoffs
| Pricing Tier | Qwen 3.7 Max | Kimi K2.6 | Gap |
|---|---|---|---|
| Input /1M tok | $2.50 (promo $1.25) | $0.95 | 1.3–2.6× |
| Output /1M tok | $7.50 (promo $3.75) | $4.00 | 1.1–1.9× |
| Cached Input /1M tok | $0.25 | $0.15 | 1.7× |
| Self-Hosting Cost | Not possible (proprietary) | Open-weight — run locally | ∞ |
| License | Proprietary | Modified MIT | — |
Sources: OfoxAI Qwen pricing | DeepInfra Kimi pricing. Qwen promo pricing expires June 22, 2026.
At 100M output tokens/month: Qwen costs $375–$750 vs Kimi at $400. The gap is narrow enough that pricing shouldn't drive the decision — both are in the same affordability tier. For self-hosting, Kimi is the only option. For maximum context (1M vs 256K), Qwen is the only option.
Which Model Should You Use?
| Use Case | Winner | Why |
|---|---|---|
| Bug fixing / real GitHub issues | Qwen ✅ | +2.0 SWE-bench Pro — highest proprietary score on the benchmark |
| Terminal / CLI / DevOps | Qwen ✅ | +3.0 Terminal-Bench — clean apples-to-apples harness comparison |
| Competitive programming | Qwen ✅ | +2.0 LiveCodeBench, +4.4 HMMT — consistent math edge |
| Scientific reasoning | Qwen ✅ | +1.9 GPQA, +10.2 MMLU-Pro — but Kimi not far behind |
| Multi-file codebase work | Qwen ✅ | 1M context window vs 256K — 4× more codebase in memory |
| Web browsing agents | Kimi ✅ | 86.3% BrowseComp Agent Swarm — structural advantage |
| Self-hosting / air-gapped | Kimi ✅ | Open-weight on HuggingFace. Qwen is proprietary only. |
| Parallel agent orchestration | Kimi ✅ | 300 sub-agents, 4,000 steps synchronized — unique capability |
| Claude Code replacement | Qwen ✅ | Native Anthropic API — drop-in, zero harness changes |
| Budget at scale | ⚖️ Near Tie | $375–$750 vs $400/mo at 100M output — same tier |
Conclusion: The Proprietary Agent vs The Open-Weight Swarm
Qwen 3.7 Max is the better model on raw benchmarks — it leads every shared comparison and holds the #1 proprietary spot on SWE-bench Pro at 60.6%. If you're choosing based on benchmark scores alone, the decision is clear. Qwen's 1M context window, 35-hour autonomous runs, Anthropic API compatibility, and stronger math performance make it the safer pick for most coding workflows.
But Kimi K2.6 isn't competing on the same terms. Its Agent Swarm architecture, 86.3% BrowseComp, open weights on HuggingFace, and self-hosting capability address a fundamentally different set of needs. For teams building web-browsing agents, orchestrating parallel sub-agent swarms, or requiring air-gapped deployment, Kimi offers capabilities Qwen doesn't match.
The practical answer: Qwen for most coding tasks. Kimi for agent orchestration and deployment freedom. Both are excellent and both cost less than half of what GPT-5.5 charges. The Chinese AI labs are no longer catching up — they're setting the pace.
20+ LLMs available on CodingFleet. Test Qwen 3.7 Max and Kimi K2.6 side-by-side on your own code.
📚 Sources & Links
- Qwen official blog — Qwen 3.7 Max announcement
- DeepInfra — Kimi K2.6 API Benchmarks
- Lushbinary — Kimi K2.6 Developer Guide
- Yotta Labs — Qwen 3.7 Max vs Claude Opus 4.6
- Amit Ray — Qwen 3.7 Max Benchmark Analysis
- OfoxAI — Qwen 3.7 Plus vs Max comparison
- Cerebras — Kimi K2.6 vs Gemini 3.5 Flash speed comparison
- Reddit r/singularity — Qwen 3.7 Max 60.6% Pro discussion
- Verdent AI — Kimi K2.6 Developer Guide
- Kimi K2.5 — Kimi K2.6 Benchmarks vs Competitors
📖 Read This Next
- Qwen 3.7 Max vs MiniMax M3 — proprietary agent vs open-weight multimodal
- MiniMax M3 vs GPT-5.5 — open-weight beats proprietary on Pro at 25× less
- Kimi K2.6 vs MiniMax M3 — the open-weight crown (0.4 pts apart)
- SWE-bench Pro Live Leaderboard — every model ranked
- AI Model Pricing Calculator — compare costs at your token volume